Поиск с предпочтением: эвристический поиск
Глава 12. ПОИСК С ПРЕДПОЧТЕНИЕМ: ЭВРИСТИЧЕСКИЙ ПОИСК
Поиск в графах при решении задач, как правило, невозможен без решения проблемы комбинаторной сложности, возникающей из-за быстрого роста числа альтернатив. Эффективным средством борьбы с этим служит эвристический поиск.
Один из путей использования эвристической информации о задаче - это получение численных эвристических оценок для вершин пространства состояний. Оценка вершины указывает нам, насколько данная вершина перспективна с точки зрения достижения цели. Идея состоит в том, чтобы всегда продолжать поиск, начиная с наиболее перспективной вершины, выбранной из всего множества кандидатов. Именно на этом принципе основана программа поиска с предпочтением, описанная в данной главе.
double_line();Литература
Литература
Программа поиска с предпочтением, представленная в настоящей главе, - это один из многих вариантов похожих друг на друга программ, из которых А*-алгоритм наиболее популярен. Общее описание А*-алгоритма можно найти в книгах Nillson (1971, 1980) или Winston (1984). Теорема о допустимости впервые доказана авторами статьи Hart, Nilsson, and Raphael (1968). Превосходное и строгое изложение многих разновидностей алгоритмов поиска с предпочтением и связанных с ними математических результатов дано в книге Pearl (1984). В статье Doran and Michie (1966) впервые изложен поиск с предпочтением, управляемый оценкой расстояния до цели.
Головоломка "игра в восемь" использовалась многими исследователями в области искусственного интеллекта в качестве тестовой задачи при изучении эвристических принципов (см., например, Doran and Michie (1966), Michie and Ross (1970) и Gaschnig (1979) ).
Задача планирования, рассмотренная в настоящей главе, также как и многие ее разновидности, возникает во многих прикладных областях в ситуации, когда необходимо спланировать обслуживание запросов на ресурсы. Один из примеров - операционные системы вычислительных машин. Задача планирования со ссылкой на это конкретное приложение изложена в книге Coffman and Denning (1973).
Найти хорошую эвристику - дело важное и трудное, поэтому изучение эвристик - одна из центральных тем в искусственном интеллекте. Существуют, однако, некоторые границы, за которые невозможно выйти, двигаясь в направлении улучшения качества эвристик. Казалось бы, все, что необходимо для эффективного решения комбинаторной задачи - это найти мощную эвристику. Однако есть задачи (в том числе многие задачи планирования), для которых не существует универсальной эвристики, обеспечивающей во всех случаях как эффективность, так и допустимость. Многие теоретические результаты, имеющие отношение к этому ограничению, собраны в работе Garey and Johnson (1979).
Coffman E.G. and Denning P.J. (1973). Operating Systems Theory. Prentice-Hall.
Doran J. and Michie D. (1966). Experiments with the graph traverser program. Proc. Royal Socieiy of London 294(A): 235-259.
Garey M. R. and Johnson D. S. (1979). Computers and Intractability. W. H. Freeman. [Имеется перевод: Гэри M., Джонсон Д. С- Вычислительные машины и труднорешаемые задачи.- M.: Мир, 1982.]
Gaschnig J. (1979). Performance measurement and analysis of certain search algorithms. Carnegie-Mellon University: Computer Science Department-Technical Report CMU-CS-79-124 (Ph. D. Thesis).
Hart P.E., Nilsson N.J. and Raphael B. (1968). A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Sciences and Cybernetics SSC-4(2):100-107
Michie D. and Ross R. (1970). Experiments with the adaptive graph traverser. Machine Intelligence 5: 301-308.
Nilsson N.J. (1971). Problem - Solving Methods in Artificial Intelligence. McGraw-Hill. [Имеется перевод: Нильсон H. Искусственный интеллект. Методы поиска решений. - M: Мир, 1973.]
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; also Springer-Verlag.
Pearl J. (1984). Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley.
Winston P. H. (1984). Artificial Intelligence (second edition). Addison-Wesley. [Имеется перевод первого издания: Уинстон П. Искусственный интеллект. - M.: Мир, 1980.]
Отношение расширить: расширение дерева дер до тех
Отношение расширить: расширение дерева Дер до тех
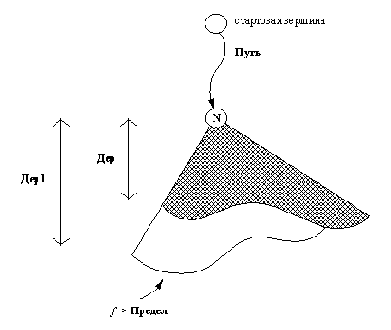
пор, пока f-оценка не превзойдет Предел, приводит к дереву Дер1.
которое, возможно, меньшее значение Предел1, зависящее от f-оценок других конкурирующих поддеревьев ДД. Тем самым гарантируется, что "растущее" дерево - это всегда наиболее перспективное дерево, а переключение активности между поддеревьями происходит в соответствии с их f-оценками. После того, как самый перспективный кандидат расширен, вспомогательная процедура продолжить решает, что делать дальше, а это зависит от типа результата, полученного после расширения. Если найдено решение, то оно и выдается, в противном случае процесс расширения деревьев продолжается.
Предложение, относящееся к случаю
Дер = л( В, F/G)
порождает всех преемников вершины В вместе со стоимостями дуг, ведущих в них из В. Процедура преемспис формирует список поддеревьев, соответствующих вершинам-преемникам, а также вычисляет их g- и f-оценки, как показано на рис. 12.5. Затем полученное таким образом дерево подвергается расширению с учетом ограничения Предел. Если преемников нет, то переменной ЕстьРеш придается значение "никогда" и в результате лист В покидается навсегда.
