Абстракция данных
Абстракцию данных можно рассматривать как процесс организации различных фрагментов информации в единые логические единицы (возможно, иерархически), придавая ей при этом некоторую концептуально осмысленную форму. Каждая информационная единица должна быть легко доступна в программе. В идеальном случае все детали реализации такой структуры должны быть невидимы пользователю этой структуры. Самое главное в этом процессе - дать программисту возможность использовать информацию, не думая о деталях ее действительного представления.
Обсудим один из способов реализации этого принципа на Прологе. Рассмотрим снова пример с семьей из предыдущего раздела. Каждая семья - это набор некоторых фрагментов информации. Все эти фрагменты объединены в естественные информационные единицы, такие, как "член семьи" или "семья", и с ними можно обращаться как с едиными объектами. Предположим опять, что информация о семье структурирована так же, как на рис. 4.1. Определим теперь некоторые отношения, с помощью которых пользователь может получать доступ к конкретным компонентам семьи, не зная деталей рис. 4.1. Такие отношения можно назвать селекторами, поскольку они позволяют выбирать конкретные компоненты. Имя такого отношения-селектора будет совпадать с именем компоненты, которую нужно выбрать. Отношение будет иметь два аргумента: первый - объект, который содержит компоненту, и второй - саму компоненту:
отношение_селектор(Объект, Выбранная_компонента)
Вот несколько селекторов для структуры семья:
муж( семья( Муж, _, _ ), Муж).
жена( семья( _, Жена, _ ), Жена).
дети( семья( _, _, СписокДетей ), СписокДетей).
Можно также создать селекторы для отдельных детей семьи:
первыйребенок( Семья, Первый) :-
дети( Семья, [Первый | _ ]).
второйребенок( Семья, Второй) :-
дети( Семья, [ _, Второй | _ ]).
. . .
Можно обобщить этот селектор для выбора N-го ребенка:
nребенок( N, Семья, Ребенок) :-
дети( Семья, СписокДетей),
n_элемент( N, СписокДетей, Ребенок)
% N-й элемент списка
Другим интересным объектом является "член семьи". Вот некоторые связанные с ним селекторы, соответствующие рис. 4.1:
имя( членсемьи( Имя, _, _, _ ), Имя).
фамилия( членсемьи( _, Фамилия, _, _ ), Фамилия).
датарождения( членсемьи( _, _, Дата), Дата).
Какие преимущества мы можем получить от использования отношений-селекторов? Определив их, мы можем теперь забыть о конкретном виде структуры представления информации. Для пополнения и обработки этой информации нужно знать только имена отношений-селекторов и в оставшейся части программы пользоваться только ими. В случае, если информация представлена сложной структурой, это легче, чем каждый раз обращаться к ней в явном виде. В частности, в нашем примере с семьей пользователь не обязан знать, что дети представлены в виде списка. Например, предположим, мы хотим сказать, что Том Фокс и Джим Фокс принадлежат к одной семье и что Джим - второй ребенок Тома. Используя приведенные выше отношения-селекторы, мы можем определить двух человек, назовем их Человек1 и Человек2, и семью.
Следующий список целей приводит к желаемому результату:
имя( Человек1, том), фамилия( Человек1, фокс),
% Человек1 - Том Фокс
имя( Человек2, джим), фамилия( Человек1, фокс),
% Человек2 - Джим Фокс
муж( Семья, Человек1),
второйребенок( Семья, Человек2)
Использование отношений-селекторов облегчает также и последующую модификацию программ. Представьте себе, что мы захотели повысить эффективность программы, изменив представление информации. Все, что нужно сделать для этого, - изменить определения отношений-селекторов, и вся остальная программа без изменений будет работать с этим новым представлением.
Альфа-бета алгоритм: эффективная реализация минимаксного принципа
Программа, показанная на рис. 15.3, производит просмотр в глубину дерева поиска, систематически обходя все содержащиеся в нем позиции вплоть до терминальных; она вычисляет статические оценки всех терминальных позиций. Как правило, для того, чтобы получить правильную минимаксную оценку корневой вершины, совсем не обязательно проделывать эту работу полностью. Поэтому алгоритм поиска можно сделать более экономным. Его можно усовершенствовать, используя следующую идею. Предположим, что у нас есть два варианта хода. Как только мы узнали, что один из них явно хуже другого, мы можем принять правильное решение, не выясняя, на сколько в точности он хуже. Давайте используем этот принцип для сокращения дерева поиска рис. 15.2. Процесс поиска протекает следующим образом:
(1) Начинаем с позиции а.
(2) Переходим к b.
(3) Переходим к d.
(4) Берем максимальную из оценок преемников позиции d, получаем V( d) = 4.
(5) Возвращаемся к b и переходим к е.
(6) Рассматриваем первого преемника позиции е с оценкой 5. В этот момент МАКС (который как раз и должен ходить в позиции е) обнаруживает, что ему гарантирована в позиции е оценка не меньшая, чем 5, независимо от оценок других (возможно, более предпочтительных) вариантов хода. Этого вполне достаточно для того, чтобы МИН, даже не зная точной оценки позиции е, понял, что для него в позиции b ход в е хуже, чем ход в d.
На основании приведенного выше рассуждения мы можем пренебречь вторым преемником позиции е
и приписать е приближенную оценку 5.
Приближенный характер этой оценки не окажет никакого влияния на оценку позиции b, а следовательно, и позиции а.
На этой идее основан знаменитый альфа-бета алгоритм, предназначенный для эффективной реализации минимаксного принципа. На рис. 15.4 показан результат работы альфа-бета алгоритма, примененного к нашему дереву рис. 15.2. Из рис. 15.4 видно, что некоторые из рабочих оценок стали приближенными. Однако этих приближенных оценок оказалось достаточно для того, чтобы определить точную оценку корневой позиции. Сложность поиска уменьшилась до пяти обращений к оценочной функции по сравнению с восемью обращениями (в первоначальном дереве поиска рис. 15.2).
Как уже говорилось раньше, ключевая идея альфа-бета отсечения состоит в том, чтобы найти ход не обязательно лучший, но "достаточно хороший" для того, чтобы принять правильное решение. Эту идею можно формализовать, введя два граничных значения, обычно обозначаемых через Альфа
и Бета, между которыми должна заключаться рабочая оценка позиции. Смысл этих граничных значений таков: Альфа -это самое маленькое значение оценки, которое к настоящему моменту уже гарантировано для игрока МАКС; Бета - это самое большое значение оценки, на которое МАКС пока еще может надеяться. Разумеется, с точки зрения МИН'а, Бета является самым худшим значением оценки, которое для него уже гарантировано. Таким образом, действительное значение оценки (т. е. то, которое нужно найти) всегда лежит между Альфа и Бета. Если же стало известно, что оценка некоторой позиции лежит вне интервала Альфа-Бета, то этого достаточно для того, чтобы сделать вывод: данная позиция не входит в основной вариант. При этом точное значение оценки такой позиции знать не обязательно, его надо знать только тогда, когда оценка лежит между Альфа и Бета. "Достаточно хорошую" рабочую оценку V( Р, Альфа, Бета) позиции Р по отношению к Альфа и Бета можно определить формально как любое значение, удовлетворяющее следующим ограничениям:
V( P, Альфа, Бета) <= Альфа если V( P) <= Альфа
V( P, Альфа, Бета) = V( P)
если Альфа < V( P) < Бета
V( P, Альфа, Бета) >= Бета если V( P) >= Бета
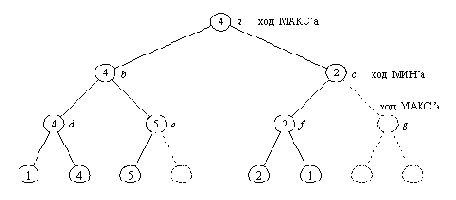
Рис. 15. 4. Дерево рис. 15.2 после применения альфа-бета алгоритма.
Пунктиром показаны ветви, отсеченные альфа-бета алгоритмом
для экономии времени поиска. В результате некоторые из
рабочих оценок стали приближенными (вершины c, е, f;
сравните с рис.15.2). Однако этих приближенных оценок
достаточно для вычисления точной оценки корневой
вершины и построения основного варианта.
Очевидно, что, умея вычислять "достаточно хорошую" оценку, мы всегда можем вычислить точную оценку корневой позиции Р, установив границы интервала следующим образом:
V( Р, -бесконечность, +бесконечность) = V( P)
На рис. 15.5 показана реализация альфа-бета алгоритма в виде программы на Прологе. Здесь основное отношение -
альфабета( Поз, Альфа, Бета, ХорПоз, Оц)
где ХорПоз - преемник позиции Поз с "достаточно хорошей" оценкой Оц, удовлетворяющей всем указанным выше ограничениям:
Оц = V( Поз, Альфа, Бета)
Процедура
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц)
находит достаточно хорошую позицию ХорПоз в списке позиций СписПоз; Оц - приближенная (по отношению к Альфа и Бета) рабочая оценка позиции ХорПоз.
Интервал между Альфа и Бета может сужаться (но не расширяться!) по мере углубления поиска, происходящего при рекурсивных обращениях к альфа-бета процедуре.
Отношение
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета)
определяет новый интервал (НовАльфа, НовБета). Он всегда уже, чем старый интервал (Альфа, Бета), или равен ему. Таким образом, чем глубже мы оказываемся в дереве поиска, тем сильнее проявляется тенденция к сжатию интервала Альфа-Бета, и в результате оценивание позиций на более глубоких уровнях происходит в условиях более тесных границ. При более узких интервалах допускается большая степень "приблизительности" при вычислении оценок, а следовательно, происходит больше отсечений ветвей дерева. Возникает интересный вопрос: насколько велика экономия, достигаемая альфа-бета алгоритмом по сравнению с программой минимаксного полного перебора рис. 15.3?
Эффективность альфа-бета процедуры зависит от порядка, в котором просматриваются позиции. Всегда лучше первыми рассматривать самые сильные ходы с каждой из сторон. Легко показать на примерах, что
line(); % Альфа-бета алгоритм
альфабета( Поз, Альфа, Бета, ХорПоз, Оц) :-
ходы( Поз, СписПоз), !,
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц);
стат_оц( Поз, Оц).
прибл_лучш( [Поз | СписПоз], Альфа, Бета, ХорПоз, ХорОц) :-
альфабета( Поз, Альфа, Бета, _, Оц),
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц).
дост_хор( [ ], _, _, Поз, Оц, Поз, Оц) :- !.
% Больше нет кандидатов
дост_хор( _, Альфа, Бета, Поз, Оц, Поз, Оц) :-
ход_мина( Поз), Оц > Бета, !;
% Переход через верхнюю границу
ход_макса( Поз), Оц < Альфа, !.
% Переход через нижнюю границу
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц) :-
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета),
% Уточнить границы
прибл_лучш( СписПоз, НовАльфа, НовБета, Поз1, Оц1),
выбор( Поз, Оц, Поз1, Оц1, ХорПоз, ХорОц).
нов_границы( Альфа, Бета, Поз, Оц, Оц, Бета) :-
ход_мина( Поз), Оц > Альфа, !.
% Увеличение нижней границы
нов_границы( Альфа, Бета, Поз, Оц, Альфа, Оц) :-
ход_макса( Поз), Оц < Бета, !.
% Уменьшение верхней границы
нов_границы( Альфа, Бета, _, _, Альфа, Бета).
выбор( Поз, Оц, Поз1, Оц1, Поз, Оц) :-
ход_мина( Поз), Оц > Оц1, !;
ход_макса( Поз), Оц < Оц1, !.
выбор( _, _, Поз1, Оц1, Поз1, Оц1).
line(); Рис. 15. 5. Реализация альфа-бета алгоритма.
возможен настолько неудачный порядок просмотра, что альфа-бета алгоритму придется пройти через все вершины, которые просматривались минимаксным алгоритмом полного перебора. Это означает, что в худшем случае альфа-бета алгоритм не будет иметь никаких преимуществ. Однако, если порядок просмотра окажется удачным, то экономия может быть значительной. Пусть N - число терминальных поисковых позиций, для которых вычислялись статические оценки алгоритмом минимаксного полного перебора. Было доказано, что в лучшем случае, когда самые сильные ходы всегда рассматриваются первыми, альфа-бета алгоритм вычисляет статические оценки только для N позиций.
Этот результат имеет один практический аспект, связанный с проведением турниров игровых программ. Шахматной программе, участвующей в турнире, обычно дается некоторое определенное время для вычисления очередного хода, и доступная программе глубина поиска зависит от этого времени. Альфа-бета алгоритм сможет пройти при поиске вдвое глубже по сравнению с минимаксным полным перебором, а опыт показывает, что применение той же оценочной функции, но на большей глубине приводит к более сильной игре.
Экономию, получаемую за счет применения альфа-бета алгоритма, можно также выразить в терминах более эффективного коэффициента ветвления дерева поиска (т. е. числа ветвей, исходящих из каждой внутренней вершины). Пусть игровое дерево имеет единый коэффициент ветвления, равный b. Благодаря эффекту отсечения альфа-бета алгоритм просматривает только некоторые из существующих ветвей и тем самым уменьшает коэффициент ветвления. В результате коэффициент b превратится в b (в лучшем случае). В шахматных программах, использующих альфа-бета алгоритм, достигается коэффициент ветвления, равный 6, при наличии 30 различных вариантов хода в каждой позиции. Впрочем, на этот результат можно посмотреть и менее оптимистично: несмотря на применение альфа-бета алгоритма, после каждого продвижения вглубь на один полуход число терминальных поисковых вершин увеличивается примерно в 6 раз.
Арифметические действия
Пролог рассчитан главным образом на обработку символьной информации, при которой потребность в арифметических вычислениях относительно мала. Поэтому и средства для таких вычислений довольно просты. Для осуществления основных арифметических действий можно воспользоваться несколькими предопределенными операторами.
+ сложение
- вычитание
* умножение
/ деление
mod модуль, остаток от целочисленного деления
Заметьте, что это как раз тот исключительный случай. когда оператор может и в самом деле произвести некоторую операцию. Но даже и в этом случае требуется дополнительное указание на выполнение действия. Пролог-система знает, как выполнять вычисления, предписываемые такими операторами, но этого недостаточно для их непосредственного использования. Следующий вопрос - наивная попытка произвести арифметическое действие:
?- Х = 1 + 2.
Пролог-система "спокойно" ответит
Х = 1 + 2
а не X = 3, как, возможно, ожидалось. Причина этого проста: выражение 1 + 2 обозначает лишь прологовский терм, в котором + является функтором, а 1 и 2 - его аргументами. В вышеприведенной цели нет ничего, что могло бы заставить систему выполнить операцию сложения. Для этого в Прологе существует специальный оператор is (есть). Этот оператор заставит систему выполнить вычисление. Таким образом, чтобы правильно активизировать арифметическую операцию, надо написать:
?- Х is 1 + 2.
Вот теперь ответ будет
Х = 3
Сложение здесь выполняется специальной процедурой, связанной с оператором +. Мы будем называть такие процедуры встроенными.
В Прологе не существует общепринятой нотации для записи арифметических действий, поэтому в разных реализациях она может слегка различаться. Например, оператор '/' может в одних реализациях обозначать целочисленное деление, а в других - вещественное. В данной книге под '/' мы подразумеваем вещественное деление, для целочисленного же будем использовать оператор div. В соответствии с этим, на вопрос
?- Х is 3/2,
Y is 3 div 2.
ответ должен быть такой:
Х = 1.5
Y = 1
Левым аргументом оператора is является простой объект. Правый аргумент - арифметическое выражение, составленное с помощью арифметических операторов, чисел и переменных. Поскольку оператор is запускает арифметические вычисления, к моменту начала вычисления этой цели все ее переменные должны быть уже конкретизированы какими-либо числами. Приоритеты этих предопределенных арифметических операторов (см. рис. 3.8) выбраны с таким расчетом, чтобы операторы применялись к аргументам в том порядке, который принят в математике. Чтобы изменить обычный порядок вычислений, применяются скобки (тоже, как в математике). Заметьте, что +, -, *, / и div определены, как yfx, что определяет порядок их выполнения слева направо. Например,
Х is 5 - 2 - 1
понимается как
X is (5 - 2) - 1
Арифметические операции используются также и при сравнении числовых величин. Мы можем, например, проверить, что больше - 10000 или результат умножения 277 на 37, с помощью цели
?- 277 * 37 > 10000.
yes (да)
Заметьте, что точно так же, как и is, оператор '>' вызывает выполнение вычислений.
Предположим, у нас есть программа, в которую входит отношение рожд, связывающее имя человека с годом его рождения. Тогда имена людей, родившихся между 1950 и 1960 годами включительно, можно получить при помощи такого вопроса:
?- рожд( Имя, Год),
Год >= 1950,
Год <= 1960.
Ниже перечислены операторы сравнения:
Х > Y Х больше Y
Х < Y Х меньше Y
Х >= Y Х больше или равен Y
Х =< Y Х меньше или равен Y
Х =:= Y величины Х и Y совпадают (равны)
Х =\= Y величины Х и Y не равны
Обратите внимание на разницу между операторами сравнения '=' и '=:=', например, в таких целях как X = Y и Х =:= Y. Первая цель вызовет сопоставление объектов Х и Y, и, если Х и Y сопоставимы, возможно, приведет к конкретизации каких-либо переменных в этих объектах. Никаких вычислений при этом производиться не будет. С другой стороны, Х =:= Y вызовет арифметическое вычисление и не может привести к конкретизации переменных. Это различие можно проиллюстрировать следующими примерами:
?- 1 + 2 =:= 2 + 1.
yes
>- 1 + 2 = 2 + 1.
no
?- 1 + А = В + 2.
А = 2
В = 1
Давайте рассмотрим использование арифметических операций на двух простых примерах. В первом примере ищется наибольший общий делитель; во втором - определяется количество элементов в некотором списке.
Если заданы два целых числа Х и Y, то их наибольший общий делитель Д можно найти, руководствуясь следующими тремя правилами:
(1) Если Х и Y равны, то Д равен X.
(2) Если Х > Y, то Д равен наибольшему общему делителю Х разности Y - X.
(3) Если Y < X, то формулировка аналогична правилу (2), если Х и Y поменять в нем местами.
На примере легко убедиться, что эти правила действительно позволяют найти наибольший общий делитель. Выбрав, скажем, Х = 20 и Y = 25, мы, руководствуясь приведенными выше правилами, после серии вычитаний получим Д = 5.
Эти правила легко сформулировать в виде прологовской программы, определив трехаргументное отношение, скажем
нод( X , Y, Д)
Тогда наши три правила можно выразить тремя предложениями так:
нод( X, X, X).
нод( X, Y, Д) :-
Х < Y,
Y1 is Y - X,
нод( X, Y1, Д),
нод( X, Y, Д) :-
Y < X,
нод( Y, X, Д).
Разумеется, с таким же успехом можно последнюю цель в третьем предложении заменить двумя:
X1 is Х - Y,
нод( X1, Y, Д)
В нашем следующем примере требуется произвести некоторый подсчет, для чего, как правило, необходимы арифметические действия. Примером такой задачи может служить вычисление длины какого-либо списка; иначе говоря, подсчет числа его элементов. Определим процедуру
длина( Список, N)
которая будет подсчитывать элементы списка Список и конкретизировать N полученным числом. Как и раньше, когда речь шла о списках, полезно рассмотреть два случая:
(1) Если список пуст, то его длина равна 0.
(2) Если он не пуст, то Список = [Голова1 | Хвост] и его длина равна 1 плюс длина хвоста Хвост.
Эти два случая соответствуют следующей программе:
длина( [ ], 0).
длина( [ _ | Хвост], N) :-
длина( Хвост, N1),
N is 1 + N1.
Применить процедуру длина можно так:
?- длина( [a, b, [c, d], e], N).
N = 4
Заметим, что во втором предложении этой процедуры две цели его тела нельзя поменять местами. Причина этого состоит в том, что переменная N1 должна быть конкретизирована до того, как начнет вычисляться цель
N is 1 + N1
Таким образом мы видим, что введение встроенной процедуры is привело нас к примеру отношения, чувствительного к порядку обработки предложений и целей. Очевидно, что процедурные соображения для подобных отношений играют жизненно важную роль.
Интересно посмотреть, что произойдет, если мы попытаемся запрограммировать отношение длина без использования is. Попытка может быть такой:
длина1( [ ], 0).
длина1( [ _ | Хвост], N) :-
длина1( Хвост, N1),
N = 1 + N1.
Теперь уже цель
?- длина1( [a, b, [c, d], e], N).
породит ответ:
N = 1+(1+(1+(1+0)))
Сложение ни разу в действительности не запускалось и поэтому ни разу не было выполнено. Но в процедуре длина1, в отличие от процедуры длина, мы можем поменять местами цели во втором предложении:
длина1( _ | Хвост], N) :-
N = 1 + N1,
длина1( Хвост, N1).
Такая версия длина1 будет давать те же результаты, что и исходная. Ее можно записать короче:
длина1( [ _ | Хвост], 1 + N) :-
длина1( Хвост, N).
и она и в этом случае будет давать те же результаты. С помощью длина1, впрочем, тоже можно вычислять количество элементов списка:
?- длина( [а, b, с], N), Длина is N.
N = 1+(1+(l+0))
Длина = 3
Итак: Для выполнения арифметических действий используются встроенные процедуры. Арифметические операции необходимо явно запускать при помощи встроенной процедуры is. Встроенные процедуры связаны также с предопределенными операторами +, -, *, /, div и mod. К моменту выполнения операций все их аргументы должны быть конкретизированы числами. Значения арифметических выражений можно сравнивать с помощью таких операторов, как <, =< и т.д. Эти операторы вычисляют значения своих аргументов.
Атомы и числа
В гл. 1 мы уже видели несколько простых примеров атомов и переменных. Вообще же они могут принимать более сложные формы, а именно представлять собой цепочки следующих символов:
прописные буквы А, В, ..., Z
строчные буквы а, b, ..., z
цифры 0, 1, 2, ..., 9
специальные символы, такие как
+ - * / = : . & _ ~
Атомы можно создавать тремя способами:
(1) из цепочки букв, цифр и символа подчеркивания _, начиная такую цепочку со строчной буквы:
анна
nil
х25
х_25
х_25AB
х_
х__у
альфа_бета_процедура
мисс_Джонс
сара_джонс
(2) из специальных символов:
<--->
======>
...
.
...
: : =
Пользуясь атомами такой формы, следует соблюдать некоторую осторожность, поскольку часть цепочек специальных символов имеют в Прологе заранее определенный смысл. Примером может служить :- .
(3) из цепочки символов, заключенной в одинарные кавычки. Это удобно, если мы хотим, например, иметь атом, начинающийся с прописной буквы. Заключая его в кавычки, мы делаем его отличным от переменной:
'Том'
' Южная_Америка'
'Сара Джонс'
Числа в Прологе бывают целыми и вещественными. Синтаксис целых чисел прост, как это видно из следующих примеров: 1, 1313, 0, -97. Не все целые числа могут быть представлены в машине, поэтому диапазон целых чисел ограничен интервалом между некоторыми минимальным и максимальным числами, определяемыми конкретной реализацией Пролога. Обычно реализация допускает диапазон хотя бы от -16 383 до 16 383, а часто, и значительно более широкий.
Синтаксис вещественных чисел зависит от реализации. Мы будем придерживаться простых правил, видных из следующих примеров: 3.14, -0.0035, 100.2. При обычном программировании на Прологе вещественные числа используются редко. Причина этого кроется в том, что Пролог - это язык, предназначенный в первую очередь для обработки символьной, а не числовой информации, в противоположность языкам типа Фортрана, ориентированным на числовую обработку. При символьной обработке часто используются целые числа, например, для подсчета количества элементов списка; нужда же в вещественных числах невелика.
Кроме отсутствия необходимости в использовании вещественных чисел в обычных применениях Пролога, существует и другая причина избегать их. Мы всегда стремимся поддерживать наши программы в таком виде, чтобы их смысл был предельно ясен. Введение вещественных чисел в некоторой степени нарушает эту ясность из-за ошибок вычислений, связанных с округлением во время выполнения арифметических действий. Например, результатом вычисления выражения 10000 + 0.0001 - 10000 может оказаться 0 вместо правильного значения 0.0001.
AVL - дерево: приближенно сбалансированное дерево
AVL-дерево - это дерево, обладающее следующими свойствами:
(1) Левое и правое поддеревья отличаются по глубине не более чем на 1.
(2) Оба поддерева являются AVL-деревьями.
Деревья, удовлетворяющие этому определению, могут быть слегка разбалансированными. Однако можно показать, что даже в худшем случае глубина AVL-дерева примерно пропорциональна log n, где n - число вершин дерева. Таким образом гарантируется логарифмический порядок производительности операций внутри, добавить и удалить.
Операции над AVL-деревом работают по существу так же, как и над двоичным справочником. В них только сделаны добавления, связанные с поддержанием приближенной сбалансированности дерева. Если после вставления или удаления дерево перестает быть приближенно сбалансированным, то специальные механизмы возвращают ему требуемую степень сбалансированности. Для того, чтобы эффективно реализовать этот механизм, нам придется сохранять некоторую дополнительную информацию относительно степени сбалансированности дерева. На самом деле, нам нужно знать только разность между глубинами поддеревьев, которая может принимать значения -1, 0 или +1. Тем не менее для простоты мы предпочтем сохранять сами величины глубин поддеревьев, а не разности между ними.
Мы определим отношение вставления элемента как
доб_avl( Дер, X, НовДер)
где оба дерева Дер и НовДер - это AVL-деревья, причем НовДер получено из Дер вставлением элемента X. AVL-деревья будем представлять как термы вида
д( Лев, А, Прав)/Глуб
где А - корень, Лев и Прав - поддеревья, а Глуб -
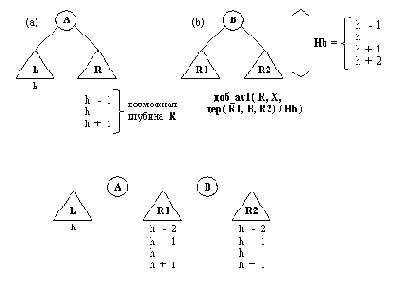
Рис. 10. 8. Задача вставления элемента в AVL-справочник
(a) AVL-дерево перед вставлением Х, Х > А;
(b) AVL-дерево после вставления Х в R;
(с) составные части, из которых следует построить новое дерево.
глубина дерева. Пустое дерево изображается как nil/0.
Теперь рассмотрим вставление элемента Х в непустой AVL-справочник
Дер = д( L, A, R)/H
Начнем со случая, когда Х больше А. Х необходимо вставить в R, поэтому имеем следующее отношение:
доб_аv1( R, X, д( R1, В, R2)/Hb)
На рис. 10.8 показаны составные части, из которых строится дерево НовДер:
L, А, R1, В, R2
Какова глубина деревьев L, R, R1 и R2? L и R могут отличаться по глубине не более, чем на 1. На рис. 10.8 видно, какую глубину могут иметь R1 и R2. Поскольку в R был добавлен только один элемент X, только одно из поддеревьев R1, R2 может иметь
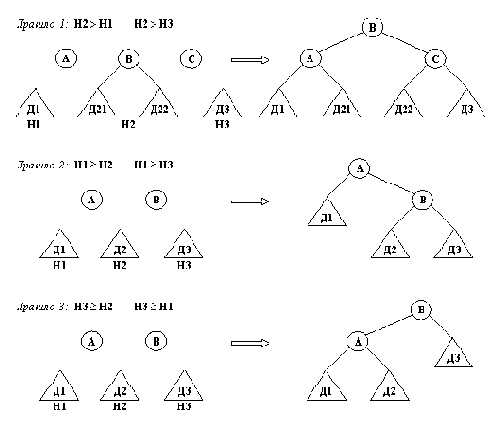
Рис. 10. 9. Три правила построения нового AVL-дepевa.
глубину h +1.
В случае, когда Х меньше, чем А, имеем аналогичную ситуацию, причем левое и правое поддеревья меняются местами. Таким образом, в любом случае мы должны построить дерево НовДер, используя три дерева (назовем их Дер1, Дер2 и Дер3) и два отдельных элемента А и В. Теперь рассмотрим вопрос: как соединить между собой эти пять составных частей, чтобы дерево НовДер было AVL-справочником? Ясно, что они должны располагаться внутри НовДер в следующем порядке (слева направо):
Дер1, А, Дер2, В, Дер3
Рассмотрим три случая:
(1) Среднее дерево Дер2 глубже остальных двух деревьев.
(2) Дер1 имеет глубину не меньше, чем Дер2 и Дер3.
(3) Дер3 имеет глубину не меньше, чем Дер2 и Дер1.
На рис. 10.9 видно, как можно построить дерево НовДер в каждом из этих трех случаев. Например, в случае 1 среднее дерево Дер2 следует разбить на два части, а затем включить их в состав НовДер. Три правила, показанные на pис.10.9, нетрудно запасать на Прологе в виде отношения
соединить( Дер, А, Дер2, В, Дер3, НовДер)
Последний аргумент НовДер - это AVL-дерево, построенное из пяти составных частей, пяти первых аргументов.
Правило 1, например, принимает вид:
соединить( Д1/Н1, А, д( Д21, В, Д22)/Н2, С, Д3/Н3,
% Пять частей
д( д( Д1/Н1, А, Д21)/На, В, д( Д22, С, Д3/Н3)/Нс)/Нb) :-
% Результат
H2 > H1, H2 > Н3, % Среднее дерево глубже остальных
На is Н1 + 1, % Глубина левого поддерева
Нс is Н3 + 1, % Глубина правого поддерева
Hb is На + 1, % Глубина всего дерева
Программа доб_аvl, вычисляющая также глубину дерева и его поддеревьев, показана полностью на рис. 10.10.
Bagof , setof и findall
При помощи механизма автоматического перебора можно получить одни за другим все объекты, удовлетворяющие некоторой цели. Всякий раз, как порождается новое решение, предыдущее пропадает и становится с этого момента недоступным. Однако у нас может возникнуть желание получить доступ ко всем порожденным объектам сразу, например собрав их в список. Встроенные предикаты bagof (набор) и setof (множество) обеспечивают такую возможность; вместо них иногда используют предикат findall (найти все).
Цель
bagof( X, P, L)
порождает список L всех объектов X, удовлетворяющих цели Р. Обычно bagof имеет смысл применять только тогда, когда Х и Р содержат общие переменные. Например, допустим, что мы включили в программу следующую группу предложений для разбиения букв (из некоторого множества) на два класса - гласные и согласные:
класс( а, глас).
класс( b, согл).
класс( с, согл).
класс( d, согл).
класс( е, глас).
класс( f, согл).
Тогда мы можем получить список всех согласных, упомянутых в этих предложениях, при помощи цели:
?- bagof( Буква, класс( Буква, согл), Буквы).
Буквы = [d, c, d, f]
Если же мы в указанной цели оставим класс букв неопределенным, то, используя автоматический перебор, получим два списка букв, каждый из которых соответствует одному из классов:
?- bagof( Буква, класс( Буква, Класс), Буквы).
Класс = глас
Буквы = [а,е]
Класс = согл
Буквы = [b, c, d, f]
Если bagof( X, Р, L) не находит ни одного решения для Р, то цель bagof
просто терпит неуспех.
Если один и тот же Х найден многократно, то все его экземпляры будут занесены в L, что приведет к появлению в L
повторяющихся элементов.
Предикат setof работает аналогично предикату bagof. Цель
setof( X, P, L)
как и раньше, порождает список L объектов X, удовлетворяющих Р. Только на этот раз список L будет упорядочен, а из всех повторяющихся элементов, если таковые есть, в него попадет только один. Упорядочение происходит по алфавиту или по отношению '<', если элементы списка - числа. Если элементы списка - структуры, то они упорядочиваются по своим главным функторам. Если же главные функторы совпадают, то решение о порядке таких термов принимается по их первым несовпадающим функторам, расположенным выше и левее других (по дереву). На вид объектов, собираемых в список, ограничения нет. Поэтому можно, например, составить список пар вида
Класс / Буква
при этом гласные будут расположены в списке первыми ("глас" по алфавиту раньше "согл"):
?- setof( Класс/Буква, класс( Буква, Класс), Спис).
Спис = [глас/а, глас/е, согл/b, согл/с, согл/d, согл/f]
Еще одним предикатом этого семейства, аналогичным bagof, является findall.
findall( X, P, L)
тоже порождает список объектов, удовлетворяющих Р. Он отличается от bagof
тем, что собирает в список все объекты X, не обращая внимание на (возможно) отличающиеся для них конкретизации тех переменных из P, которых нет в X. Это различие видно из следующего примера:
?- findall( Буква, класс( Буква, Класс), Буквы).
Буквы= [a, b, c, d, e, f]
Если не существует ни одного объекта X, удовлетворяющего P, то findall все равно имеет успех и выдает L = [ ].
Если в используемой реализации Пролога отсутствует встроенный предикат findall, то его легко запрограммировать следующим образом. Все решения для Р порождаются искусственно вызываемыми возвратами. Каждое решение, как только оно получено, немедленно добавляется к базе данных, чтобы не потерять его после нахождения следующего решения. После того, как будут получены и сохранены все решения, их нужно собрать в список, а затем удалить из базы данных при помощи retract. Весь процесс можно представлять себе как построение очереди из порождаемых решений. Каждое вновь порождаемое решение добавляется в конец этой очереди при помощи assert. Когда все решения собраны, очередь расформировывается. Заметим также, что конец очереди надо пометить, например, атомом "дно" (который, конечно, должен отличаться от любого ожидаемого решения). Реализация findall
в соответствии с описанным методом показана на рис. 7.4.
line();
findall( X, Цель, ХСпис) :-
саll( Цель),
% Найти решение
assert( очередь( X) ),
% Добавить егo
fail;
% Попытаться найти еще решения
assertz( очередь( дно) ),
% Пометить конец решений
собрать( ХСпис).
% Собрать решения в список
собрать( L) :-
retract( очередь(Х) ), !,
% Удалить следующее решение
( Х == дно, !, L = [ ];
% Конец решений?
L = [X | Остальные], собрать( Остальные) ).
% Иначе собрать остальные
line();
Рис. 7. 4. Реализация отношения findall.
Базовые процедуры поиска в И / ИЛИ-графах
В этом разделе нас будет интересовать какое-нибудь решение задачи независимо от его стоимости, поэтому проигнорируем пока стоимости связей или вершин И / ИЛИ-графа. Простейший способ организовать поиск в И / ИЛИ-графах средствами Пролога - это использовать переборный механизм, заложенный в самой пролог-системе. Оказывается, что это очень просто сделать, потому что процедурный смысл Пролога это и есть не что иное, как поиск в И / ИЛИ-графе. Например, И / ИЛИ-граф рис. 13.4 (без учета стоимостей дуг) можно описать при помощи следующих предложений:
а :- b.
% а - ИЛИ-вершина с двумя преемниками
а :- с.
% b и с
b :- d, е.
% b - И-вершина с двумя преемниками d и е
с :- h.
с :- f, g.
f :- h, i.
d. g. h.
% d, g и h - целевые вершины
Для того, чтобы узнать, имеет ли эта задача решение, нужно просто спросить:
?- а.
Получив этот вопрос, пролог-система произведет поиск в глубину в дереве рис. 13.4 и после того, как пройдет через все вершины подграфа, соответствующего решающему дереву рис. 13.4(b), ответит "да".
Преимущество такого метода программирования И / ИЛИ-поиска состоит в его простоте. Но есть и недостатки:
Мы получаем ответ "да" или "нет", но не получаем решающее дерево.
Можно было бы восстановить решающее дерево при помощи трассировки программы, но такой способ неудобен, да его и недостаточно, если мы хотим иметь возможность явно обратиться к решающему дереву как к объекту программы.
В эту программу трудно вносить добавления, связанные с обработкой стоимостей.
Если наш И / ИЛИ-граф - это граф общего вида, содержащий циклы, то пролог-система, следуя стратегии в глубину, может войти в бесконечный рекурсивный цикл.
Попробуем постепенно исправить эти недостатки. Сначала определим нашу собственную процедуру поиска в глубину для И / ИЛИ-графов.
Прежде всего мы должны изменить представление И / ИЛИ-графов. С этой целью введём бинарное отношение, изображаемое инфиксным оператором '--->'. Например, вершина а с двумя ИЛИ-преемниками будет представлена предложением
а ---> или : [b, с].