Другие отношения:
после( В, В1, С) В1 - преемник вершины В; С - стоимость дуги, ведущей из В в В1.
h( В, Н)
Н - эвристическая оценка стоимости оптимального пути
из вершины В в целевую вершину.
макс_f( Fмакс)
Fмакс - некоторое значение, задаваемое пользователем,
про которое известно, что оно больше любой возможной f-оценки.
В следующих разделах мы покажем на примерах, как можно применить нашу программу поиска с предпочтением к конкретным задачам. А сейчас сделаем несколько заключительных замечаний общего характера относительно этой программы. Мы реализовали один из вариантов эвристического алгоритма, известного в литературе как А*-алгоритм (ссылки на литературу см. в конце главы). А*-алгоритм привлек внимание многих исследователей. Здесь мы приведем один важный результат, полученный в результате математического анализа А*-алгоритма:
Отношения для задачи планирования. Даны также
Отношения для задачи планирования. Даны также
определения отношений для конкретной задачи планирования с
рис. 12.8: граф предшествования и исходный (пустой) план в
качестве стартовой вершины.
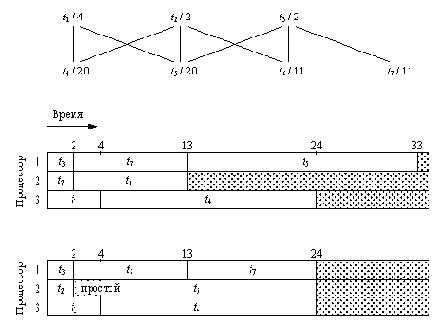
Планирование прохождения задач...
Планирование прохождения задач в многопроцессорной системе для 7 задач и 3 процессоров. Вверху показано предшествование задач и величины продолжительности их решения. Например, задача t5 требует 20 квантов времени, причем ее выполнение может начаться только после того, как будет завершено решение трех других задач t1, t2 и t3. Показано два корректных плана: оптимальный план с временем окончания 24 и субоптимальный - с временем окончания 33. В данной задаче любой оптимальный план должен содержать время простоя.
Coffman/ Denning, Operating Systems Theory, © 1973, p.86. Приведено с разрешения Prentice-Hall, Englewood Cliffs, New Jersey.
одну за другой, пока все задачи не будут исчерпаны. Как правило, на каждом шагу мы будем иметь несколько различных возможностей, поскольку окажется, что одновременно несколько задач-кандидатов ждут своего выполнения. Таким образом, для составления плана потребуется перебор. Мы можем сформулировать задачу планирования в терминах пространства состояний следующим образом: состояния - это частично составленные планы; преемник частичного плана получается включением в план еще одной задачи; другая возможность - оставить процессор, только что закончивший свою задачу, в состоянии простоя; стартовая вершина - пустой план; любой план, содержащий все задачи, - целевое состояние; стоимость решения (подлежащая минимизации) -время окончания целевого плана; стоимость перехода от одного частичного плана к другому равна К2 - К1 где К1, К2 - времена окончания этих планов.
Этот грубый сценарий требует некоторых уточнений. Во-первых, мы решим заполнять план в порядке возрастания времен, так что задачи будут включаться в него слева направо. Кроме того, при добавлении каждой задачи следует проверять, выполнены ли ограничения, связанные с отношениями предшествования. Далее, не имеет смысла оставлять процессор бездействующим на неопределенное время, если имеются задачи, ждущие своего запуска. Поэтому мы разрешим процессору простаивать только до того момента, когда какой-нибудь другой процессор завершит выполнение своей задачи. В этот момент мы еще раз вернемся к свободному процессору с тем, чтобы рассмотреть возможность приписывания ему какой-нибудь задачи.
Теперь нам необходимо принять решение относительно представления проблемных ситуаций, т.е. частичных планов. Нам понадобится следующая информация:
(1) список ждущих задач вместе с их временами выполнения;
(2) текущая загрузка процессоров задачами.
Добавим также для удобства программирования
(3) время окончания (частичного) плана, т.е. самое последнее время окончания задачи среди всех задач, приписанных процессорам.
Список ждущих задач вместе с временами их выполнения будем представлять в программе при помощи списка вида
[ Задача1/Т1, Задача2/Т2, ... ]
Текущую загрузку процессоров будем представлять как список решаемых задач, т. е. список пар вида
[ Задача/ВремяОкончания ]
В списке m таких пар, по одной на каждый процессор. Новая задача будет добавляться к плану в момент, когда закончится первая задача из этого списка. В связи с этим мы должны постоянно поддерживать упорядоченность списка загрузки по возрастанию времен окончания. Эти три компоненты частичного плана (ждущие задачи, текущая загрузка и время окончания плана) будут объединены в одно выражение вида
Ждущие * Активные * ВремяОкончания
Кроме этой информации у нас есть ограничения, налагаемые отношениями предшествования, которые в программе будут выражены в форме отношения
предш( ЗадачаX, ЗадачаY)
Рассмотрим теперь эвристическую оценку. Мы будем использовать довольно примитивную эвристическую функцию, которая не сможет обеспечить высокую эффективность управления алгоритмом поиска. Эта функция допустима, так что получение оптимального плана будет гарантировано. Однако следует заметить, что для решения более серьезных задач планирования потребуется более мощная эвристика.