Оба символа '--->' и ':' - инфиксные операторы, которые можно определить как
:- ор( 600, xfx, --->).
:- ор( 500, xfx, :).
Весь И / ИЛИ-граф рис. 13.4 теперь можно задать при помощи множества предложений
а ---> или : [b, с].
b ---> и : [d, e].
с ---> и : [f, g].
е ---> или : [h].
f ---> или : [h, i].
цель( d). цель( g). цель( h).
Процедуру поиска в глубину в И / ИЛИ-графах можно построить, базируясь на следующих принципах:
Для того, чтобы решить задачу вершины В, необходимо придерживаться приведенных ниже правил:
(1) Если В - целевая вершина, то задача решается тривиальным образом.
(2) Если вершина В имеет ИЛИ-преемников, то нужно решить одну из соответствующих задач-преемников (пробовать решать их одну за другой, пока не будет найдена задача, имеющая решение).
(3) Если вершина В имеет И-преемников, то нужно решить все соответствующие задачи (пробовать решать их одну за другой, пока они не будут решены все).
Если применение этих правил не приводит к решению, считать, что задача не может быть решена.
Соответствующая программа выглядит так:
решить( Верш) :-
цель( Верш).
решить( Верш) :-
Верш ---> или : Вершины,
% Верш - ИЛИ-вершина
принадлежит( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
решить( Bepш1).
решить( Верш) :-
Верш ---> и : Вершины,
% Верш - И-вершина
решитьвсе( Вершины).
% Решить все задачи-преемники
решитьвсе( [ ]).
решитьвсе( [Верш | Вершины]) :-
решить( Верш),
решитьвсе( Вершины).
Здесь принадлежит - обычное отношение принадлежности к списку.
Эта программа все еще имеет недостатки:
она не порождает решающее дерево, и
она может зацикливаться, если И / ИЛИ-граф имеет соответствующую структуру (циклы).
Программу нетрудно изменить с тем, чтобы она порождала решающее дерево. Необходимо так подправить отношение решить, чтобы оно имело два аргумента:
решить( Верш, РешДер).
Решающее дерево представим следующим образом. Мы имеем три случая:
(1) Если Верш
- целевая вершина, то соответствующее решающее дерево и есть сама эта вершина.
(2) Если Верш
- ИЛИ-вершина, то решающее дерево имеет вид
Верш ---> Поддерево
где Поддерево - это решающее дерево для одного из преемников вершины Верш.
(3) Если Верш
- И-вершина, то решающее дерево имеет вид
Верш ---> и : Поддеревья
где Поддеревья - список решающих деревьев для всех преемников вершины Верш.
line();
% Поиск в глубину для И / ИЛИ-графов
% Процедура решить( Верш, РешДер) находит решающее дерево для
% некоторой вершины в И / ИЛИ-графе
решить( Верш, Верш) :-
% Решающее дерево для целевой
цель( Верш).
% вершины - это сама вершина
решить( Верш, Верш ---> Дер) :-
Верш ---> или : Вершины, % Верш - ИЛИ-вершина
принадлежит( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
решить( Bepш1, Дер).
решить( Верш, Верш ---> и : Деревья) :-
Верш ---> и : Вершины,
% Верш - И-вершина
решитьвсе( Вершины, Деревья).
% Решить все задачи-преемники
решитьвсе( [ ], [ ]).
решитьвсе( [Верш | Вершины], [Дер | Деревья]) :-
решить( Верш, Дер),
решитьвсе( Вершины, Деревья).
отобр( Дер) :-
% Отобразить решающее дерево
отобр( Дер, 0), !.
% с отступом 0
отобр( Верш ---> Дер, Н) :-
% Отобразить решающее дерево с отступом Н
write( Верш), write( '--->'),
H1 is H + 7,
отобр( Дер, H1), !.
отобр( и : [Д], Н) :-
% Отобразить И-список решающих деревьев
отобр( Д, Н).
отобр( и : [Д | ДД], Н) :-
% Отобразить И-список решающих деревьев
отобр( Д, Н),
tab( H),
отобр( и : ДД, Н), !.
отобр( Верш, Н) :-
write( Верш), nl.
line();
Рис. 13. 8. Поиск в глубину для И / ИЛИ-графов. Эта программа может
зацикливаться. Процедура решить
находит решающее дерево, а
процедура отобр показывает его пользователю. В процедуре отобр
предполагается, что на вывод вершины тратится только один символ.
Например, при поиске в И / ИЛИ-графе рис. 13.4 первое найденное решение задачи, соответствующей самой верхней вершине а, будет иметь следующее представление:
а ---> b ---> и : [d, c ---> h]
Три формы представления решающего дерева соответствуют трем предложениям отношения решить. Поэтому все, что нам нужно сделать для изменения нашей исходной программы решить, - это подправить каждое из этих трех предложений, просто добавив в каждое из них решающее дерево в качестве второго аргумента. Измененная программа показана на рис. 13.8. В нее также введена дополнительная процедура отобр для отображения решающих деревьев в текстовой форме. Например, решающее дерево рис. 13.4 будет отпечатано процедурой отобр в следующем виде:
а ---> b ---> d
е ---> h
Программа рис. 13.8 все еще сохраняет склонность к вхождению в бесконечные циклы. Один из простых способов избежать бесконечных циклов - это следить за текущей глубиной поиска и не давать программе заходить за пределы некоторого ограничения по глубине.
Это можно сделать, введя в отношение решить еще один аргумент:
решить( Верш, РешДер, МаксГлуб)
Как и раньше, вершиной Верш
представлена решаемая задача, а РешДер - это решение этой задачи, имеющее глубину, не превосходящую МаксГлуб. МаксГлуб
-это допустимая глубина поиска в графе. Если МаксГлуб
= 0, то двигаться дальше запрещено, если же МаксГлуб
> 0, то поиск распространяется на преемников вершины Верш, причем для них устанавливается меньший предел по глубине, равный МаксГлуб -1. Это дополнение легко ввести в программу рис. 13.8. Например, второе предложение процедуры решить примет вид:
решить( Верш, Верш ---> Дер, МаксГлуб) :-
МаксГлуб > 0,
Верш ---> или : Вершины,
% Верш - ИЛИ-вершина
принадлежит ( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
Глуб1 is МаксГлуб - 1,
% Новый предел по глубине
решить( Bepш1, Дер, Глуб1).
% Решить задачу-преемник с меньшим ограничением
Нашу процедуру поиска в глубину с ограничением можно также использовать для имитации поиска в ширину. Идея состоит в следующем: многократно повторять поиск в глубину каждый раз все с большим значением ограничения до тех пор, пока решение не будет найдено, То есть попробовать решить задачу с ограничением по глубине, равным 0, затем - с ограничением 1, затем - 2 и т.д. Получаем следующую программу:
имитация_в_ширину( Верш, РешДер) :-
проба_в_глубину( Верш, РешДер, 0).
% Проба поиска с возрастающим ограничением, начиная с 0
проба_в_глубину( Верш, РешДер, Глуб) :-
решить( Верш, РешДер, Глуб);
Глуб1 is Глуб + 1,
% Новый предел по глубине
проба_в_глубину( Верш, РешДер, Глуб1).
% Попытка с новым ограничением
Недостатком имитации поиска в ширину является то, что при каждом увеличении предела по глубине программа повторно просматривает верхнюю область пространства поиска.
Благодарности
Интерес к Прологу впервые возник у меня под влиянием Дональда Мики. Я благодарен также Лоренсу Берду, Фернандо Перейра и Дэвиду Г. Уоррену, входившим в свое время в эдинбургскую группу разработчиков Пролога, за их советы по составлению программ и многочисленные дискуссии. Чрезвычайно полезными были замечания и предложения, высказанные Эндрью Макгеттриком и Патриком Уинстоном. Среди прочитавших рукопись книги и сделавших ценные замечания были также Игорь Кононенко, Таня Маярон, Игорь Мозетик, Тимоти Ниблетт и Фрэнк Зердин. Мне бы хотелось также поблагодарить Дебру Майсон-Этерингтон и Саймона Пламтри из издательства Эддисон-Уэсли за труд, вложенный в издание этой книги. И наконец, эта книга не могла бы появиться на свет без стимулирующего влияния творческой деятельности всего международного сообщества специалистов по логическому программированию.
Иван Братко
Институт Тьюринга, Глазго
Январь 1986
Назад | Содержание | Вперёд
Братко И
Б 87 Программирование на языке Пролог для искусственного интеллекта: Пер. с англ. -М.: Мир, 1990.- 560 с., ил.
ISBN 5-03-001425-Х
Книга известного специалиста по программированию (Югославия), содержащая основы языка Пролог и его приложения для решения задач искусственного интеллекта. Изложение отличается методическими достоинствами - книга написана в хорошем стиле, живым языком. Книга дополняет имеющуюся на русском языке литературу по языку Пролог.
Для программистов разной квалификации, специалистов по искусственному интеллекту, для всех изучающих программирование.
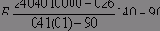
Редакция литературы по математическим наукам
ISBN 5-03-001425-X (русск.)
ISBN 0-201-14224-4 (англ.)
(c) 1986 Addison-Wesley Publishing Company, Inc.
(c) перевод на русский язык, Лупенко А.И., Степанов A.M., 1990
Электронную версию книги создал Иванов Виктор Михайлович (студент Донского Государственного Технического Университета (ДГТУ), г. Ростов-на-Дону, специальность 2204 "Программное обеспечение АС и ВТ", 5 курс) 2 апреля 2004 года. Книга размещена на сайте http://dstu2204.narod.ru/ ( на этой странице ).
При создании книги были использованы главы 2-12 из книги в электронном виде в черновом варианте, взятые с этой страницы (что, впрочем, составило не более 15% от всей работы) и бумажный экземпляр книги из библиотеки ДГТУ. Для создания gif-картинок применялся CorelDRAW 12 , для редактирования htm-страниц - MS FrontPage Editor 3.0 . Для графического дизайн-оформления, максимально похожего на исходное, использована hmtl-графика + JavaScript.
Текст и картинки электронной версии книги проверены на совпадение с оригиналом.
Улучшения по сравнению с бумажной версией книги: Расширено оглавление путём добавления подпунктов (с трёхцифровым кодом). Сделан алфавитно-предметный указатель на JavaScript (полностью соответствующий тому, который есть в бумажной книге) на гиперссылках (вместо номеров страниц, как в бумажной книге) с выделением ключевого слова и сбросом выделения через "Обновить" в броузере (F5). Сделана система быстрого получения ответов на упражнения по такому же принципу.
Памяти погибшей Югославии посвящается

Назад | Содержание | Вперёд
Цели и ограничения на ходы
Основное понятие Языка Советов - "элементарный совет". Элементарный совет содержит указание о том, что следует делать (или пытаться делать) в некоторой типовой ситуации. Совет выражается в терминах тех целей, которые необходимо достичь, и тех средств, которые следует применять для этого. Мы называем участников игры "игроком" и "противником"; совет всегда относится к "игроку". Каждый элементарный совет имеет следующие четыре составные части: главная цель: цель, к которой нужно стремиться; цель-поддержка: цель, которая должна постоянно удовлетворяться в процессе достижения главной цели; ограничения на ходы игрока: предикат, определяющий некоторое подмножество ходов из всех разрешенных ходов игрока (ходы, представляющие интерес с точки зрения достижения указанных целей). ограничения на ходы противника: предикат, выбирающий ходы, которые должен рассмотреть противник (ходы, препятствующие достижению указанных целей).
Рассмотрим, например, шахматный эндшпиль "король и пешка против короля". Здесь применима следующая очевидная идея: провести пешку в ферзи, продвигая ее вперед. В форме совета это выражается так:
главная цель: провести пешку;
цель-поддержка: не потерять пешку;
ходы игрока: продвигать пешку;
ходы противника: приближаться королем к пешке.
Цели с отрицанием
Использование знака отрицания в левых частях правил, а следовательно, и в вопросах, обрабатываемых процедурой рассмотреть, представляется естественным и его следует разрешить. В качестве первой попытки можно предложить следующий способ работы с отрицанием целей:
line();% Процедура-драйвер верхнего уровня
эксперт :-
принять_вопрос( Вопрос),
% Ввести вопрос пользователя
( ответ_да( Вопрос);
% Попытка найти положительный ответ
ответ_нет( Вопрос) ).
% Если нет положительного ответа, то найти отрицательный
ответ_да( Вопрос) :-
% Искать положительный ответ на Вопрос
статус( отрицательный),
% Пока еще нет положительного ответа
рассмотреть( Вопрос, [ ], Ответ),
% Трасса пуста
положительный( Ответ), % Искать положительный ответ
статус( положительный),
% Найден положительный ответ
выдать( Ответ), nl,
write( 'Нужны еще решения?' ),
принять( Ответ1), % Прочесть ответ пользователя
Ответ1 = нет.
% В противном случае возврат к "рассмотреть"
ответ_нет( Вопрос):-
% Искать отрицательный ответ на Вопрос
retract( пока_нет_положительного_решения), !,
% Не было положительного решения?
рассмотреть( Вопрос, [ ], Ответ),
отрицательный( Ответ),
выдать( Ответ), nl,
write( 'Нужны еще решения?' ),
принять( Ответ1),
Ответ1 = нет.
% В противном случае - возврат к "рассмотреть"
статус( отрицательный) :-
assert( пока_нет_положительного_решения).
статус( положительный) :-
retract( пока_нет_положительного_решения), !; true.
принять_вопрос( Вопрос) :-
nl, write( 'Пожалуйста, спрашивайте:'), nl,
read( Вопрос).
line();
Рис. 14. 13. Оболочка экспертной системы: драйвер. Обращение
к оболочке из Пролога при помощи процедуры эксперт.
рассмотреть( не Цель, Трасса, Ответ) :- !,
рассмотреть( Цель, Трасса, Ответ1),
обратить( Ответ1, Ответ).
% Получить обратное истинностное значение
обратить( Цель это правда было Найдено,
( не Цель) это ложь было Найдено).
обратить( Цель это ложь было Найдено,
( не Цель) это правда было Найдено).
Если Цель конкретизирована, то все в порядке, если же нет, то возникают трудности. Рассмотрим, например, такой диалог:
?- эксперт.
Пожалуйста, спрашивайте:
не ( X ест мясо).
Есть (еще) решения для : Животное
да.
Животное = тигр.
В этот момент система даст ответ:
не ( тигр ест мясо) это ложь
Такой ответ нас не может удовлетворить. Источник затруднения следует искать в том, какой смысл мы вкладываем в вопросы типа
не ( X ест мясо)
В действительности мы хотим спросить: "Существует ли такой X, что X не ест мяса?" Однако процедура рассмотреть (так как мы ее определили) проинтерпретирует этот вопрос следующим образом:
(1) Существует ли такой X, что X ест мясо?
(2) Да, тигр ест мясо.
Итак,
(3) не (тигр ест мясо) это ложь.
Короче говоря, интерпретация такова - "Правда ли, что никакой X не ест мясо?" Положительный ответ мы получим, только если никто не ест мяса. Можно также сказать, что процедура рассмотреть
отвечает на вопрос так, как будто X находится под знаком квантора всеобщности:
для всех X: не (X ест мясо)?
а не квантора существования, в чем и состояло наше намерение:
для некоторого X: не (X ест мясо)?
Если рассматриваемый вопрос конкретизирован, то проблемы исчезают. В противном случае правильный способ работы с отрицаниями становится более сложным. Например, вот некоторые из возможных правил:
Для того, чтобы рассмотреть (не Цель), рассмотрите Цель, а затем:
если Цель это ложь, то (не Цель) это правда;
если Цель' - это некоторое решение для Цель, и Цель' - утверждение той же степени общности, что и Цель, то (не Цель) это ложь;
если Цель' - это некоторое решение для Цель, и Цель' - более конкретное утверждение, чем Цель, то об утверждении (не Цель) нельзя сказать ничего определенного.
Можно избежать всех этих осложнений, если потребовать, чтобы отрицания стояли только перед конкретизированными целями. Если правила базы знаний формулировать должным образом, то часто удается удовлетворить этому условию. Нам это удалось в "правиле поломки" (рис. 14.7):
правило_поломки:
если
вкл( Прибор) и
прибор( Прибор) и
% Конкретизация
не работает( Прибор) и
соед( Прибор, Предохр) и
доказано( цел( Предохр) )
то
доказано( неиспр( Прибор) ).
Здесь условие
прибор( Прибор)
"защищает" следующее за ним условие
не работает( Прибор)
от неконкретизированной переменной.
Декларативный и процедурный смысл программ
До сих пор во всех наших примерах всегда можно было понять результаты работы программы, точно не зная, как система в действительности их нашла. Поэтому стоит различать два уровня смысла программы на Прологе, а именно: декларативный смысл и процедурный смысл.
Декларативный смысл касается только отношений, определенных в программе. Таким образом, декларативный смысл определяет, что должно быть результатом работы программы. С другой стороны, процедурный смысл определяет еще и как этот результат был получен, т. е. как отношения реально обрабатываются пролог-системой.
Способность пролог-системы прорабатывать многие процедурные детали самостоятельно считается одним из специфических преимуществ Пролога. Это свойство побуждает программиста рассматривать декларативный смысл программы относительно независимо от ее процедурного смысла. Поскольку результаты работы программы в принципе определяются ее декларативным смыслом, последнего (Опять же в принципе) достаточно для написания программ. Этот факт имеет практическое значение, поскольку декларативные аспекты программы являются, обычно, более легкими для понимания, нежели процедурные детали. Чтобы извлечь из этого обстоятельства наибольшую пользу, программисту следует сосредоточиться главным образом на декларативном смысле и по возможности не отвлекаться на детали процесса вычислений. Последние следует в возможно большей мере предоставить самой пролог-системе.
Такой декларативный подход и в самом деле часто делает программирование на Прологе более легким, чем на таких типичных процедурно-ориентированных языках, как Паскаль. К сожалению, однако, декларативного подхода не всегда оказывается, достаточно. Далее станет ясно, что, особенно в больших программах, программист не может полностью игнорировать процедурные аспекты по соображениям эффективности вычислений. Тем не менее следует поощрять декларативный стиль мышления при написании пролог-программ, а процедурные аспекты игнорировать в тех пределах, которые устанавливаются практическими ограничениями.
Декларативный смысл пролог-программ
В главе 1 мы уже видели, что пролог-программу можно понимать по-разному: с декларативной и процедурной точек зрения. В этом и следующем разделах мы рассмотрим более формальное определение декларативного и процедурного смыслов программ базисного Пролога. Но сначала давайте еще раз взглянем на различия между этими двумя семантиками.
Рассмотрим предложение
Р :- Q, R.
где Р, Q и R имеют синтаксис термов. Приведем некоторые способы декларативной интерпретации этого предложения:
Р - истинно, если Q и R истинны.
Из Q и R следует Р.
А вот два варианта его "процедурного" прочтения:
Чтобы решить задачу Р, сначала реши подзадачу
Q, а затем - подзадачу R.
Чтобы достичь Р, сначала
достигни Q, а затем R.
Таким образом, различие между "декларативным" и "процедурным" прочтениями заключается в том, что последнее определяет не только логические связи между головой предложения и целями в его теле, но еще и порядок, в котором эти цели обрабатываются.
Формализуем теперь декларативный смысл.
Декларативный смысл программы определяет, является ли данная цель истинной (достижимой) и, если да, при каких значениях переменных она достигается. Для точного определения декларативного смысла нам потребуется понятие конкретизации предложения. Конкретизацией предложения С называется результат подстановки в него на место каждой переменной некоторого терма. Вариантом предложения С называется такая конкретизация С, при которой каждая переменная заменена на другую переменную. Например, рассмотрим предложение:
имеетребенка( X) :- родитель( X, Y).
Приведем два варианта этого предложения:
имеетребенка( А) :- родитель( А, В).
имеетребенка( X1) :- родитель( X1, Х2).
Примеры конкретизаций этого же предложения:
имеетребенка( питер) :- родитель( питер, Z).
имеетребенка( барри) :- родитель( барри,
маленькая( каролина) ).
Пусть дана некоторая программа и цель G, тогда, в соответствии с декларативной семантикой, можно утверждать, что
line(); Цель G истинна (т.е. достижима или логически следует из программы) тогда и только тогда, когда
(1) в программе существует предложение С, такое, что
(2) существует такая его (С) конкретизация I, что
(a) голова I совпадает с G и
(б) все цели в теле I истинны.
line(); Это определение можно распространить на вопросы следующим образом. В общем случае вопрос к пролог-системе представляет собой список целей, разделенных запятыми. Список целей называется истинным (достижимым), если все цели в этом списке истинны (достижимы) при одинаковых конкретизациях переменных. Значения переменных получаются из наиболее общей конкретизации.
Таким образом, запятая между целями обозначает конъюнкцию целей: они все должны быть истинными. Однако в Прологе возможна и дизъюнкция целей: должна быть истинной, по крайней мере одна из целей. Дизъюнкция обозначается точкой с запятой. Например:
Р :- Q; R.
читается так: Р - истинно, если истинно Q или истинно R. То есть смысл такого предложения тот же, что и смысл следующей пары предложений:
Р :- Q.
Р :- R.
Запятая связывает (цели) сильнее, чем точка с запятой. Таким образом, предложение
Р :- Q, R; S, Т, U.
понимается как:
Р :- ( Q, R); (S, Т, U).
и имеет тот же смысл, что и два предложения
Р :- Q, R.
Р :- S, T, U.
Добавление элемента
Наиболее простой способ добавить элемент в список - это вставить его в самое начало так, чтобы он стал его новой головой. Если Х - это новый элемент, а список, в который Х добавляется - L, тогда результирующий список - это просто
[X | L]
Таким образом, для того, чтобы добавить новый элемент в начало списка, не надо использовать никакой процедуры. Тем не менее, если мы хотим определить такую процедуру в явном виде, то ее можно представить в форме такого факта:
добавить( X, L, [X | L] ).
Добавление элемента к списку, если он в нем отсутствует (добавление без дублирования)
Часто требуется добавлять элемент Х в список L только в том случае, когда в списке еще нет такого элемента. Если же Х уже есть в L, тогда L необходимо оставить без изменения, поскольку нам не нужны лишние дубликаты X. Отношение добавить имеет три аргумента:
добавить( X, L, L1)
где Х - элемент, который нужно добавить, L - список, в который его нужно добавить, L1 - результирующий новый список. Правила добавления можно сформулировать так:
если Х принадлежит к L, то L1 = L,
иначе L1 - это список L с добавленным к нему
элементом X.
Проще всего добавлять Х в начало списка L так, чтобы Х стал головой списка L1. Запрограммировать это можно так:
добавить( X, L, L) :- принадлежит( X, L), !.
добавить( X, L, [X | L] ).
Поведение этой процедуры можно проиллюстрировать следующим примером:
?- добавить( а, [b,с], L).
L = [a, b, c]
?- до6авить( X, [b, с], L).
L = [b, с]
Х = b
?- добавить( а, [b, с, X], L).
L = [b, с, а]
Х = а
Этот пример поучителен, поскольку мы не можем легко запрограммировать "недублирующее добавление", не используя отсечения или какой-либо другой конструкции, полученной из него. Если мы уберем отсечение в только что рассмотренной программе, то отношение добавить будет добавлять дубликаты элементов, уже имеющихся в списке. Например:
?- добавить( a, [a, b, c], L),
L = [а, b, с]
L = [а, а, b, с]
Поэтому отсечение требуется здесь для правильного определения отношения, а не только для повышения эффективности. Этот момент иллюстрируется также и следующим примером.
Драйвер верхнего уровня
И наконец, для того, чтобы иметь удобный доступ к оболочке из интерпретатора Пролога, нам необходима процедура, выполняющая функцию "драйвера". На рис. 14.13 показано, как могла бы выглядеть предназначенная для этой цели процедура эксперт. Драйвер эксперт производит запуск трех основных модулей оболочки (рис. 14.10 - 14.12) и координирует их работу. Например:
line();% Выдача заключения консультационного сеанса и
% объяснения типа "как"
выдать( Ответ) :-
nl, заключение( Ответ),
nl, write( 'Хотите узнать, как?'),
принять( Ответ1),
( Ответ1 = да, !, отобр( Ответ);
true).
% Показ решающего дерева
заключение( Ответ1 и Ответ2) :- !,
заключение( Ответ1), write( 'и'),
заключение( Ответ2).
заключение( Заключение было Найдено) :-
write( Заключение).
% "отобр" отображает полное решающее дерево
отобр( Решение) :-
nl, отобр( Решение, 0), !. % Отступ 0
отобр( Ответ1 и Ответ2, Н) :- !, % Отступ Н
отобр( Ответ1, Н),
tab( H), write( 'и'), nl,
отобр( Ответ2, Н).
отобр( Ответ был Найден, Н) :- % Отступ Н
tab( H), печответ( Ответ), % Показ заключения
nl, tab( H),
write( 'было'),
отобр1( Найден, Н). % Показ доказательства
отобр1( Выведено из Ответ, Н) :- !,
write( Выведено), write( 'из'), % Показ имени правила
nl, H1 is H + 4,
отобр( Ответ, H1). % Показ "предшественника"
отобр1( Найдено, _ ) :-
% Найдено = 'сказано' или 'найдено как факт'
write( Найдено), nl.
печответ( Цель это правда) :- !,
write( Цель). % На выходе 'это правда' опускается
печответ( Ответ) :- % Отрицательный ответ
write( Ответ).
line(); Рис. 14. 12. Оболочка экспертной системы:
Отображение окончательного результата и
объяснение типа "как".
?- эксперт.
Пожалуйста, спрашивайте: % Приглашение пользователю
X это животное и голиаф это Х. % Вопрос пользователя
Это правда: голиаф имеет шерсть?
. . .
Древовидное представление множества кандидатов
Рассмотрим теперь еще одно изменение нашей программы поиска в ширину. До сих пор мы представляли множества путей-кандидатов как списки путей. Это расточительный способ, поскольку начальные участки путей являются общими для нескольких из них. Таким образом, эти общие части путей приходится хранить во многих экземплярах. Избежать избыточности помогло бы более компактное представление множества кандидатов. Таким более компактным представлением является дерево, в котором общие участки путей хранятся в его верхней части без дублирования. Будем использовать в программе следующее представление дерева. Имеется два случая:
Случай 1: Дерево состоит только из одной вершины В; В этом случае оно имеет вид терма л( В); Функтор л указывает на то, что В - это лист дерева.
Случай 2: Дерево состоит из корневой вершины В и множества поддеревьев Д1, Д2, ... . Такое дерево представляется термом
д( В, Пд)
где Пд - список поддеревьев:
Пд = [ Д1, Д2, ...]
В качестве примера рассмотрим ситуацию, которая возникает после того, как порождены три уровня дерева рис. 11.9. Множество путей-кандидатов в случае спискового представления имеет вид:
[ [d, b, a], [e, b, а], [f, c, a], [g, c, a] ]
В виде дерева это множество выглядит так:
д( а, [д( b, [л( d), л( е)] ), д( с, [л( f), л( g)] )] )
На первый взгляд древовидное представление кажется еще более расточительным, чем списковое, однако это всего лишь поверхностное впечатление, связанное с компактностью прологовской нотации для списков.
В случае спискового представления множества кандидатов эффект распространения процесса в ширину достигался за счет перемещения продолженных путей в конец списка.
В нашем случае мы уже не можем использовать этот прием, поэтому программа несколько усложняется. Ключевую роль в нашей программе будет играть отношение
расширить( Путь, Дер, Дер1, ЕстьРеш, Решение)
На рис. 11.12 показано, как связаны между собой аргументы отношения расширить. При каждом обращении к расширить
переменные Путь и Дер будут уже конкретизированы. Дер - поддерево всего дерева поиска, одновременно оно служит для представления множества путей-кандидатов внутри этого поддерева. Путь - это путь, ведущий из стартовой вершины в корень поддерева Дер. Самая общая идея алгоритма -
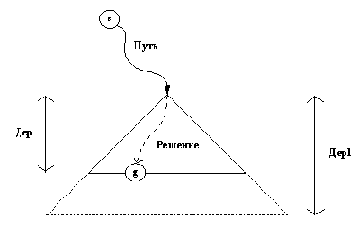
Рис. 11. 12. Отношение paсширить( Путь, Дер, Дер1, ЕстьРеш, Решение):
s - стартовая вершина, g - целевая вершина. Решение - это Путь,
продолженный вплоть до g. Дер1 - результат расширения дерева
Дер на один уровень вниз.
получить поддерево Дер1 как результат расширения Дер на один уровень. Но в случае, когда в процессе расширения поддерева Дер встретится целевая вершина, процедура расширить должна сформировать соответствующий решающий путь.
Итак, процедура расширить будет порождать два типа результатов. На конкретный вид результата будет указывать значение переменной ЕстьРеш:
(1) ЕстьРеш = да
Решение = решающий путь, т. е. Путь, продолженный до целевой вершины.
Дер1 = неконкретизировано.
Разумеется, такой тип результата получится только в том случае, когда Дер будет содержать целевую вершину. Добавим также, что эта целевая вершина обязана быть листом поддерева Дер.
(2) ЕстьРеш = нет
Дер1 = результат расширения поддерева Дер на один уровень вниз от своего "подножья". Дер1 не содержит ни одной "тупиковой" ветви из Дер, т.
е. такой ветви, что она либо не может быть продолжена из-за отсутствия преемников, либо любое ее продолжение приводит к циклу.
Решение = неконкретизировано.
Если в дереве Дер нет ни одной целевой вершины и, кроме того, оно не может быть расширено, то процедура расширить терпит неудачу.
Процедура верхнего уровня для поиска в ширину
вширину( Дер, Решение)
отыскивает Решение либо среди множества кандидатов Дер, либо в его расширении. На рис. 11.3 показано, как выглядит программа целиком. В этой программе имеется вспомогательная процедура расширитьвсе. Она расширяет все деревья из некоторого списка, и затем, выбросив все "тупиковые" деревья", собирает все полученные расширенные деревья в один новый список. Используя механизм возвратов, она также порождает все решения, обнаруженные в деревьях из списка. Имеется одна дополнительная деталь: по крайней мере одно из деревьев должно "вырасти". Если это не так, то процедуре расширитьвсе не удается получить ни одного расширенного дерева - все деревья из списка оказываются "тупиковыми".
line(); % ПОИСК В ШИРИНУ
% Множество кандидатов представлено деревом
решить( Старт, Решение) :-
вширину( л( Старт), Решение).
вширину( Дер, Решение) :-
расширить( [ ], Дер, Дер1, ЕстьРеш, Решение),
( ЕстьРеш = да;
ЕстьРеш = нет, вширину( Дер1, Решение) ).
расширить( П, Л( В), _, да, [В | П] ) :-
цель( В).
расширить( П, Л( В), д( В, Пд), нет, _ ) :-
bagof( л( B1),
( после( В, B1), not принадлежит( В1, П)), Пд).
расширить( П, д( В, Пд), д( В, Пд1), ЕстьРеш, Реш) :-
расширитьвсе( [В | П], Пд, [ ], Пд1, ЕстьРеш, Реш).
расширитьвсе( _, [ ], [Д | ДД], [Д | ДД], нет, _ ).
% По крайней мере одно дерево должно вырасти
расширитьвсе( П, [Д | ДД], ДД1, Пд1, ЕстьРеш, Реш) :-
расширить ( П, Д, Д1, ЕстьРеш1, Реш),
( ЕстьРеш 1= да, ЕстьРеш = да;
ЕстьРеш1 = нет, !,
расширитьвсе( П, ДД, [Д1 | ДД1], Пд1, ЕстьРеш, Реш));
расширитьвсе( П, ДД, ДД1, Пд1, ЕстьРеш, Реш ).
line(); Рис. 11. 13. Реализация поиска в ширину с использованием
древовидного представления множества путей-кандидатов.
Мы разработали эту более сложную реализацию поиска в ширину не только для того, чтобы получать программу более экономичную по сравнению с предыдущей версией, но также и потому, что такое решение задачи может послужить хорошим стартом для перехода к усложненным программам поиска, управляемым эвристиками, таким как программа поиска с предпочтением из гл. 12.
ДРУГИЕ ВСТРОЕННЫЕ ПРОЦЕДУРЫ
В данной главе мы изучим некоторые другие, не упоминавшиеся ранее встроенные процедуры, предназначенные для более серьезного программирования на Прологе. Эта новые процедуры дают возможность запрограммировать операции, которые известными нам средствами запрограммировать невозможно. Один набор таких процедур касается обработки термов: эти процедуры проверяют, была ли некоторая переменная конкретизирована целым числом, они разбирают термы на части, конструируют новые термы и т.д. Другой полезный набор процедур работает с "базой данных": процедуры из этого набора добавляют новые отношения в программу или удаляют из нее существующие.
Множество встроенных процедур сильно зависит от конкретной реализации Пролога. Однако процедуры, обсуждаемые в данной главе, имеются во многих реализациях. Различные реализации могут иметь свои наборы дополнительных средств.
double_line();Двоично - троичные справочники
Двоичное дерево называют хорошо сбалансированным, если оба его поддерева имеют примерно одинаковую глубину (или размер) и сами сбалансированы. Глубина сбалансированного дерева приближенно равна log n , где n - число вершин дерева. Время, необходимое для вычислений, производимых отношениями внутри, добавить и удалить над двоичными справочниками, пропорционально глубине дерева. Таким образом, в случае двоичных справочников это время имеет порядок log n. Логарифмический рост сложности алгоритма, проверяющего принадлежность элемента множеству, - это определенное достижение по сравнению со списковым представлением, поскольку в последнем случае мы имеем линейный рост сложности

Рис. 10. 1. Полностью разбалансированный двоичный справочник.
Производительность его та же, что и у списка.
с ростом размера множества. Однако плохая сбалансированность дерева ведет к деградации производительности алгоритмов, работающие со справочником. В крайнем случае, двоичный справочник вырождается в список, как показано на рис.10. l. Форма справочника зависит от той последовательности, а которой в всего записываются элементы данных. В лучшей случае мы получаем хорошую балансировку и производительность порядка log n, а в худшем - производительность будет порядка n. Анализ показывает, что в среднем сложность алгоритмов внутри, добавить и удалить сохраняет порядок log n в допущении, что все возможные входные последовательности равновероятны. Таким образом, средняя производительность, к счастью, оказывается ближе к лучшему случаю, чек к худшему. Существует, однако, несколько довольно простых механизмов, которые поддерживают хорошую сбалансированность дерева, вне зависимости от входной последовательности, формирующей дерево. Эти механизмы гарантируют производительность алгоритмов внутри, добавить и удалить порядка log n даже в худшем случае. Один из этих механизмов - двоично-троичные деревья (кратко, 2-3 деревья), а другой - AVL-деревья.
2-3 дерево определяется следующим образом: оно или пусто, или состоит из единственной вершины, или удовлетворяет следующим условиям: каждая внутренняя вершина имеет две или три дочерних вершины, и все листья дерева находятся на одном и том же уровне.
Двоично-троичным (2-3) справочником называется 2-3 дерево, все элементы данных которого хранятся в листьях и упорядочены слева направо.
На рис. 10. 2 показан пример. Внутренние вершины содержат метки, равные минимальным элементам тех или иных своих поддеревьев, в соответствии со следующими правилами:
если внутренняя вершина имеет два поддерева, то она содержит минимальный элемент второго из них;
если внутренняя вершина имеет три поддерева, то она содержит минимальные элементы второго и третьего поддеревьев.
Рис. 10. 2. 2-3 справочник. Отмеченный путь показывает процесс поиска элемента 10.
При поиске элемента Х в 2-3 справочнике мы начинаем с корня и двигаемся в направлении самого нижнего уровня, руководствуясь при этом метками внутренних вершин дерева. Пусть корень содержит метки Ml и М2, тогда если Х < M1, то поиск продолжается в левом поддереве, иначе если Х < М2, то поиск продолжается в среднем поддереве, иначе - в правом поддереве. Если в корне находится только одна метка М, то переходим к левому поддереву при Х < М и к правому поддереву - в противоположном случае. Продолжаем применять сформулированные выше правила, пока не окажемся на самом нижнем уровне дерева, где и выяснится, найден ли элемент X, или же поиск потерпел неудачу.