Нашей эвристической функцией будет оптимистическая оценка времени окончания частичного плана с учетом всех ждущих задач. Оптимистическая оценка будет вычисляться в предположении, что два из ограничений, налагаемых на действительно корректный план, ослаблены:
(1) не учитываются отношения предшествования;
(2) делается (не реальное) допущение, что возможно распределенное выполнение задачи одновременно на нескольких процессорах, причем сумма времен выполнения задачи на процессорах равна исходному времени выполнения этой задачи на одном процессоре.
Пусть времена выполнения ждущих задач равны Т1, Т2, ..., а времена окончания задач, выполняемых на процессорах - К1, К2, ... . Тогда оптимистическая оценка времени ОбщКон окончания всех активных к настоящему моменту, а также всех ждущих задач имеет вид:
Поиск c предпочтением применительно к головоломке "игра в восемь"
Поиск c предпочтением применительно к головоломке "игра в восемь"
Если мы хотим применить программу поиска с предпочтением, показанную на рис. 12.3, к какой-нибудь задаче, мы должны добавить к нашей программе отношения, отражающие специфику этой конкретной задачи. Эти отношения определяют саму задачу ("правила игры"), а также вносят в алгоритм эвристическую информацию о методе ее решения. Эвристическая информация задается в форме эвристической функции.
line();/* Процедуры, отражающие специфику головоломки
"игра в восемь".
Текущая ситуация представлена списком положений фишек;
первый элемент списка соответствует пустой клетке.
Пример:
|
Эта позиция представляется так: [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] |
"Пусто" можно перемещать в любую соседнюю клетку,
т.е. "Пусто" меняется местами со своим соседом.
*/
после( [Пусто | Спис], [Фшк | Спис1], 1) :-
% Стоимости всех дуг равны 1
перест( Пусто, Фшк, Спис, Спис1).
% Переставив Пусто и Фшк, получаем СПИС1
перест( П, Ф, [Ф | С], [П | С] ) :-
расст( П, Ф, 1).
перест( П, Ф, [Ф1 | С], [Ф1 | С1] ) :-
перест( П, Ф, С, С1).
расст( X/Y, X1/Y1, Р) :-
% Манхеттеновское расстояние между клетками
расст1( X, X1, Рх),
расст1( Y, Y1, Ру),
Р is Рх + Py.
расст1( А, В, Р) :-
Р is А-В, Р >= 0, ! ;
Р is B-A.
% Эвристическая оценка h равна сумме расстояний фишек
% от их "целевых" клеток плюс "степень упорядоченности",
% умноженная на 3
h( [ Пусто | Спис], H) :-
цель( [Пусто1 | Цспис] ),
сумрасст( Спис, ЦСпис, Р),
упоряд( Спис, Уп),
Н is Р + 3*Уп.
сумрасст( [ ], [ ], 0).
сумрасст( [Ф | С], [Ф1 | С1], Р) :-
расст( Ф, Ф1, Р1),
сумрасст( С, Cl, P2),
Р is P1 + Р2.
упоряд( [Первый | С], Уп) :-
упоряд( [Первый | С], Первый, Уп).
упоряд( [Ф1, Ф2 | С], Первый, Уп) :-
очки( Ф1, Ф2, Уп1),
упоряд( [Ф2 | С], Первый, Уп2),
Уп is Уп1 + Уп2.
упоряд( [Последний], Первый, Уп) :-
очки( Последний, Первый, Уп).
очки( 2/2, _, 1) :- !. % Фишка в центре - 1 очко
очки( 1/3, 2/3, 0) :- !.
% Правильная последовательность - 0 очков
очки( 2/3, 3/3, 0) :- !.
очки( 3/3, 3/2, 0) :- !.
очки( 3/2, 3/1, 0) :- !.
очки( 3/1, 2/1, 0) :- !.
очки( 2/1, 1/1, 0) :- !.
очки( 1/1, 1/2, 0) :- !.
очки( 1/2, 1/3, 0) :- !.
очки( _, _, 2). % Неправильная последовательность
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
% Стартовые позиции для трех головоломок
старт1( [2/2, 1/3, 3/2, 2/3, 3/3, 3/1, 2/1, 1/1, 1/2] ).
% Требуется для решения 4 шага
старт2( [2/1, 1/2, 1/3, 3/3, 3/2, 3/1, 2/2, 1/1, 2/3] ).
% 5 шагов
старт3( [2/2, 2/3, 1/3, 3/1, 1/2, 2/1, 3/3, 1/1, 3/2] ).
% 18 шагов
% Отображение решающего пути в виде списка позиций на доске
показреш( [ ]).
показреш( [ Поз | Спис] :-
показреш( Спис),
nl, write( '---'),
показпоз( Поз).
% Отображение позиции на доске
показпоз( [S0, S1, S2, S3, S4, S5, S6, S7, S8] ) :-
принадлежит Y, [3, 2, 1] ), % Порядок Y-координат
nl, принадлежит X, [1, 2, 3] ),
% Порядок Х-координат
принадлежит( Фшк-X/Y,
[' '-S0, 1-S1, 2-S2, 3-S3, 4-S4, 5-S5, 6-S6, 7-S7, 8-S8]),
write( Фшк),
fail.
%Возврат с переходом к следующей клетке
показпоз( _ ).
line();
Поиск кратчайшего маршрута из s в t. (а) карта со
Поиск кратчайшего маршрута из s в t. (а) Карта со
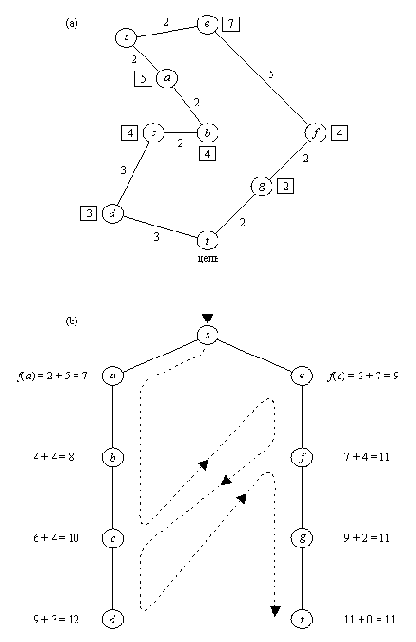
связями между городами; связи помечены своими длинами; в
квадратиках указаны расстояния по прямой до цели t.
(b) Порядок, в котором при поиске с предпочтением происходит
обход городов. Эвристические оценки основаны на расстояниях
по прямой. Пунктирной линией показано переключение активности
между альтернативными путями. Эта линия задает тот порядок, в
котором вершины принимаются для продолжения пути, а не тот
порядок, в котором они порождаются.
тивой, т.е. просматривает свое поддерево. У поддеревьев есть свои поддеревья, их просматривают подпроцессы подпроцессов и т.д. В каждый данный момент среди всех конкурирующих процессов активен только один - тот, который занимается наиболее перспективной к настоящему моменту альтернативой, т.е. альтернативой с наименьшим значением f. Остальные процессы спокойно ждут того момента, когда f-оценки изменятся и в результате какая-нибудь другая альтернатива станет наиболее перспективной. Тогда производится переключение активности на эту альтернативу. Механизм активации-дезактивации процессов функционирует следующим образом: процесс, работающий над текущей альтернативой высшего приоритета, получает некоторый "бюджет" и остается активным до тех пор, пока его бюджет не исчерпается. Находясь в активном состоянии, процесс продолжает углублять свое поддерево. Встретив целевую вершину, он выдает соответствующее решение. Величина бюджета, предоставляемого процессу на данный конкретный запуск, определяется эвристической оценкой конкурирующей альтернативы, ближайшей к данной.
На рис. 12.2 показан пример поведения конкурирующих процессов. Дана карта, задача состоит в том, чтобы найти кратчайший маршрут из стартового города s в целевой город t. В качестве оценки стоимости остатка маршрута из города Х до цели мы будем использовать расстояние по прямой расст( X, t) от Х до t. Таким образом,
f( Х) = g( X) + h( X) = g( X) + расст( X, t)
Мы можем считать, что в данном примере процесс поиска с предпочтением состоит из двух процессов. Каждый процесс прокладывает свой путь - один из двух альтернативных путей: Процесс 1 проходит через а. Процесс 2 - через е. Вначале Процесс 1 более активен, поскольку значения f вдоль выбранного им пути меньше, чем вдоль второго пути. Когда Процесс 1 достигает города с, а Процесс 2 все еще находится в е, ситуация меняется:
f( с) = g( c) + h( c) = 6 + 4 = 10
f( e) = g( e) + h( e) = 2 + 7 = 9
Поскольку f( e) < f( c), Процесс 2 переходит к f, a Процесс 1 ждет. Однако
f( f) = 7 + 4 = 11
f( c) = 10
f( c) < f( f)
Поэтому Процесс 2 останавливается, а Процессу 1 дается разрешение продолжать движение, но только до d, так как f( d) = 12 > 11. Происходит активация Процесса 2, после чего он, уже не прерываясь, доходит до цели t.
Мы реализуем этот механизм программно при помощи усовершенствования программы поиска в ширину (рис. 11.13). Множество путей-кандидатов представим деревом. Дерево будет изображаться в программе в виде терма, имеющего одну из двух форм:
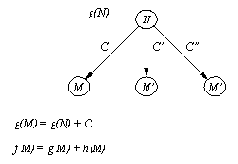
(1) л( В, F/G) - дерево, состоящее из одной вершины (листа); В - вершина пространства состояний, G - g( B) (стоимость уже найденного пути из стартовой вершины в В); F - f( В) = G + h( В).
(2) д( В, F/G, Пд) - дерево с непустыми поддеревьями; В - корень дерева, Пд - список поддеревьев; G - g( B); F - уточненное значение f( В), т.е. значение f для наиболее перспективного преемника вершины В; список Пд упорядочен в порядке возрастания f-оценок поддеревьев.
Уточнение значения f необходимо для того, чтобы дать программе возможность распознавать наиболее перспективное поддерево (т.е. поддерево, содержащее наиболее перспективную концевую вершину) на любом уровне дерева поиска. Эта модификация f-оценок на самом деле приводит к обобщению, расширяющему область определения функции f. Теперь функция f определена не только на вершинах, но и на деревьях. Для одновершинных деревьев (листов) n остается первоначальное определение
f( n) = g( n) + h( n)
Для дерева T с корнем n, имеющем преемников m1, m2, ..., получаем
f( T) = min f( mi
)
i
Программа поиска с предпочтением, составленная в соответствии с приведенными выше общими соображениями, показана на рис 12.3. Ниже даются некоторые дополнительные пояснения.
Так же, как и в случае поиска в ширину (рис. 11.13), ключевую роль играет процедура расширить, имеющая на этот раз шесть аргументов:
расширить( Путь, Дер, Предел, Дер1, ЕстьРеш, Решение)
Эта процедура расширяет текущее (под)дерево, пока f-оценка остается равной либо меньшей, чем Предел.
line();% Поиск с предпочтением
эврпоиск( Старт, Решение):-
макс_f( Fмакс).