Так как все листья 2-3 дерева находятся на одном и том же уровне, 2-3 дерево идеально сбалансировано с точки зрения глубины составляющих его поддеревьев. Все пути от корня до листа, которые мы проходим при поиске, имеют одну и ту же длину порядка log n, где n - число элементов, хранящихся в дереве.
При добавлении нового элемента данных 2-3 дерево может расти не только в глубину, но и в ширину. Каждая внутренняя вершина, имеющая два поддерева, может приобрести новое поддерево, что приводит к росту вширь. Если же, с другой стороны, у вершины уже есть три поддерева, и она должна принять еще одно, то она расщепляется на две вершины, каждая из которых берет на себя по два из имеющихся четырех поддеревьев. Образовавшаяся при этом новая вершина передается вверх по дереву для присоединения к одной из выше расположенных вершин. Если же эта ситуация возникает на самом высоком уровне, то дерево вынуждено "вырасти" на один уровень вверх.
Рис. 10.3 иллюстрирует описанный принцип.
Рис. 10. 3. Вставление нового элемента в 2-3 справочник. Дерево
растет сначала вширь, а затем уже вглубь.
Включение нового элемента в 2- 3 справочник мы запрограммируем как отношение
доб23( Дер, X, НовДер)
где дерево НовДер получено введением элемента Х в дерево Дер. Основную работу мы поручим двум дополнительным отношениям, которые мы назовем встав. Первое из них имеет три аргумента:
встав( Дер, X, НовДер).
Здесь НовДер - результат вставления элемента Х в Дер. Деревья Дер и НовДер имеют одну и ту же глубину. Разумеется, не всегда возможно сохранить ту же глубину дерева. Поэтому существует еще одно отношение с пятью аргументами специально для этого случая:
встав( Дер, X, НДа, Mб, НДб).
Имеется в виду, что при вставления Х в Дер дерево Дер разбивается на два дерева НДа и НДб, имеющих ту же глубину, что и Дер. Мб - это минимальный элемент из НДб. Пример показан на рис. 10.4.

Рис. 10. 4. Объекты, показанные на рисунке, удовлетворяют отношению встав( Дер, 6, НДа, Мб, НДб).
2-3 деревья мы будем представлять в программе следующим образом: nil представляет пустое дерево; л( Х) представляет дерево, состоящее из одной вершины - листа с элементом X; в2( Д1, М, Д2) представляет дерево с двумя поддеревьями Д1 и Д2; М - минимальный элемент из Д2; в3( Д1, М2, Д2, М3, Д3) представляет дерево с тремя поддеревьями Д1, Д2 и Д3; М2 - минимальный элемент из Д2; М3 - минимальный элемент из Д3; Д1, Д2 и Д3 - 2-3 деревья. Между доб23 и встав существует следующая связь: если после вставления нового элемента дерево не "вырастает", то
доб23( Дер, X, НовДер) :-
встав( Дер, X, НовДер).
Однако если после вставления элемента глубина дерева увеличивается, то встав порождает два поддерева Д1 и Д2, а затем составляет из них дерево большей глубины:
доб23( Дер, X, в2( Д1, М, Д2) ) :-
встав( Дер, X, Д1, М, Д2).
Отношение встав устроено более сложным образом, поскольку ему приходится иметь дело со многими случаями, а именно вставление в пустое дерево, в дерево, состоящее из одного листа, и в деревья типов в2 и в3. Возникают также дополнительные подслучаи, так как новый элемент можно вставить в первое, либо во второе, либо в третье поддерево. В связи с этим мы определим встав как набор правил таким образом, чтобы каждое предложение процедуры встав имело дело с одним из этих случаев. На рис. 10.5 показаны некоторые из возможных случаев. На Пролог они транслируются следующим образом:
Случай а
встав( в2( Д1, М, Д2), X, в2( НД1, М, Д2) ) :-
больше( М, X), % М больше, чем Х
встав( Д1, X, НД1).
Случай b
встав( в2( Д1, M, Д2), X, в3( НД1а, Мб, НД1б, M, Д2) ) :-
больше( М, X),
встав( Д1, X, НД1а, Мб, НД1б).
Случай с
встав( в3( Д1, М2, Д2, М3, Д3), X, в2( НД1а, Мб, НД1б), М2, в2(Д2, М3, Д3) ) :-
больше( М2, X),
встав( Д1, X, НД1а, Мб, НД1б).
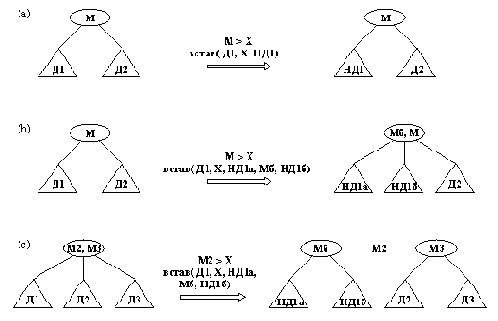
Рис. 10. 5. Некоторые из случаев работы отношения встав.
(a) встав( в2( Д1, М, Д2), X, в2( НД1, М, Д2) );
(b) встав( в2( Д1, М, Д2), X,
в3( НД1а, Мб, НД1б, М, Д2) );
(c) встав( в3( Д1, М2, Д2, М3, Д3), X,
в2( НД1а, Мб, НД1б), М2, в2( Д2, М3, Д3) ).
line(); % Вставление элемента в 2-3 справочник
доб23( Дер, X, Дер1) :- % Вставить Х в Дер, получить Дер1
встав( Дер, X, Дер1). % Дерево растет вширь
доб23( Дер, X, в2( Д1, М2, Д2) ) :-
встав( Дер, X, Д1, М2, Д2). % Дерево растет вглубь
доб23( nil, X, л( Х) ).
встав( л( А), X, л( А), X, л( Х) ) :-
больше( X, А).
встав( л( А), X, л( Х), А, л( А) ) :-
больше( А, X).
встав( в2( Д1, М, Д2), X, в2( НД1, М, Д2) ) :-
больше( М, X),
встав( Д1, X, НД1).
встав( в2( Д1, М, Д2), Х, в3( НД1а, Мб, НД1б, М, Д2) ) :-
больше( М, X),
встав( Д1, X, НД1а, Мб, НД1б).
встав( в2( Д1, М, Д2), X, в2( Д1, М, НД2) ) :-
больше( X, М),
встав( Д2, X, НД2).
встав( в2( Д1, М, Д2), Х, в3( Д1, М, НД2а, Мб, НД2б) ) :-
больше( X, М),
встав( Д2, X, НД2а, Мб, НД2б).
встав( в3( Д1, М2, Д2, М3, Д3), Х, в3( НД1, М2, Д2, М3, Д3) :-
больше( М2, X),
встав( Д1, X, НД1).
встав( в3( Д1, М2, Д2, М3, Д3), X,
в2( НД1а, Мб, НД1б), М2, в2( Д2, М3, Д3) ) :-
больше( М2, X),
встав( Д1, X, НД1а, Мб, НД1б).
встав( в3( Д1, М2, Д2, М3, Д3), X,
в3( Д1, М2, НД2, М3, Д3) ) :-
больше( X, М2), больше( М3, X),
встав( Д2, X, НД2).
встав( в3( Д1, М2, Д2, М3, Д3), X,
в2( Д1, М2, НД2а), Мб, в2( НД2б, М3, Д3) ) :-
больше( X, М2), больше( М3, X),
встав( Д2, X, НД2а, Мб, НД2б).
встав( в3( Д1, М2, Д2, М3, Д3), X,
в3( Д1, М2, Д2, М3, НД3) ) :-
больше( X, М3),
встав( Д3, X, НД3).
встав( в3( Д1, М2, Д2, М3, Д3), X,
в2( Д1, М2, Д2), М3, в2( НД3а, Мб, НД3б) ) :-
больше( X, М3),
встав( Д3, X, НД3а, Мб, НД3б).
line(); Рис. 10. 6. Вставление элемента в 2-3 справочник. В этой
программе предусмотрено, что попытка повторного
вставления элемента терпит неудачу.
Программа для вставления нового элемента в 2-3 справочник показана полностью на рис. 10.6. На рис. 10.7 показана программа вывода на печать 2-3 деревьев.
Наша программа иногда выполняет лишние возвраты. Так, если встав с тремя аргументами терпит неудачу, то вызывается процедура встав с пятью аргументами, которая часть работы делает повторно. Можно устранить источник неэффективности, если, например, переопределить встав как
встав2( Дер, X, Деревья)
где Деревья - список, состоящий либо из одного, либо из трех аргументов:
Деревья = [ НовДер], если встав( Дер, X, НовДер)
Деревья = [ НДа, Мб, НДб],
если встав( Дер, X, НДа, Мб, НДб)
Теперь отношение доб23 можно переопределить так:
доб23( Д, X, Д1) :-
встав( Д, X, Деревья),
соединить( Деревья, Д1).
Отношение соединить формирует одно дерево Д1 из деревьев, находящихся в списке Деревья.
Двоичные справочники: добавление и удаление элемента
Если мы имеем дело с динамически изменяемым множеством элементов данных, то нам может понадобиться внести в него новый элемент или удалить из него один из старых. В связи с этим набор основных операций, выполняемых над множеством S, таков:
внутри( X, S) % Х содержится в S
добавить( S, X, S1) % Добавить Х к S, результат - S1
удалить( S, X, S1) % Удалить Х из S, результат - S1

Рис. 9. 9. Введение в двоичный справочник нового элемента на уровне листьев. Показанные деревья соответствуют следующей последовательности вставок:
добавить( Д1, 6, Д2), добавить( Д2, 6, Д3), добавить( Д3, 6, Д4)
доблист( nil, X, дер( nil, X, nil) ).
доблист( дер( Лев, Х, Прав), Х, дер( Лев, Х, Прав) ).
доблист( дер( Лев, Кор, Прав), Х, дер( Лев1, Кор, Прав)) :-
больше( Кор, X),
доблист( Лев, X, Лев1)).
доблист( дер( Лев, Кор, Прав), Х, дер( Лев, Кор, Прав1)) :-
больше( X, Кор),
доблист( Прав, X, Прав1).
Рис. 9. 10. Вставление в двоичный справочник нового элемента в качестве листа.
Определим отношение добавить. Простейший способ: ввести новый элемент на самый нижний уровень дерева, так что он станет его листом. Место, на которое помещается новый элемент, выбрать таким образом, чтобы не нарушить упорядоченность дерева. На рис. 9.9 показано, какие изменения претерпевает дерево в процессе введения в него новых элементов. Назовем такой метод вставления элемента в множество
доблист( Д, X, Д1)
Правила добавления элемента на уровне листьев таковы: Результат добавления элемента Х к пустому дереву есть дерево дер( nil, X, nil). Если Х совпадает с корнем дерева Д, то Д1 = Д (в множестве не допускается дублирования элементов). Если корень дерева Д больше, чем X, то Х вносится в левое поддерево дерева Д; если корень меньше, чем X, то Х вносится в правое поддерево. На рис. 9.10 показана соответствующая программа.
Теперь рассмотрим операцию удалить. Лист дерева удалить легко, однако удалить какую-либо внутреннюю вершину - дело не простое. Удаление листа можно на самом деле определить как операцию, обратную
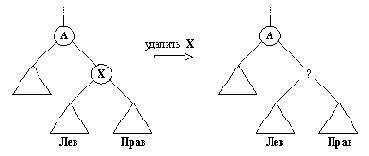
Рис. 9. 11. Удаление X из двоичного справочника. Возникает проблема наложения "заплаты" на место удаленного элемента X.
операции добавления листа:
удлист( Д1, X, Д2) :-
доблист( Д2, X, Д1).
К сожалению, если Х - это внутренняя вершина, то такой способ не работает, поскольку возникает проблема, иллюстрацией к которой служит рис. 9.11. Вершина Х имеет два поддерева Лев и Прав. После удаления вершины Х в дереве образуется "дыра", и поддеревья Лев и Прав теряют свою связь с остальной частью дерева. К вершине А оба эти поддерева присоединить невозможно, так как вершина А способна принять только одно из них.
Если одно из поддеревьев Лев и Прав пусто, то существует простое решение: подсоединить к А непустое поддерево. Если же оба поддерева непусты,
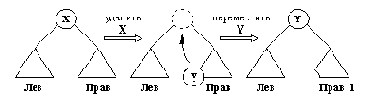
Рис. 9. 12. Заполнение пустого места после удаления X.
то можно использовать следующую идею (рис. 9.12): если самую левую вершину Y поддерева Прав переместить из ее текущего положения вверх и заполнить ею пробел, оставшийся после X, то упорядоченность дерева не нарушится. Разумеется, та же идея сработает и в симметричном случае, когда перемещается самая правая вершина поддерева Лев.
На рис. 9.13 показана программа, реализующая операцию удаления элементов в соответствии с изложенными выше соображениями. Основную работу по перемещению самой левой вершины выполняет отношение
удмин( Дер, Y, Дер1)
Здесь Y - минимальная (т.е. самая левая) вершина дерева Дер, а Дер1 - то, во что превращается дерево Дер после удаления вершины Y.
Существует другой, элегантный способ реализация операции добавить и удалить. Отношение добавить можно сделать недетерминированным в том смысле, что новый элемент вводится на произвольный уровень дерева, а не только на уровень листьев. Правила таковы:
line(); уд( дер( nil, X, Прав), X, Прав).
уд( дер( Лев, X, nil), X, Лев).
уд( дер( Лев, Х, Прав), X, дер( Лев,Y, Прав1) ) :-
удмин( Прав, Y, Прав1).
уд( дер( Лев, Кор, Прав), X, дер( Лев1, Кор, Прав) ) :-
больше( Кор, X),
уд( Лев, X, Лев1).
уд( дер( Лев, Кор, Прав), X, дер( Лев, Кор, Прав1) ) :-
больше( X, Кор),
уд( Прав, X, Прав1).
удмин( дер( nil, Y, Прав), Y, Прав).
удмин( дер( Лев, Кор, Прав), Y, дер( Лев1, Кор, Прав) ) :-
удмин( Лев, Y, Лев1).
line(); Рис. 9. 13. Удаление элемента из двоичного справочника.
line(); Для того, чтобы добавить Х в двоичный справочник Д, необходимо одно из двух: добавить Х на место корня дерева (так, что Х станет новым корнем) или если корень больше, чем X, то внести Х в левое поддерево, иначе - в правое поддерево. line(); Трудным моментом здесь является введение Х на место корня. Сформулируем эту операций в виде отношения
добкор( Д, X, X1)
где Х - новый элемент, вставляемый вместо корня в Д, а Д1 - новый справочник с корнем Х. На рис. 9.14 показано, как соотносятся X, Д и Д1. Остается вопрос: что из себя представляют поддеревья L1 и L2 (или, соответственно, R1 и R2) на рис. 9.14?
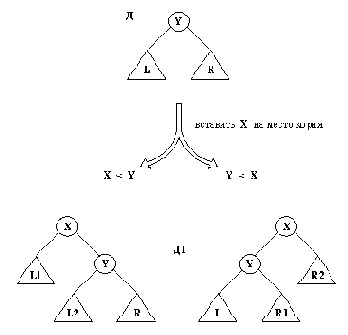
Рис. 9. 14. Внесение Х в двоичный справочник в качестве корня.
Ответ мы получим, если учтем следующие ограничения на L1, L2: L1 и L2 - двоичные справочники; множество всех вершин, содержащихся как в L1, так и в L2, совпадает с множеством вершин справочника L; все вершины из L1 меньше, чем X; все вершены из L2 больше, чем X. Отношение, которое способно наложить все эти ограничения на L1, L2, - это как раз и есть наше отношение добкор. Действительно, если бы мы вводили Х в L на место корня, то поддеревьями результирующего дерева как раз и оказались бы L1 и L2. В терминах Пролога L1 и L2 должны быть такими, чтобы достигалась цель
добкор( L, X, дер( L1, X, L2) ).
Те же самые ограничения применимы к R1, R2:
добкор( R, X, дер( R1, X, R2) ).
line(); добавить( Д, X, Д1) :- % Добавить Х на место корня
добкор( Д, X, Д1).
добавить( дер( L, Y, R), X, дер( L1, Y, R) ) :-
больше( Y, X), % Ввести Х в левое поддерево
добавить( L, X, L1).
добавить( дер( L, Y, R), X, дер( L, Y, R1) ) :-
больше( X, Y), % Ввести Х в правое поддерево
добавить( R, X, R1).
добкор( nil, X, дер( nil, X, nil) ). % Ввести Х в пустое дерево
добкор( дер( L, Y, R), Х, дер( L1, Х, дер( L2, Y, R) )) :-
больше( Y, X),
добкор( L, X, дер( L1, X, L2) ).
добкор( дep( L, Y, R), X, дep( дep( L, Y, R1), X, R2) ) :-
больше( X, Y),
добкор( R, X, дер( R1, X, R2) ).
line(); Рис. 9. 15. Внесение элемента на произвольный уровень двоичного справочника.
На рис. 9.15 показана программа для "недетерминированного" добавления элемента в двоичный справочник.
Эта процедура обладает тем замечательным свойством, что в нее не заложено никаких ограничений на уровень дерева, в который вносится новый элемент. В связи с этим операцию добавить можно использовать "в обратном направлении" для удаления элемента из справочника. Например, приведенная ниже последовательность целей строит справочник Д, содержащий элементы 3, 5, 1, 6, а затем удаляет из него элемент 5, после чего получается справочник ДД:
добавить( nil, 3, Д1), добавить( Д1, 5, Д2),
добавить( Д2, 1, Д3), добавить( Д3, 6, Д),
добавить( ДД, 5, Д).
Назад | Содержание | Вперёд
Формирование ответа на вопрос "как"
Получив ответ на свой вопрос, пользователь возможно захочет увидеть, как система пришла к такому заключению. Один из подходящих способов ответить на вопрос "как" - это представить доказательство, т. е. те правила и подцели, которые использовались для достижения полученного заключения. Это доказательство в случае нашего языка записи правил имеет вид решающего И / ИЛИ-дерева. Поэтому наша машина логического вывода будет не просто отвечать на вопрос, соответствующий цели самого верхнего уровня - этого нам недостаточно, а будет выдавать в качестве ответа решающее И / ИЛИ-дерево, составленное из имен правил и подцелей. Затем это дерево можно будет отобразить на выходе системы в качестве объяснения типа "как". Объяснению можно придать удобную для восприятия форму, если каждое поддерево печатать с надлежащим отступом, например:
питер это хищник
было выведено по прав3 из
питер это млекопитающее
было выведено по прав1 из
питер имеет шерсть
было сказано
и
питер ест мясо
было сказано
Назад | Содержание | Вперёд
Формирование ответа на вопрос "почему"
Вопрос "почему" возникает в ситуации, когда система просит пользователя сообщить ей некоторую информацию, а пользователь желает знать, почему эта информация необходима. Допустим, что система спрашивает:
а - это правда?
В ответ пользователь может спросить:
почему?
Объяснение в этом случае выглядит примерно так:
Потому, что
Я могу использовать а,
чтобы проверить по правилу Па, что b, и
Я могу использовать b,
чтобы проверить по правилу Пb, что с, и
Я могу использовать с,
чтобы проверить по правилу Пc, что d, и
. . .
Я могу использовать y,
чтобы проверить по правилу Пy, что z, и
z - это ваш исходный вопрос.
Объяснение - это демонстрация того, как система намерена использовать информацию, которую она хочет получить от пользователя. Намерения системы демонстрируются в виде цепочки правил и целей, соединяющей эту информацию с исходным вопросом.
Рис. 14. 8. Объяснение типа "почему". На вопрос "Почему вас интересует
текущая цель?" дается объяснение в виде цепочки правил и целей,
соединяющей текущую цель с исходным вопросом пользователя,
находящимся в верхушке дерева. Эта цепочка называется трассой.
Будем называть такую цепочку трассой. Трассу можно себе представлять как цепочку правил, соединяющую в И / ИЛИ-дереве вопросов текущую цель с целью самого верхнего уровня так, как это показано на рис. 14.8. Таким образом, для формирования ответа на вопрос "почему" нужно двигаться в пространстве поиска от текущей цели вверх вплоть до самой верхней цели. Для того, чтобы суметь это сделать, нам придется в процессе рассуждений сохранять трассу в явном виде.
Формирование термов
Предположим, наша программа имеет дело с семьями, которые представлены в виде термов так, как это сделано в гл. 4 (рис. 4.1). Тогда, если, перемен-
line(); родители
том фокс, датарожд 7 май 1950, работает bbс,
оклад 15200
энн фокс, датарожд 9 май 1951, неработает
дети
пат фокс, датарожд 5 май 1973, неработает
джим фокс, датарожд 5 май 1973, неработает
Рис. 6. 2. Улучшенный формат вывода термов, представляющих семью.
ная F конкретизирована термом, изображенный на рис. 4.1, то цель
write( F)
вызовет вывод этого терма в стандартной форме примерно так:
семья( членсемьи( том, фокс, дата( 7, май,1950),
работает( bbс, 15200)),
членсемьи( энн, фокс, дата( 9, май, 1951),
неработает),
[членсемьи( пат, фокс, дата( 5, май, 1973),
неработает),
членсемьи( джим, фокс, дата( 5, май, 1973),
неработает)])
Здесь содержится полная информация, однако форма представления легко может запутать, поскольку трудно проследить, какие ее части образуют самостоятельные семантические единицы. Поэтому обычно предпочитают выводить такую информацию в каком-либо формате, например так, как показано на рис. 6.2. Процедура
вывсемью( F)
с помощью которой это достигается, приведена на рис. 6.3.
line();
вывсемью( семья ( Муж, Жена, Дети) :-
nl, write( родители), nl, nl,
вывчленсемьи( Муж), nl,
вывчленсемьи( Жена), nl, nl,
write( дети), nl, nl,
вывчленсемьи( Дети).
вывчленсемьи( членсемьи( Имя, Фамилия, дата( Д, М, Г), Работа) ) :-
tab(4), write( Имя),
tab(1), write( Фамилия),
write( ', дата рождения'),
write( Д), tab( 1),
write( M), tab( 1),
write( Г), write( ','),
вывработу( Работа).
вывсписчлсемьи( [ ]).
вывсписчлсемьи( [Р | L]) :-
вывчленсемьи( Р), nl,
вывсписчлсемьи( L),
вывработу( неработает) :-
write( неработает).
вывработу( работает Место, Оклад) ) :-
write(' работает '), write( Место),
write( ', оклад '), write( Оклад).
line();
Рис. 6. 3. Программа, обеспечивающая вывод в формате, представленном на рис. 6.2.
Формулировка игровых задач в терминах И / ИЛИ-графов
Такие игры, как шахматы или шашки, естественно рассматривать как задачи, представленные И / ИЛИ-графами. Игры такого рода называются играми двух лиц с полной информацией. Будем считать, что существует только два возможных исхода игры: ВЫИГРЫШ и ПРОИГРЫШ. (Об играх с тремя возможными исходами -ВЫИГРЫШ, ПРОИГРЫШ и НИЧЬЯ, можно также говорить, что они имеют только два исхода: ВЫИГРЫШ и НЕВЫИГРЫШ). Так как участники игры ходят по очереди, мы имеем два вида позиций, в зависимости от того, чей ход. Давайте условимся называть участников игры "игрок" и "противник", тогда мы будем иметь следующие два вида позиций: позиция с ходом игрока ("позиция игрока") и позиция с ходом противника ("позиция противника"). Допустим также, что начальная позиция Р - это позиция игрока. Каждый вариант хода игрока в этой позиции приводит к одной из позиций противника Q1, Q2, Q3, ... (см. рис. 13.7). Далее каждый вариант хода противника в позиции Q1 приводит к одной из позиций игрока R11, R12, ... . В И / ИЛИ-дереве, показанном на рис. 13.7, вершины соответствуют позициям, а дуги - возможным ходам. Уровни позиций игрока чередуются в дереве с уровнями позиций противника. Для того, чтобы выиграть в позиции Р, нужно найти ход, переводящий Р в выигранную позицию Qi. (при некотором i). Таким образом, игрок выигрывает в позиции Р, если он выигрывает в Q1, или Q2, или Q3, или ... . Следовательно, Р - это ИЛИ-вершина. Для любого i позиция Qi - это позиция противника, поэтому если в этой позиции выигрывает игрок, то он выигрывает и после каждого вариан-
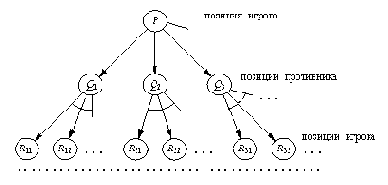
Рис. 13. 7. Формулировка игровой задачи для игры двух лиц в
форме И / ИЛИ-дерева; участники игры: "игрок" и "противник".
та хода противника. Другими словами, игрок выигрывает в Qi, если он выигрывает во всех позициях Ri1 и Ri2 и ... . Таким образом, все позиции противника - это И-вершины. Целевые вершины - это позиции, выигранные согласно правилам игры, например позиции, в которых король противника получает мат. Позициям проигранным соответствуют задачи, не имеющие решения. Для того, чтобы решить игровую задачу, мы должны построить решающее дерево, гарантирующее победу игрока независимо от ответов противника. Такое дерево задает полную стратегию достижения выигрыша: для каждого возможного продолжения, выбранного противником, в дереве стратегии есть ответный ход, приводящий к победе.
Назад | Содержание | Вперёд
Функции, выполняемые экспертной системой
Экспертная система - это программа, которая ведет себя подобно эксперту в некоторой, обычно узкой, прикладной области. Типичные применения экспертных систем включают в себя такие задачи, как медицинская диагностика, локализация неисправностей в оборудовании и интерпретация результатов измерений. Экспертные системы должны решать задачи, требующие для своего решения экспертных знаний в некоторой конкретной области. В той или иной форме экспертные системы должны обладать этими знаниями. Поэтому их также называют системами, основанными на знаниях. Однако не всякую систему, основанную на знаниях, можно рассматривать как экспертную. Экспертная система должна также уметь каким-то образом объяснять свое поведение и свои решения пользователю, так же, как это делает эксперт-человек. Это особенно необходимо в областях, для которых характерна неопределенность, неточность информации (например, в медицинской диагностике). В этих случаях способность к объяснению нужна для того, чтобы повысить степень доверия пользователя к советам системы, а также для того, чтобы дать возможность пользователю обнаружить возможный дефект в рассуждениях системы. В связи с этим в экспертных системах следует предусматривать дружественное взаимодействие с пользователем, которое делает для пользователя процесс рассуждения системы "прозрачным".
Часто к экспертным системам предъявляют дополнительное требование - способность иметь дело с неопределенностью и неполнотой. Информация о поставленной задаче может быть неполной или ненадежной; отношения между объектами предметной области могут быть приближенными. Например, может не быть полной уверенности в наличии у пациента некоторого симптома или в том, что данные, полученные лри измерении, верны; лекарство может стать причиной осложнения, хотя обычно этого не происходит. Во всех этих случаях необходимы рассуждения с использованием вероятностного подхода.
В самом общем случае для того, чтобы построить экспертную систему, мы должны разработать механизмы выполнения следующих функций системы: решение задач с использованием знаний о конкретной предметной области - возможно, при этом возникнет необходимость иметь дело с неопределенностью взаимодействие с пользователем, включая объяснение намерений и решений системы во время и после окончания процесса решения задачи.
Каждая из этих функций может оказаться очень сложной и зависит от прикладной области, а также от различных практических требований. В процессе разработки и реализации могут возникать разнообразные трудные проблемы. В данной главе мы ограничился наметками основных идей, подлежащих в дальнейшем детализации и усовершенствованию.
Назад | Содержание | Вперёд
Грубая структура экспертной системы
При разработке экспертной системы принято делить ее на три основных модуля, как показано на рис. 14.1:
(1) база знаний,
(2) машина логического вывода,
(3) интерфейс с пользователем.
База знаний содержит знания, относящиеся к конкретной прикладной области, в том числе отдельные факты, правила, описывающие отношения или явления, а также, возможно, методы, эвристики и различные идеи, относящиеся к решению задач в этой прикладной области. Машина логического вывода умеет активно использовать информацию, содержащуюся в базе знаний. Интерфейс с пользователем отвечает за бесперебойный обмен информацией между пользователем и системой; он также дает пользователю возможность наблюдать за процессом решения задач, протекающим в машине логического вывода. Принято рассматривать машину вывода и интерфейс как один крупный модуль, обычно называемый оболочкой экспертной системы, или, для краткости, просто оболочкой.
В описанной выше структуре собственно знания отделены от алгоритмов, использующих эти знания. Такое разделение удобно по следующим соображениям. База знаний, очевидно, зависит от конкретного при-
Рис. 14. 1. Структура экспертной системы.
ложения. С другой стороны, оболочка, по крайней мере в принципе, независима от приложений. Таким образом, разумный способ разработки экспертной системы для нескольких приложений сводится к созданию универсальной оболочки, после чего для каждого приложения достаточно подключить к системе новую базу знаний. Разумеется, все эти базы знаний должны удовлетворять одному и тому же формализму, который оболочка "понимает". Практический опыт показывает, что для сложных экспертных систем наш сценарий с одной оболочкой и многими базами знаний работает не так гладко, как бы этого хотелось, за исключением тех случаев, когда прикладные области очень близки. Тем не менее даже если переход от одной прикладной области к другой требует модификации оболочки, то по крайней мере основные принципы ее построения обычно удается сохранить.
В этой главе мы намерены разработать относительно простую оболочку, при помощи которой, несмотря на. ее простоту, мы сможем проиллюстрировать основные идеи и методы в области экспертных систем. Мы будем придерживаться следующего плана:
(1) Выбрать формальный аппарат для представления знаний.
(2) Разработать механизм логического вывода, соответствующий этому формализму.
(3) Добавить средства взаимодействия с пользователем.
(4) Обеспечить возможность работы в условиях неопределенности.
Назад | Содержание | Вперёд
И / ИЛИ-представление задачи поиска маршрута
Для задачи отыскания кратчайшего маршрута (рис. 13.1) И / ИЛИ-граф вместе с функцией стоимости можно определить следующим образом:
ИЛИ-вершины представляются в форме X-Z, что означает: найти кратчайший путь из X в Z.
И-вершины имеют вид
X-Z через Y
что означает: найти кратчайший путь из X в Z, проходящий через Y.
Вершина X-Z является целевой вершиной (примитивной задачей), если на карте существует непосредственная связь между X и Z.
Стоимость каждой целевой вершины X-Z равна расстоянию, которое необходимо преодолеть по дороге, соединяющей X с Z.
Стоимость всех остальных (нетерминальных) вершин равна 0.
Стоимость решающего графа равна сумме стоимостей всех его вершин (в нашем случае это просто сумма стоимостей всех терминальных вершин). В задаче рис. 13.1 стартовая вершина - это а-z. На рис.
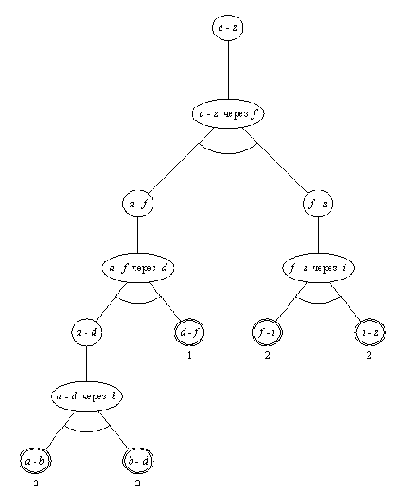
Рис. 13. 5. Решающее дерево минимальной стоимости для задачи
поиска маршрута рис. 13.1, сформулированной в терминах И / ИЛИ-
графа.
13.5 показан решающий граф, имеющий стоимость 9. Это дерево соответствует пути [a, b, d, f, i, z], который можно построить, если пройти по всем листьям решающего дерева слева направо.
ИГРЫ
В этой главе мы рассмотрим методы программирования игр двух лиц с полной информацией (таких, как шахматы). Для игр, представляющих интерес, деревья возможных продолжений слишком велики, чтобы можно было говорить о полном переборе, поэтому необходимы какие-то другие подходы. Один из таких методов, основанный на минимаксном принципе, имеет эффективную реализацию, известную под названием "альфа-бета алгоритм". В дополнение к этому стандартному методу, мы разработаем в этой главе программу на основе Языка Советов (Advice Language), который дает возможность вносить в шахматную программу знания о типовых ситуациях. Этот довольно подробный пример может послужить еще одной иллюстрацией того, насколько хорошо Пролог приспособлен для реализации систем, основанных на знаниях.
double_line();Игры двух лиц с полной информацией
Игры, которые мы собираемся обсуждать в данной главе, относятся к классу так называемых игр двух лиц с полной информацией. Примерами таких игр могут служить шахматы, шашки и т.п. В игре участвуют два игрока, которые ходят по очереди, причем оба они обладают полной информацией о текущей игровой ситуации (это определение исключает большинство карточных игр). Игра считается оконченной, если достигнута позиция, являющаяся согласно правилам игры "терминальной" (конечной), например матовая позиция в шахматах. Правилами игры также устанавливается, каков исход игры в этой терминальной позиции.
Для игр такого рода возможно представление в виде дерева игры (или игрового дерева). Вершины этого дерева соответствуют ситуациям, а дуги ходам. Начальная ситуация игры - это корневая вершина; листьями дерева представлены терминальные позиции.
В большинстве игр этого типа возможны следующие исходы: выигрыш, проигрыш и ничья. Мы будем рассматривать здесь игры, имеющие только два возможных исхода - выигрыш и проигрыш. Игры, в которых возможна ничья, можно упрощенно считать играми с двумя исходами - выигрыш и не-выигрыш. Двух участников игры мы будем называть "игроком" и "противником". "Игрок" может выиграть в некоторой нетерминальной позиции с ходом игрока ("позиции игрока"), если в ней существует какой-нибудь разрешенный ход, приводящий к выигрышу. С другой стороны, некоторая нетерминальная позиция с ходом противника ("позиция противника") является выигранной для игрока, если все разрешенные ходы из этой позиции ведут к позициям, в которых возможен выигрыш. Эти правила находятся в полном соответствии с представлением задач в форме И / ИЛИ-дерева, которое мы обсуждали в гл. 13.Между понятиями, относящимися к И / ИЛИ-деревьям, и понятиями, используемыми в играх, можно установить взаимное соответствие следующим образом:
позиции игры вершины, задачи
терминальные позиции целевые вершины,
выигрыша тривиально решаемые задачи
терминальные позиции задачи, не имеющие решения
проигрыша
выигранные позиции задачи, имеющие решение
позиции игрока ИЛИ-вершины
позиции противника И-вершины
Очевидно, что аналогичным образом понятия, относящиеся к поиску в И / ИЛИ-деревьях, можно переосмыслить в терминах поиска в игровых деревьях.
Ниже приводится простая программа, которая определяет, является ли некоторая позиция игрока выигранной.
выигр( Поз) :-
терм_выигр( Поз).
% Терминальная выигранная позиция
выигр( Поз) :-
not терм_проигр( Поз),
ход( Поз, Поз1), % Разрешенный ход в Поз1
not ( ход( Поз1, Поз2),
not выигр( Поз2) ).
% Ни один из ходов противника не ведет к не-выигрышу
Здесь правила игры встроены в предикат ход( Поз, Поз1), который порождает все разрешенные ходы, а также в предикаты терм_выигр( Поз) и терм_проигр( Поз), которые распознают терминальные позиции, являющиеся, согласно правилам игры, выигранными или проигранными. В последнем из правил программы, содержащем двойное отрицание (not), говорится: не существует хода противника, ведущего к не выигранной позиции. Другими словами: все ходы противника приводят к позициям, выигранным с точки зрения игрока.
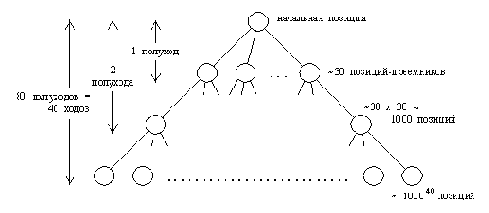
Рис. 15. 1. Сложность игровых деревьев в шахматах. Оценки основаны
на том, что в каждой шахматной позиции существуют приблизительно
30 разрешенных ходов я что терминальные позиции расположены на
глубине 40 ходов. Один ход равен двум полуходам (по одному
полуходу с каждой стороны).