% Fмакс > любой f-оценки
расширить( [ ], л( Старт, 0/0), Fмакс, _, да, Решение).
расширить( П, л( В, _ ), _, _, да, [В | П] ) :-
цель( В).
расширить( П, л( В, F/G), Предел, Дер1, ЕстьРеш, Реш) :-
F <= Предел,
( bagof( B1/C, ( после( В, В1, С), not принадлежит( В1, П)),
Преемники), !,
преемспис( G, Преемники, ДД),
опт_f( ДД, F1),
расширить( П, д( В, F1/G, ДД), Предел, Дер1,
ЕстьРеш, Реш);
ЕстьРеш = никогда).
% Нет преемников - тупик
расширить( П, д( В, F/G, [Д | ДД]), Предел, Дер1,
ЕстьРеш, Реш):-
F <= Предел,
опт_f( ДД, OF), мин( Предел, OF, Предел1),
расширить( [В | П], Д, Предел1, Д1, ЕстьРеш1, Реш),
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш).
расширить( _, д( _, _, [ ]), _, _, никогда, _ ) :- !.
% Тупиковое дерево - нет решений
расширить( _, Дер, Предел, Дер, нет, _ ) :-
f( Дер, F), F > Предел.
% Рост остановлен
продолжить( _, _, _, _, да, да, Реш).
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш):-
( ЕстьРеш1 = нет, встав( Д1, ДД, НДД);
ЕстьРеш1 = никогда, НДД = ДД),
опт_f( НДД, F1),
расширить( П, д( В, F1/G, НДД), Предел, Дер1,
ЕстьРеш, Реш).
преемспис( _, [ ], [ ]).
преемспис( G0, [В/С | ВВ], ДД) :-
G is G0 + С,
h( В, Н),
% Эвристика h(B)
F is G + Н,
преемспис( G0, ВВ, ДД1),
встав( л( В, F/G), ДД1, ДД).
% Вставление дерева Д в список деревьев ДД с сохранением
% упорядоченности по f-оценкам
встав( Д, ДД, [Д | ДД] ) :-
f( Д, F), опт_f( ДД, F1),
F =< F1, !.
встав( Д, [Д1 | ДД], [Д1 | ДД1] ) ) :-
встав( Д, ДД, ДД1).
% Получение f-оценки
f( л( _, F/_ ), F). % f-оценка листа
f( д( _, F/_, _ ) F). % f-оценка дерева
опт_f( [Д | _ ], F) :-
% Наилучшая f-оценка для
f( Д, F).
% списка деревьев
опт_f( [ ], Fмакс) :-
% Нет деревьев:
мaкс_f( Fмакс).
% плохая f-оценка
мин( X, Y, X) :-
Х =< Y, !.
мин( X, Y, Y).
line();
Поиск с предпочтением
Поиск с предпочтением
Программу поиска с предпочтением можно получить как результат усовершенствования программы поиска в ширину (рис. 11.13). Подобно поиску в ширину, поиск с предпочтением начинается со стартовой вершины и использует множество путей-кандидатов. В то время, как поиск в ширину всегда выбирает для продолжения самый короткий путь (т.е. переходит в вершины наименьшей глубины), поиск с предпочтением вносит в этот принцип следующее усовершенствование: для каждого кандидата вычисляется оценка и для продолжения выбирается кандидат с наилучшей оценкой.
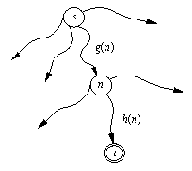
Построение эвристической оценки f(n) стоимости самого дешевого пути из s в t, проходящего через n: f(n) = g(n) + h(n).
Построение эвристической оценки f(n) стоимости
самого дешевого пути из s в t, проходящего через n: f(n) = g(n) + h(n).
Мы будем в дальнейшем предполагать, что для дуг пространства состояний определена функция стоимости с(n, n') - стоимость перехода из вершины n к вершине-преемнику n'.
Пусть f - это эвристическая оценочная функция, при помощи которой мы получаем для каждой вершины n оценку f( n) "трудности" этой вершины. Тогда наиболее перспективной вершиной-кандидатом следует считать вершину, для которой f принимает минимальное значение. Мы будем использовать здесь функцию f специального вида, приводящую к хорошо известному А*-алгоритму. Функция f( n) будет построена таким образом, чтобы давать оценку стоимости оптимального решающего пути из стартовой вершины s к одной из целевых вершин при условии, что этот путь проходит через вершину n. Давайте предположим, что такой путь существует и что t - это целевая вершина, для которой этот путь минимален. Тогда оценку f( n) можно представить в виде суммы из двух слагаемых (рис. 12.1):
f( n) = g( n) + h( n)
Здесь g( n) - оценка оптимального пути из s в n; h( n) - оценка оптимального пути из n в t.
Когда в процессе поиска мы попадаем в вершину n, мы оказываемся в следующей ситуация: путь из s в n уже найден, и его стоимость может быть вычислена как сумма стоимостей составляющих его дуг. Этот путь не обязательно оптимален (возможно, существует более дешевый, еще не найденный путь из s в n), однако стоимость этого пути можно использовать в качестве оценки g(n) минимальной стоимости пути из s в n. Что же касается второго слагаемого h(n), то о нем трудно что-либо сказать, поскольку к этому моменту область пространства состояний, лежащая между n и t, еще не "изучена" программой поиска. Поэтому, как правило, о значении h(n) можно только строить догадки на основании эвристических соображений, т.е. на основании тех знаний о конкретной задаче, которыми обладает алгоритм. Поскольку значение h зависит от предметной области, универсального метода для его вычисления не существует. Конкретные примеры того, как строят эти "эвристические догадки", мы приведем позже. Сейчас же будем считать, что тем или иным способом функция h задана, и сосредоточим свое внимание на деталях нашей программы поиска с предпочтением.
Можно представлять себе поиск с предпочтением следующим образом. Процесс поиска состоит из некоторого числа конкурирующих между собой подпроцессов, каждый из которых занимается своей альтерна-
Применение поиска с предпочтением к планированию выполнения задач
Применение поиска с предпочтением к планированию выполнения задач
Рассмотрим следующую задачу планирования. Дана совокупность задач t1, t2, ..., имеющих времена выполнения соответственно T1, Т2, ... . Все эти задачи нужно решить на m идентичных процессорах. Каждая задача может быть решена на любом процессоре, но в каждый данный момент каждый процессор решает только одну из задач. Между задачами существует отношение предшествования, определяющее, какие задачи (если таковые есть) должны быть завершены, прежде чем данная задача может быть запущена. Необходимо распределить задачи между процессорами без нарушения отношения предшествования, причем таким образом, чтобы вся совокупность задач была решена за минимальное время. Время, когда последняя задача в соответствии с выработанным планом завершает свое решение, называется временем окончания плана. Мы хотим минимизировать время окончания по всем возможным планам.
На рис. 12.8 показан пример задачи планирования, а также приведено два корректных плана, один из которых оптимален. Из примера видно, что оптимальный план обладает одним интересным свойством, а именно в нем может предусматриваться "время простоя" процессоров. В оптимальном плане рис. 12.8 процессор 1, выполнив задачу t, ждет в течение двух квантов времени, несмотря на то, что он мог бы начать выполнение задачи t.
Один из способов построить план можно грубо сформулировать так. Начинаем с пустого плана (с незаполненными временными промежутками для каждого процессора) и постепенно включаем в него задачи
Процедуры для головоломки "игра в восемь",
Процедуры для головоломки "игра в восемь",
предназначенные для использования программой поиска
с предпочтением рис. 12.3.
Существуют три отношения, отражающих специфику конкретной задачи:
после( Верш, Верш1, Ст)
Это отношение истинно, когда в пространстве состояний существует дуга стоимостью Ст между вершинами Верш и Верш1.
цель( Верш)
Это отношение истинно, если Верш - целевая вершина.
h( Верш, Н)
Здесь Н - эвристическая оценка стоимости самого дешевого пути из вершины Верш в целевую вершину.
В данном и следующих разделах мы определим эти отношения для двух примеров предметных областей: для головоломки "игра в восемь" (описанной в разделе 11.1) и планирования прохождения задач в многопроцессорной системе.
Отношения для "игры в восемь" показаны на рис. 12.6. Вершина пространства состояний - это некоторая конфигурация из фишек на игровой доске. В программе она задается списком текущих положений фишек. Каждое положение определяется парой координат X/Y. Элементы списка располагаются в следующем порядке:
(1) текущее положение пустой клетки,
(2) текущее положение фишки 1,
(3) текущее положение фишки 2,
...
Целевая ситуация (см. рис. 11.3) определяется при помощи предложения
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
Имеется вспомогательное отношение
расст( K1, K2, Р)
Р - это "манхеттеновское расстояние" между клетками Kl и K2, равное сумме двух расстояний между Kl и K2: расстояния по горизонтали и расстояния по вертикали.
Проект
Проект
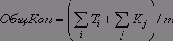
Вообще говоря, задачи планирования характеризуются значительной комбинаторной сложностью. Наша простая эвристическая функция не обеспечивает высокой эффективности управления поиском. Предложите другие эвристические функции и проведите с ними эксперименты.
line();/* Отношения для задачи планирования.
Вершины пространства состояний - частичные планы,
записываемые как
[ Задача1/Т1, Задача2/Т2, ...]*
[ Задача1/К1, Задача2/К2, ...]* ВремяОкончания
В первом списке указываются ждущие задачи и продолжительности их выполнения; во втором - текущие решаемые задачи и их времена окончания, упорядоченные так, чтобы выполнялись неравенства K1<=K2, K2<=K3, ... . Время окончания плана - самое последнее по времени время окончания задачи.
*/
после( Задачи1*[ _ /К | Акт1]*Кон1, Задачи2*Акт2*Кон2,Ст):-
удалить( Задача/Т, Задачи1, Задачи2),
% Взять ждущую задачу
not( принадлежит( Здч1/_, Задачи2),
раньше( ЗДЧ, Задача) ),
% Проверить предшествование
not( принадлежит( Здч1/К1, Акт1), К1<К2,
раньше( К1, Задача) ), % Активные задачи
Время is К + Т,
% Время окончания работающей задачи
встав( ЗадачаВремя, Акт1, Акт2, Кон1, Кон2),
Ст is Кон2 - Кон1.
после( Задачи*[ _ /К | Акт1]*Кон, Задачи2*Акт2*Кон, 0):-
вставпростой( К, Акт1, Акт2).
% Оставить процессор бездействующим
раньше( Задача1, Задача2) :-
% В соответствии с предшествованием
предш( Задача1, Задача2).
% Задача1 раньше, чем Задача2
раньше( Здч1, Здч2) :-
предш( Здч, Здч2),
раньше( Здч1, Здч).
встав( Здч/А, [Здч1/В | Спис], [Здч/А, Здч1/В | Спис], К, К):-
% Список задач упорядочен
А =< В, !.