Так же, как и аналогичная программа поиска в И / ИЛИ-графах, приведенная выше программа использует стратегию в глубину. Кроме того, в ней не исключается возможность зацикливания на одних и тех же позициях. Попытка устранить этот недостаток может привести к осложнениям, поскольку правила некоторых из игр допускают такое повторение позиций. Правда, разрешение повторять позиции часто носит условный характер, например по шахматным правилам после троекратного повторения позиции может быть объявлена ничья.
Программа, которую мы составили, демонстрирует основные принципы программирования игр. Но практически приемлемая реализация таких сложных игр, как шахматы или го, потребовала бы привлечения значительно более мощных методов. Огромная комбинаторная сложность этих игр делает наш наивный переборный алгоритм, просматривающий дерево вплоть до терминальных игровых позиций, абсолютно непригодным. Этот вывод иллюстрирует (на примере шахмат) рис. 15.1: пространство поиска имеет астрономические размеры - около 10120 позиций. Можно возразить, что в дереве на рис. 15.1 встречаются одинаковые позиции. Однако было показано, что число различных позиций дерева поиска находится далеко за пределами возможностей вычислительных машин обозримого будущего.
Имеетребенка( X) :- родитель( X, _ )
Всякий раз, когда в предложения появляется одиночный символ подчеркивания, он обозначает новую анонимную переменную. Например, можно сказать, что существует некто, кто имеет ребенка, если существуют два объекта, такие, что один из них является родителем другого:
Имеетребенка( X) :- родитель( X, Y)
Это правило гласит: "Для всех X, Х имеет ребенка, если X является родителем некоторого Y". Здесь мы определяем свойство имеетребенка таким образом, что оно не зависит от имени ребенка. Следовательно, это как раз тот случай, когда уместно использовать анонимную переменную. Поэтому вышеприведенное правило можно переписать так:
ИНТЕЛЛЕКТА
Перевод с английского
А.И. Лупенко и A.M.Степанова
под редакцией A.M. Степанова

Москва "МИР" 1990
ББК 22.19
Б 87
УДК 519.68
Использование рекурсии
Этот принцип состоит в том, чтобы разбить задачу на случаи, относящиеся к двум группам:
(1) тривиальные, или "граничные" случаи;
(2) "общие" случаи, в которых решение получается из решений для (более простых) вариантов самой исходной задачи.
Этот метод мы использовали в Прологе постоянно. Рассмотрим еще один пример: обработка списка элементов, при которой каждый элемент преобразуется по одному и тому же правилу. Пусть это будет процедура
преобрспис( Спис, F, НовСпиc)
где Спис - исходный список, F - правило преобразования (бинарное отношение), а НовСпиc - список всех преобразованных элементов. Задачу преобразования списка Спис можно разбить на два случая:
(1) Граничный случай: Спис = [ ]
Если Спис = [ ], то НовСпиc = [ ], независимо от F
(2) Общий случай: Спис = [X | Хвост]
Чтобы преобразовать список вида [X | Хвост], необходимо:
преобразовать список Хвост; результат - НовХвост;
преобразовать элемент Х по правилу F; результат - НовХ;
результат преобразования всего списка - [НовХ | НовХвост].
Тот же алгоритм, изложенный на Прологе:
преобрспис( [ ], _, [ ]).
преобрспис( [Х | Хвост], F, [НовХ | НовХвост] :-
G =.. [F, X, НовХ],
саll( G),
пpeoбpcпиc( Хвост, F, НовХвост).
Одна из причин того, что рекурсия так естественна для определения отношений на Прологе, состоит в том, что объекты данных часто сами имеют рекурсивную структуру. К таким объектам относятся списки и деревья. Список либо пуст (граничный случай), либо имеет голову и хвост, который сам является списком (общий случай). Двоичное дерево либо пусто (граничный случай), либо у него есть корень и два поддерева, которые сами являются двоичными деревьями (общий случай). Поэтому для обработки всего непустого дерева необходимо сначала что-то сделать с его корнем, а затем обработать поддеревья.
Использование рисунков
В поиске идей для решения задачи часто бывает полезным обратиться к ее графическому представлению. Рисунок может помочь выявить в задаче некоторые существенные отношения. После этого останется только описать на языке программирования то, что мы видим на рисунке.
Использование графического представления при решении задач полезно всегда, однако похоже, что в Прологе оно работает особенно хорошо. Происходит это по следующим причинам:
(1) Пролог особенно хорошо приспособлен для задач, в которых фигурируют объекты и отношения между ними. Часто такие задачи естественно иллюстрировать графами, в которых узлы соответствуют объектам, а дуги - отношениям.
(2) Естественным наглядным изображением структурных объектов Пролога являются деревья.
(3) Декларативный характер пролог-программ облегчает перевод графического представления на Пролог. В принципе, порядок описания "картинки" не играет роли, мы просто помещаем в программу то, что видим, в произвольном порядке. (Возможно, что из практических соображений этот порядок впоследствии придется подправить с целью повысить эффективность программы.)
Назад | Содержание | Вперёд
ИСПОЛЬЗОВАНИЕ СТРУКТУР: ПРИМЕРЫ
Структуры данных вместе с сопоставлением, автоматическими возвратами и арифметикой представляют собой мощный инструмент программирования. В этой главе мы расширим навыки использования этого инструмента при помощи следующих учебных программных примеров: получение структурированной информации из базы данных, моделирование недетерминированного автомата, планирование маршрута поездки и решение задачи о расстановке восьми ферзей на шахматной доске. Мы увидим также, как в Прологе реализуется принцип абстракции данных.
double_line();Ivan Bratko
E. Kardelj University • J. Stefan Institute
Yugoslavia
ADDISON-WESLEY
PUBLISHIHG
COMPANY
Wokingham, England • Reading, Massachusetts • Menlo Park,California • Don Mills, Ontario • Amsterdam • Bonn • Sydney • Singapore • Tokyo • Madrid • Bogota • Santiago • San-Juan
Я страница обложки
Учебное издание
Иван Братко
Программирование на языке Пролог
для искусственного интеллекта
Заведующий редакцией чл.-корр. АН СССР проф. В.И.Арнольд
Зам.зав. редакцией А.С. Попов
Ст. научный редактор М. В.Хатунцева
Художественный редактор В.И. Шаповалов
Художник В. А. Медников
График Л. Г. Туранова
Корректор А.Ф. Рыбальченко
ИБ № 7199
Оригинал-макет подготовлен на персональном компьютере и
отпечатан на лазерном принтере в издательстве "Мир"
Подписано к печати 13.08.90. Формат 84 х 108 1/32. Бумага кн. журн. имп. Печать высокая. Гарнитура литературная. Объем 8,75 бум. л. Усл. печ. л. 29,40. Усл. кр.-отт. 29,40. Уч.-изд. л. 25,60.
Изд. № 1/6603. Тираж 100 000 экз. Зак. № 633. Цена 3 р. 50 к.
Издательство "Мир" В/О "Совэкспорткнига" Госкомпечати СССР
129820, ГСП, Москва, И-110. 1-й Рижский пер.,. 2.
Отпечатано в Ленинградской типографии №2 головном предприятии
ордена Трудового Красного Знамени Ленинградского объединения
'Техническая книга" им. Евгении Соколовой Государственного
комитета СССР по печати.
198052, г.Ленинград, Л-52, Измайловский проспект, 29.
Назад | Содержание
Эффективность
Существует несколько аспектов эффективности программ, включая такие наиболее общие, как время выполнения и требования по объему памяти. Другим аспектом является время, необходимое программисту для разработки программы.
Традиционная архитектура вычислительных машин не очень хорошо приспособлена для реализации прологовского способа выполнения программ, предусматривающего достижение целей из некоторого списка. Поэтому ограниченность ресурсов по времени и пространству сказывается в Прологе, пожалуй, в большей степени, чем в большинстве других языков программирования. Вызовет ли это трудности в практических приложениях, зависит от задачи. Фактор времени практически не имеет значения, если пролог-программа, которую запускают по несколько раз в день, занимает 1 секунду процессорного времени, а соответствующая программа на каком-либо другом языке, скажем на Фортране, - 0.1 секунды. Разница в эффективности становится существенной, если эти две программы требуют 50 и 5 минут соответственно.
С другой стороны, во многих областях применения Пролога он может существенно сократить время разработки программ. Программы на Прологе, вообще говоря, легче писать, легче понимать и отлаживать, чем программы, написанные на традиционных языках. Задачи, тяготеющие к "царству Пролога", включают в себя обработку символьной, нечисловой информации, структурированных объектов данных и отношений между ними. Пролог успешно применяется, в частности. в таких областях, как символьное решение уравнений, планирование, базы данных, автоматическое решение задач, машинное макетирование, реализация языков программирования, дискретное и аналоговое моделирование, архитектурное проектирование, машинное обучение, понимание естественного языка, экспертные системы и другие задачи искусственного интеллекта. С другой стороны, применение Пролога в области вычислительной математики вряд ли можно считать естественным.
Прогон откомпилированной
программы обычно имеет большую эффективность, чем интерпретация.
Поэтому, если пролог- система содержит как интерпретатор, так и компилятор, следует пользоваться компилятором, если время выполнения критично.
Если программа страдает неэффективностью, то ее обычно можно кардинально улучшить, изменив сам алгоритм. Однако для того, чтобы это сделать, необходимо изучить процедурные аспекты программы. Простой способ сокращения времени выполнения состоит в нахождении более удачного порядка предложений в процедуре и целей - в телах процедур. Другой, относительно простой метод заключается в управлении действиями системы посредством отсечений.
Полезные идеи, относящиеся к повышению эффективности, обычно возникают только при достижении более глубокого понимания задачи. Более эффективный алгоритм может, вообще говоря, привести к улучшениям двух видов:
Повышение эффективности поиска путем скорейшего отказа от ненужного перебора и от вычисления бесполезных вариантов.
Применение cтруктур данных, более приспособленных для представления объектов программы, с целью реализовать операции над ними более эффективно.
Мы изучим оба вида улучшений на примерах. Кроме того, мы рассмотрим на примере еще один метод повышения эффективности. Этот метод основан на добавлении в базу данных тех промежуточных результатов, которые с большой вероятностью могут потребоваться для дальнейших вычислений. Вместо того, чтобы вычислять их снова, программа просто отыщет их в базе данных как уже известные факты.
что произойдет, если задать следующий
Проанализируем, что произойдет, если задать следующий вопрос:
?- f( 1, Y), 2 < Y.

Рис. 5. 2. В точке, помеченной словом "ОТСЕЧЕНИЕ", уже известно,
что правила 2 и 3 должны потерпеть неудачу.
При вычислении первой цели f( l, Y) Y конкретизируется нулем. Поэтому вторая цель становится такой:
2 < 0
Она терпит неудачу, а поэтому и весь список целей также терпит неудачу. Это очевидно, однако перед тем как признать, что такому списку целей удовлетворить нельзя, пролог-система при помощи возвратов попытается проверить еще две бесполезные в данном случае альтернативы. Пошаговое описание процесса вычислений приводится на рис. 5.2.
Три правила, входящие в отношение f, являются взаимоисключающими, поэтому успех возможен самое большее в одном из них. Следовательно, мы (но не пролог-система) знаем, что, как только успех наступил в одном из них, нет смысла проверять остальные, поскольку они все равно обречены на неудачу. В примере, приведенном на рис. 5.2, о том, что в правиле 1 наступил успех, становится известно в точке, обозначенной словом "ОТСЕЧЕНИЕ". Для предотвращения бессмысленного перебора мы должны явно указать пролог-системе, что не нужно осуществлять возврат из этой точки. Мы можем сделать это при помощи конструкции отсечения. "Отсечение" записывается в виде символа '!', который вставляется между целями и играет роль некоторой псевдоцели. Вот наша программа, переписанная с использованием отсечения:
f( X, 0) :- X < 3, !.
f( X, 2) :- 3 =< X, X < 6, !.
f( X, 4) :- 6 =< X.
Символ '!' предотвращает возврат из тех точек программы, в которых он поставлен. Если мы теперь спросим
?- f( 1, Y), 2 < Y.
то пролог- система породит левую ветвь дерева, изображенного на рис. 5.2. Эта ветвь потерпит неудачу на цели 2 < 0. Система попытается сделать возврат, но вернуться она сможет не далее точки, помеченной в программе символом '!' . Альтернативные ветви, соответствующие правилу 2 и правилу 3, порождены не будут.
Новая программа, снабженная отсечениями, во всех случаях более эффективна, чем первая версия, в которой они отсутствуют. Неудачные варианты новая программа распознает всегда быстрее, чем старая.
Вывод: добавив отсечения, мы повысили эффективность. Если их теперь убрать, программа породит тот же результат, только на его получение она истратит скорее всего больше времени. Можно сказать, что в нашем случае после введения отсечений мы изменили только процедурный смысл программы, оставив при этом ее декларативный смысл в неприкосновенности. В дальнейшем мы покажем, что использование отсечения может также затронуть и декларативный смысл программы.
Проделаем теперь еще один эксперимент
Проделаем теперь еще один эксперимент со второй версией нашей программы. Предположим, мы задаем вопрос:
?- f( 7, Y).
Y = 4
Проанализируем, что произошло. Перед тем, как был получен ответ, система пробовала применить все три правила. Эти попытки породили следующую последовательность целей:
Попытка применить правило 1:
7 < 3 терпит неудачу, происходит возврат, и попытка применить правило 2 (точка отсечения достигнута не была)
Попытка применить правило 2:
3 <= 7 успех, но 7 < 6 терпит неудачу; возврат и попытка применить правило 3 (точка отсечения снова не достигнута)
Попытка применить правило 3:
6 <= 7 - успех
Приведенные этапы вычисления обнаруживают еще один источник неэффективности. В начале выясняется, что X < 3 не является истиной (7 < 3 терпит неудачу). Следующая цель - 3 =< Х (3 <= 7- успех). Но нам известно, что, если первая проверка неуспешна, то вторая обязательно будет успешной, так как второе целевое утверждение является отрицанием первого. Следовательно, вторая проверка лишняя и соответствующую цель можно опустить. То же самое верно и для цели 6 =< Х в правиле 3. Все эти соображения приводят к следующей, более экономной формулировке наших трех правил:
если Х < 3, то Y = 0
иначе, если 3 <= X и Х < 6, то Y = 2,
иначе Y = 4.
Теперь мы можем опустить в нашей программе те условия, которые обязательно выполняются при любом вычислении. Получается третья версия программы:
f( X, 0) :- X < 3, !.
f( X, 2) :- X < 6, !.
f( X, 4).
Эта программа дает тот же результат, что и исходная, но более эффективна, чем обе предыдущие. Однако, что будет, если мы теперь удалим отсечения? Программа станет такой:
f( X, 0) :- X < 3.
f( X, 2) :- X < 6.
f( X, 4).
Она может порождать различные решения, часть из которых неверны. Например:
?- f( 1, Y).
Y = 0;
Y = 2;
Y = 4;
nо (нет)
Важно заметить, что в последней версии, в отличие от предыдущей, отсечения затрагивают не только процедурное поведение, но изменяют также и декларативный смысл программы.
Более точный смысл механизма отсечений можно сформулировать следующим образом:
line(); Назовем "целью-родителем" ту цель, которая сопоставилась с головой предложения, содержащего отсечение. Когда в качестве цели встречается отсечение, такая цель сразу же считается успешной и при этом заставляет систему принять те альтернативы, которые были выбраны с момента активизации цели-родителя до момента, когда встретилось отсечение. Все оставшиеся в этом промежутке (от цели-родителя до отсечения) альтернативы не рассматриваются.
line(); Чтобы прояснить смысл этого определения, рассмотрим предложение вида
Н :- В1, В2, ..., Вm, !, ..., Вn.
Будем считать, что это предложение активизировалось, когда некоторая цель G сопоставилась с Н. Тогда G является целью-родителем. В момент, когда встретилось отсечение, успех уже наступил в целях В1, ..., Вm. При выполнении отсечения это (текущее) решение В1, ..., Вm "замораживается" и все возможные оставшиеся альтернативы больше не рассматриваются.
Далее, цель G связывается теперь с этим предложением: любая попытка сопоставить G с головой какого-либо другого предложения пресекается.
Применим эти правила к следующему примеру:
С :- Р, Q, R, !, S, Т, U.
С :- V.
А :- В, С, D.
?- А.
Здесь А, В, С, D, Р и т.д. имеют синтаксис термов. Отсечение повлияет на вычисление цели С следующим образом. Перебор будет возможен в списке целей Р, Q, R; однако, как только точка отсечения будет достигнута, все альтернативные решения для этого списка изымаются из рассмотрения. Альтернативное предложение, входящее в С:
С :- V.
также не будет учитываться. Тем не менее, перебор будет возможен в списке целей S, Т, U. "Цель-родитель" предложения, содержащего отсечения, -это цель С в предложении
А :- В, С, D.
Поэтому отсечение повлияет только на цель С. С другой стороны, оно будет "невидимо" из цели А. Таким образом, автоматический перебор все равно будет происходить в списке целей В, С, D, вне зависимости от наличия отсечения в предложении, которое используется для достижения С.
Назад | Содержание | Вперёд
ЭКСПЕРТНЫЕ СИСТЕМЫ
Экспертная система - это программа, которая ведет себя подобно эксперту в некоторой проблемной области. Она должна иметь способность к объяснению своих решений и тех рассуждений, на основе которых эти решения были приняты. Часто от экспертной системы требуют, чтобы она могла работать с неточной и неполной информацией.
Для того, чтобы построить экспертную систему, мы должны создать механизмы, обеспечивающие выполнение следующих функций: решение задач, взаимодействие с пользователем и работа в условиях неопределенности. В данной главе мы разработаем и peaлизуем основные идеи построения экспертных систем.
double_line();Эвристические оценки и алгоритм поиска
Базовые процедуры поиска предыдущего раздела производят систематический и полный просмотр И / ИЛИ-дерева, не руководствуясь при этом какими-либо эвристиками. Для сложных задач подобные процедуры весьма не эффективны из-за большой комбинаторной сложности пространства поиска. В связи с этим возникает необходимость в эвристическом управлении поиском, направленном на уменьшение комбинаторной сложности за счет исключения бесполезных альтернатив. Управление эвристиками, излагаемое в настоящем разделе, будет основано на численных эвристических оценках "трудности" задач, входящих в состав И / ИЛИ-графа. Программу, которую мы составим, можно рассматривать как обобщение программы поиска с предпочтением в пространстве состояний гл. 12.