встав( Здч/А, [Здч1/В | Спнс], [Здч1/В | Спис1], К1, К2) :-
встав( Здч/А, Спис, Спис1, Kl, К2).
встав( Здч/А, [ ], [Здч/А], _, А).
вставпростой( А, [Здч/В | Спис], [простой/В, Здч/В | Спис]):-
% Оставить процессор бездействующим
А < В, !
% До ближайшего времени окончания
вставпростой( А, [Здч/В | Спис], [Здч/В | Спис1]) :-
вставпростой( А, Спис, Спис1 ).
удалить( А, [А | Спис], Спис ).
% Удалить элемент из списка
удалить( А, [В | Спис], [В | Спис1] ):-
удалить( А, Спис, Спис1 ).
цель( [ ] *_*_ ). % Целевое состояние: нет ждущих задач
% Эвристическая оценка частичного плана основана на
% оптимистической оценке последнего времени окончания
% этого частичного плана,
% дополненного всеми остальными ждущими задачами.
h( Задачи * Процессоры * Кон, Н) :-
сумвремя( Задачи, СумВремя),
% Суммарная продолжительность
% ждущих задач
всепроц( Процессоры, КонВремя, N),
% КонВремя - сумма времен окончания
% для процессоров, N - их количество
ОбщКон is ( СумВремя + КонВремя)/N,
( ОбщКон > Кон, !, H is ОбщКон - Кон; Н = 0).
сумвремя( [ ], 0).
сумвремя( [ _ /Т | Задачи], Вр) :-
сумвремя( Задачи, Вр1),
Вр is Bp1 + Т.
всепроц( [ ], 0, 0).
всепроц( [ _ /T | СписПроц], КонВр, N) :-
всепроц( СписПроц, КонВр1, N1),
N is N1 + 1,
КонВр is КонВр1 + Т.
% Граф предшествования задач
предш( t1, t4). предш( t1, t5). предш( t2, t4).
предш( t2, t5). предш( t3, t5). предш( t3, t6).
предш( t3, t7).
% Стартовая вершина
старт( [t1/4, t2/2, t3/2, t4/20, t5/20, t6/11, t7/11] *
[простой/0, простой/0, простой/0] * 0 ).
Программа поиска с предпочтением.
Программа поиска с предпочтением.
Аргументы процедуры расширить имеют следующий смысл:
Путь Путь между стартовой вершиной и корнем дерева Дер.
Дер Текущее (под)дерево поиска.
Предел Предельное значение f-оценки, при котором допускается расширение.
Дер1 Дерево Дер, расширенное в пределах ограничения Предел;
f-оценка дерева Дер1 больше, чем Предел
( если только при расширении не была обнаружена целевая вершина).
ЕстьРеш Индикатор, принимающий значения "да", "нет" и "никогда".
Решение Решающий путь, ведущий из стартовой вершины через дерево Дер1
к целевой вершине и имеющий стоимость, не превосходящую ограничение Предел (если такая целевая вершина была обнаружена).
Переменные Путь, Дер, и Предел - это "входные" параметры процедуры расширить в том смысле, что при каждом обращении к расширить они всегда конкретизированы. Процедура расширить порождает результаты трех видов. Какой вид результата получен, можно определить по значению индикатора ЕстьРеш следующим образом:
(1) ЕстьРеш = да.
Решение = решающий путь, найденный при расширении дерева Дер с учетом ограничения Предел.
Дер1 = неконкретизировано.
(2) ЕстьРеш = нет
Дер1 = дерево Дер, расширенное до тех пор, пока его f-оценка не превзойдет Предел (см. рис. 12.4).
Решение = неконкретизировано.
(3) ЕстьРеш = никогда.
Дер1 и Решение = неконкретизированы.
В последнем случае Дер является "тупиковой" альтернативой, и соответствующий процесс никогда не будет реактивирован для продолжения просмотра этого дерева. Случай этот возникает тогда, когда f-оценка дерева Дер не превосходит ограничения Предел, однако дерево не может "расти" потому, что ни один его лист не имеет преемников, или же любой преемник порождает цикл.
Некоторые предложения процедуры расширить требуют пояснений. Предложение, относящееся к наиболее сложному случаю, когда Дер имеет поддеревья, т.е.
Дер = д( В, F/G, [Д | ДД ] )
означает следующее. Во-первых, расширению подвергается наиболее перспективное дерево Д. В качестве ограничения этому дереву выдается не Предел, а не-
Для оценки степени удаленности некоторой
Резюме
Для оценки степени удаленности некоторой вершины пространства состояний от ближайшей целевой вершины можно использовать эвристическую информацию. В этой главе были рассмотрены численные эвристические оценки. Эвристический принцип поиска с предпочтением направляет процесс поиска таким образом, что для продолжения поиска всегда выбирается вершина, наиболее перспективная с точки зрения эвристической оценки. В этой главе был запрограммирован алгоритм поиска, основанный на указанном принципе и известный в литературе как А*-алгоритм. Для того, чтобы решить конкретную задачу при помощи А*-алгоритма, необходимо определить пространство состояний и эвристическую функцию. Для сложных задач наиболее трудным моментом является подбор хорошей эвристической функции. Теорема о допустимости помогает установить, всегда ли А*-алгоритм, использующий некоторую конкретную эвристическую функцию, находит оптимальное решение.
Связь между g-оценкой вершины в и f- и g-оценками
Связь между g-оценкой вершины В и f- и g-оценками
ее "детей" в пространстве состояний. line();
Алгоритм поиска пути называют допустимым, если он всегда отыскивает оптимальное решение (т.е. путь минимальной стоимости) при условии, что такой путь существует. Наша реализация алгоритма поиска, пользуясь механизмом возвратов, выдает все существующие решения, поэтому, в нашем случае, условием допустимости следует считать оптимальность первого из найденных решений. Обозначим через h*(n) стоимость оптимального пути из произвольной вершины n в целевую вершину. Верна следующая теорема о допустимости А*-алгоритма: А*-алгоритм, использующий эвристическую функцию h, является допустимым, если
h( n) <= h*( n)
для всех вершин n пространства состояний.
line();Этот результат имеет огромное практическое значение. Даже если нам не известно точное значение h*, нам достаточно найти какую-либо нижнюю грань h* и использовать ее в качестве h в А*-алгоритме - оптимальность решения будет гарантирована.
Существует тривиальная нижняя грань, а именно:
h( n) = 0, для всех вершин n пространства состояний.
И при таком значении h допустимость гарантирована. Однако такая оценка не имеет никакой эвристической силы и ничем не помогает поиску. А*-алгоритм при h=0 ведет себя аналогично поиску в ширину. Он, действительно, превращается в поиск в ширину, если, кроме того, положить с(n, n' )=1 для всех дуг (n, n') пространства состояний. Отсутствие эвристической силы оценки приводит к большой комбинаторной сложности алгоритма. Поэтому хотелось бы иметь такую оценку h, которая была бы нижней гранью h* (чтобы обеспечить допустимость) и, кроме того, была бы как можно ближе к h* (чтобы обеспечить эффективность). В идеальном случае, если бы нам была известна сама точная оценка h*, мы бы ее и использовали: А*-алгоритм, пользующийся h*, находит оптимальное решение сразу, без единого возврата.
Три стартовых позиции для "игры в восемь": (а) решение
Три стартовых позиции для "игры в восемь": (а) решение
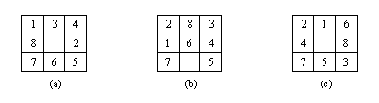
4 шага; (b) решение требует 5 шагов; (с) решение требует 18 шагов.
Наша задача - минимизировать длину решения, поэтому мы положим стоимости всех дуг пространства состояний равными 1. В программе рис. даны также определения трех начальных позиций (см. рис. 12.7).
Эвристическая функция h, запрограммирована как отношение
h( Поз, Н)
Поз - позиция на доске; Н вычисляется как комбинация из двух оценок:
(1) сумрасст - "суммарное расстояние" восьми фишек, находящихся в позиции Поз, от их положений в целевой позиции. Например, для начальной позиции, показанной на рис. 12.7(а), сумрасст = 4.
(2) упоряд - степень упорядоченности фишек в текущей позиции по отношению к тому порядку, в котором они должны находиться в целевой позиции. Величина упоряд вычисляется как сумма очков, приписываемых фишкам, согласно следующим правилам: фишка в центральной позиции - 1 очко; фишка не в центральной позиции, и непосредственно за ней следует (по часовой стрелке) та фишка, какая и должна за ней следовать в целевой позиции - 0 очков. то же самое, но за фишкой следует "не та" фишка - 2 очка.
Например, для начальной позиции рис.12.7(а),
упоряд = 6.
Эвристическая оценка Н вычисляется как сумма
Н = сумрасст + 3 * упоряд
Эта эвристическая функция хорошо работает в том смысле, что она весьма эффективно направляет поиск к цели. Например, при решении головоломок рис. 12.7(а) и (b) первое решение обнаруживается без единого отклонения от кратчайшего решающего пути. Другими словами, кратчайшие решения обнаруживаются сразу, без возвратов. Даже трудная головоломка рис. 12.7 (с) решается почти без возвратов. Но данная эвристическая функция страдает тем недостатком, что она не является допустимой: нет гарантии, что более короткие пути обнаруживаются раньше более длинных. Дело в том, что для функции h условие h <= h* выполнено не для всех вершин пространства состояний. Например, для начальной позиции рис. 12.7 (а)
h = 4 + 3 * 6 = 22, h* = 4
С другой стороны, оценка "суммарное расстояние" допустима: для всех позиций
сумрасст <= h*
Доказать это неравенство можно при помощи следующего рассуждения: если мы ослабим условия задачи и разрешим фишкам взбираться друг на друга, то каждая фишка сможет добраться до своего целевого положения по траектории, длина которой в точности равна манхеттеновскому расстоянию между ее начальным и целевым положениями. Таким образом, длина оптимального решения упрощенной задачи будет в точности равна сумрасст. Однако в исходном варианте задачи фишки взаимодействуют друг с другом и мешают друг другу, так что им уже трудно идти по своим кратчайшим траекториям. В результате длина оптимального решения окажется больше либо равной сумрасст.
для задачи поиска маршрута рис.
Упражнение
Определите отношения после, цель и h для задачи поиска маршрута рис. 12.2. Посмотрите, как наш алгоритм поиска с предпочтением будет вести себя при решении этой задачи.
с предпочтением, приведенную на рис.
Упражнение
Введите в программу поиска с предпочтением, приведенную на рис. 12.3, подсчет числа вершин, порожденных в процессе поиска. Один из простых способов это сделать - хранить текущее число вершин в виде факта, устанавливаемого при помощи assert. Всегда, когда порождаются новые вершины, уточнять это значение при помощи retract и assert. Проведите эксперименты с различными эвристическими функциями задачи "игра в восемь" с целью оценить их эвристическую силу. Используйте для этого вычисленное количество порожденных вершин.