Начнем с того, что сформулируем критерий оптимальности, основанный на стоимостях дуг И / ИЛИ-графа. Во-первых, мы расширим наше представление И / ИЛИ-графов, дополнив его стоимостями дуг. Например, И / ИЛИ-граф рис. 13.4 можно представить следующими предложениями:
а ---> или : [b/1, с/3].
b ---> и : [d/1, е/1].
с ---> и : [f/2, g/1].
e ---> или : [h/6].
f ---> или : [h/2, i/3].
цель( d). цель( g). цель( h).
Стоимость решающего дерева мы определим как сумму стоимостей его дуг. Цель оптимизации - найти решающее дерево минимальной стоимости. Как и раньше, иллюстрацией служит рис. 13.4.
Будет полезным определить стоимость вершины И / ИЛИ-графа как стоимость оптимального решающего дерева для этой вершины. Стоимость вершины, определенная таким образом, соответствует "трудности" соответствующей задачи.
Мы будем предполагать, что стоимости вершин И / ИЛИ-графа можно оценить (не зная соответствующих решающих деревьев) при помощи эвристической функции h. Эти оценки будут использоваться для управления поиском.
Наша программа поиска начнет свою работу со стартовой вершины и, распространяя поиск из уже просмотренных вершин на их преемников, будет постепенно наращивать дерево поиска. Этот процесс будет строить дерево даже в том случае, когда сам И / ИЛИ-граф не является деревом; при этом граф будет разворачиваться в дерево за счет дублирования своих отдельных частей.
Для продолжения поиска будет всегда выбираться "наиболее перспективное" решающее дерево-кандидат. Каким же образом используется функция h для оценки степени перспективности решающего дерева-кандидата или, точнее, вершины-кандидата - корня этого дерева?
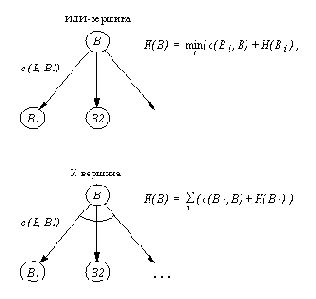
Рис. 13. 9. Получение оценки Н трудности задач И / ИЛИ-графа.
Обозначим через Н( В) оценку трудности вершины В. Для самой верхней вершины текущего дерева поиска H( В) просто совпадает с h( В). С другой стороны, для оценки внутренней вершины дерева поиска нам не обязательно использовать непосредственно значение h, поскольку у нас есть некоторая дополнительная информация об этой вершине: мы знаем ее преемников. Следовательно, как показано на рис. 13.9, мы можем приближенно оценить трудность внутренней ИЛИ-вершины как
H( B) = min ( c( B, Bi) + H( Bi) )
i
где с( В, В) - стоимость дуги, ведущей из В в Вi. Взятие минимума в этой формуле оправдано тем обстоятельством, что для того, чтобы решить задачу В, нам нужно решить только одну из ее задач-преемников. Трудность И-вершины В можно приближенно оценить так:
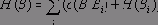
Будем называть H-оценку внутренней вершины "возвращенной" (backed-up) оценкой.
Более практичной с точки зрения использования в нашей программе поиска является другая величина F, которую можно определить в терминах H следующим образом.
Пусть В1 - вершина-предшественник вершины В в дереве поиска, причем стоимость дуги, ведущей из В1 в В, равна с( В1, В), тогда положим
F( B) = с( В1, В) + H( В)
Пусть В1 - родительская вершина вершины В, а В1, В2, ... - ее дочерние вершины, тогда, в соответствии с определениями F и H, имеем
F( B) = c( B1, B) + minF( Bi), если В - ИЛИ-вершина
i
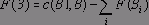
Хотя стартовая вершина А и не имеет предшественника, будем считать, что стоимость ведущей в нее (виртуальной) дуги равна 0. Если положить h равным 0 для всех вершин И / ИЛИ-дерева, то для любого найденного оптимального решающего дерева окажется, что его стоимость, т.е. сумма стоимостей его дуг, в точности равна F( A).
На любой стадии поиска каждый преемник ИЛИ-вершины соответствует некоторому альтернативному решающему дереву-кандидату. Процесс поиска всегда принимает решение продолжать просмотр того дерева-кандидата, для которого F-оценка минимальна. Вернемся еще раз к рис. 13.4 и посмотрим, как будет вести себя процесс, поиска на примере И / ИЛИ-графа, изображенного на этом рисунке. В начале дерево поиска состоит всего из одной вершины - стартовой вершины а, далее дерево постепенно "растет" до тех пор, пока не будет найдено решающее дерево. На рис. 13.10, показан ряд "мгновенных снимков", сделанных в процессе роста дерева поиска.
Для простоты мы предположим, что h = 0 для всех вершин. Числа, приписанные вершинам на рис. 13.10 - это их F-оценки (разумеется, по мере накопления информации в процессе поиска они изменяются). Ниже даются некоторые пояснительные замечания к рис. 13.10.
После распространения поиска из первоначального дерева (снимок А) получается дерево В. Вершина а - это ИЛИ-вершина, поэтому мы имеем два решающих дерева-кандидата: b и с. Поскольку F( b) = 1 < 3 = F( c), для продолжения поиска выбирается альтернатива b. Насколько далеко может зайти процесс роста поддерева b? Этот процесс может продолжаться до тех пор, пока не произойдет одно из двух событий:
(1) F-оценка вершины b станет больше, чем F-оценка ее конкурента с, или
(2) обнаружится, что найдено решающее дерево.
В связи с этим, начиная просмотр поддерева-кандидата b, мы устанавливаем верхнюю границу для F( b): F( b) <= 3 = F( c). Сначала порождаются преемники d и е вершины b (снимок С), после чего F-оценка b возрастает до 3. Так как это значение не превосходит верхнюю границу, рост дерева-кандидата с корнем в b продолжается. Вершина d оказывается целевой вершиной, а после распространения поиска из вершины е на один шаг получаем дерево, показанное на снимке D. В этот момент выясняется, что F( b) = 9 > 3, и рост дерева b
Рис. 13. 10. Трассировка процесса поиска с предпочтением в
И / ИЛИ-графе ( h = 0) при решении задачи рис. 13.4.
прекращается. В результате процесс поиска не успевает "осознать", что h - это тоже целевая вершина и что порождено решающее дерево.Вместо этого происходит переключение активности на конкурирующую альтернативу с. Поскольку в этот момент F( b) = 9, устанавливается верхняя граница для F( c), равная 9. Дерево-кандидат с корнем с наращивается (с учетом установленного ограничения) до тех пор, пока не возникает ситуация, показанная на снимке Е. Теперь процесс поиска обнаруживает, что найдено решающее дерево (включающее в себя целевые вершины h и g), на чем поиск заканчивается. Заметьте, что в качестве результата процесс поиска выдает наиболее дешевое из двух возможных решающих деревьев, а именно решающее дерево рис. 13.4(с).
Как представлять себе программы на Прологе
Одной из характерных особенностей Пролога является то, что в нем допускается как процедурный, так и декларативный стиль мышления при составлении программы. Эти два подхода детально обсуждались в гл. 2 и затем многократно иллюстрировались на примерах. Какой из этих подходов окажется более эффективным и практичным, зависит от конкретной задачи. Обычно построение декларативного решения задачи требует меньших усилий, но может привести к неэффективной программе. В процессе построения решения мы должны сводить задачу к одной или нескольким более легким подзадачам. Возникает важный вопрос: как находить эти подзадачи? Существует несколько общих принципов, которые часто применяются при программировании на Прологе. Они будут обсуждаться в следующих разделах.
Как пролог-система отвечает на вопросы
В данном разделе приводится неформальное объяснение того, как пролог-система отвечает на вопросы.
Вопрос к системе - это всегда последовательность, состоящая из одной или нескольких целей. Для того, чтобы ответить на вопрос, система пытается достичь всех целей. Что значит достичь цели? Достичь цели - это значит показать, что утверждения, содержащиеся в вопросе, истинны в предположении, что все отношения программы истинны. Другими словами, достичь цели - это значит показать, что она логически следует из фактов и правил программы. Если вопрос содержит переменные, система должна к тому же найти конкретные объекты, которые (будучи подставленными вместо переменных) обеспечивают достижение цели. Найденные конкретизации сообщаются пользователю. Если для некоторой конкретизации система не в состоянии вывести цель из остальных предложений программы, то ее ответом на вопрос будет "нет".
Таким образом, подходящей интерпретацией пролог-программы в математических терминах будет следующая: пролог-система рассматривает факты и правила в качестве множества аксиом, а вопрос пользователя - как теорему; затем она пытается доказать эту теорему, т.е. показать, что ее можно логически вывести из аксиом.
Проиллюстрируем этот подход на классическом примере. Пусть имеются следующие аксиомы:
Все люди смертны.
Сократ - человек.
Теорема, логически вытекающая из этих двух аксиом:
Сократ смертен.
Первую из вышеуказанных аксиом можно переписать так:
Для всех X, если X - человек, то X смертен.
Соответственно наш пример можно перевести на Пролог следующим образом:
смертен( X) :- человек( X).
% Все люди смертны
человек( сократ).
% Сократ - человек
?- смертен( сократ).
% Сократ смертен?
yes
(да)
Более сложный пример из программы о родственных отношениях, приведенной на рис. 1.8:
?- предок( том, пат)
Мы знаем, что родитель( боб, пат) - это факт. Используя этот факт и правило пр1, мы можем сделать вывод, что утверждение предок( боб, пат) истинно. Этот факт получен в результате вывода - его нельзя найти непосредственно в программе, но можно вывести, пользуясь содержащимися в ней фактами и правилами. Подобный шаг вывода можно коротко записать
родитель( боб, пат) ==> предок( боб, пат)
Эту запись можно прочитать так: из родитель( боб, пат) следует предок( боб, пат)
на основании правила пр1. Далее, нам известен факт родитель( том, боб). На основании этого факта и выведенного факта предок( боб, пат) можно заключить, что, в силу правила пр2, наше целевое утверждение предок( том, пат)
истинно. Весь процесс вывода, состоящий из двух шагов, можно записать так:
родитель(боб, пат) ==> предок( боб, пат)
родитель(том, боб) и предок( боб, пат) ==>
предок( том, пат)
Таким образом, мы показали, какой может быть последовательность шагов для достижения цели, т.е. для демонстрации истинности целевого утверждения. Назовем такую последовательность цепочкой доказательства. Однако мы еще не показали как пролог-система в действительности строит такую цепочку.
Пролог-система строит цепочку доказательства в порядке, обратном по отношению к тому, которым мы только что воспользовались.
Вместо того, чтобы начинать с простых фактов, приведенных в программе, система начинает с целей и, применяя правила, подменяет текущие цели новыми, до тех пор, пока эти новые цели не окажутся простыми фактами. Если задан вопрос
?- предок( том, пат).
система попытается достичь этой цели. Для того, чтобы это сделать, она пробует найти такое предложение в программе, из которого немедленно следует упомянутая цель. Очевидно, единственными подходящими для этого предложениями являются пр1
и пр2.
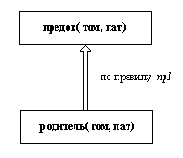
Рис. 1. 9. Первый шаг вычислений. Верхняя цель истинна, если истинна нижняя.
Это правила, входящие в отношение предок. Будем говорить, что головы этих правил сопоставимы с целью.
Два предложения пр1 и пр2 описывают два варианта продолжения рассуждений для пролог-системы. Вначале система пробует предложение, стоящее в программе первым:
предок( X, Z) :- родитель( X, Z).
Поскольку цель - предок( том, пат), значения переменным должны быть приписаны следующим образом:
X = том, Z = пат
Тогда исходная цель предок( том, пат) заменяется новой целью:
родитель( том, пат)
Такое действие по замене одной цели на другую на основании некоторого правила показано на рис. 1.9. В программе нет правила, голова которого была бы сопоставима с целью родитель(том, пат), поэтому такая цель оказывается неуспешной. Теперь система делает возврат к исходной цели, чтобы попробовать второй вариант вывода цели верхнего уровня предок( том, пат). То есть, пробуется правило пр2:
предок( X, Z) :-
родитель( X, Y),
предок( Y, Z).
Как и раньше, переменным X и Z приписываются значения:
X = том, Z = пат
В этот момент переменной Y еще не приписано никакого значения. Верхняя цель предок( том, пат) заменяется двумя целями:
родитель( том, Y),
предок( Y, пат)
Этот шаг вычислений показан на рис. 1.10, который представляет развитие ситуации, изображенной на рис. 1.9.
Рис. 1. 10. Продолжение процесса вычислений, показанного на рис. 1.9.
Имея теперь перед собой две цели, система пытается достичь их в том порядке, каком они записаны. Достичь первой из них легко, поскольку она соответствует факту из программы. Процесс установления соответствия - сопоставление (унификация) вызывает приписывание переменной Y значения боб. Тем самым достигается первая цель, а оставшаяся превращается в
предок( боб, пат)
Для достижения этой цели вновь применяется правило пр1. Заметим, - что это (второе) применение правила никак не связано с его первым применением. Поэтому система использует новое множество переменных правила всякий раз, как оно применяется. Чтобы указать это, мы переименуем переменные правила пр1 для нового его применения следующим образом:
предок( X ', Z ') :-
родитель( X ', Z ').
Голова этого правила должна соответствовать нашей текущей цели предок( боб, пат). Поэтому
X ' = боб, Z ' = пат
Текущая цель заменяется на
родитель( боб, пат)
Такая цель немедленно достигается, поскольку встречается в программе в качестве факта. Этот шаг завершает вычисление, что графически показано на рис. 1.11.
Рис. 1. 11. Все шаги достижения цели предок( том, пат). Правая
ветвь демонстрирует, что цель достижима.
Графическое представление шагов вычисления на рис. 1.11 имеет форму дерева. Вершины дерева соответствуют целям или спискам целей, которые требуется достичь.Дуги между вершинами соответствуют применению (альтернативных) предложений программы, которые преобразуют цель, соответствующую одной вершине, в цель, соответствующую другой вершине. Корневая (верхняя) цель достигается тогда, когда находится путь от корня дерева (верхней вершины) к его листу, помеченному меткой "да". Лист помечается меткой "да", если он представляет собой простой факт. Выполнение пролог-программы состоит в поиске таких путей. В процессе такого поиска система может входить и в ветви, приводящие к неуспеху. В тот момент, когда она обнаруживает, что ветвь не приводит к успеху, происходит автоматический возврат к предыдущей вершине, и далее следует попытка применить к ней альтернативное предложение.
Литература
Различные реализации Пролога используют разные синтаксические соглашения. В данной книге мы применяем так называемый Эдинбургский синтаксис (его называют также синтаксисом DEC-10, поскольку он принят в известной реализации Пролога для машины DEC-10; см. Pereira и др. 1978), он используется во многих популярных пролог-системах, таких как Quintus Prolog, Poplog, CProlog, Arity/ Prolog, Prolog-2 и т.д.
Bowen D. L. (1981). DECsystem-10 Prolog User's Manual. University of Edinburgh: Department of Artificial Intelligence.
Mellish С. and Hardy S. (1984). Integrating Prolog in the POPLOG environment. Implementations of Prolog (J. A. Campbell, ed.). Ellis Horwood.
Pereira F. (1982). C-Prolog User's Manual. University of Edinburgh: Department of Computer-Aided Architectural Design.
Pereira L. M., Pereira F., Warren D. H. D. (1978). User's Guide to DECsystem-10 Prolog. University of Edinburgh: Department of Artificial Intelligence.
Quintus Prolog User's Guide and Reference Manual. Palo Alto: Quintus Computer System Inc. (1985).
The Arity/Prolog Programming Language. Concord, Massachusetts: Arity Corporation (1986).
2-3 деревья детально описаны, например, в Aho, Hopcroft and Ullman (1974, 1983). В книге этих авторов, вышедшей в 1983 г., дается также реализация соответствующих алгоритмов на языке Паскаль. Н.Вирт (см. Wirth (1976)) приводит программу на Паскале для работы с AVL-деревьями. 2-3 деревья являются частным случаем более общего понятия В-деревьев. В-деревья, а также несколько других вариантов структур данных, имеющих отношение к 2-3 деревьям в AVL-деревьям, рассматриваются в книге Gonnet (1984). В этой книге, кроме того, даны результаты анализа поведения этих структур.
Программа вставления элемента в AVL-дерево, использующая только величину "перекоса" дерева (т.е. значение разности глубин поддеревьев, равной -1, 0 или 1, вместо самой глубины) опубликована ван Эмденом (1981).
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1974). The Design and Analysis of Computer Algorithms. Addison-Wesley. [Имеется перевод: Ахо А., Хопкрофт Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ. - М.: Мир, 1979.]
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1983). Data Structures and Algorithms. Addison-Wesley.
Gonnet G. H. (1984). Handbook of Algorithms + Data Structures. Addison-Wesley.
van Emden M. (1981). Logic Programming Newsletter 2.
Wirth N. (1976). Algorithms + Data Structures = Programs. Prentice-Hall. [Имеется перевод: Вирт H. Алгоритмы + структуры данных = программы. - M.: Мир, 1985.]
Назад | Содержание | Вперёд
Поиск в глубину и поиск в ширину - базовые стратегии поиска, они описаны в любом учебнике по искусственному интеллекту, см., например, Nilsson (1971, 1980) или Winston (1984). Р. Ковальский в своей книге Kowalski (1980) показывает, как можно использовать аппарат математической логики для реализации этих принципов.
Kowalski R. (1980). Logic for Problem Solving. North-Holland.
Nilsson N. J. (1971). Problem Solving Methods in Artificial Intelligence. McGraw-Hill.
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; also Springer- Verlag, 1981.
Winston P. H. (1984). Artificial Intelligence (second edition). Addison-Wesley. [Имеется перевод первого издания: Уинстон П. Искусственный интеллект. - М.: Мир, 1980.]
Назад | Содержание | Вперёд
Программа поиска с предпочтением, представленная в настоящей главе, - это один из многих вариантов похожих друг на друга программ, из которых А*-алгоритм наиболее популярен. Общее описание А*-алгоритма можно найти в книгах Nillson (1971, 1980) или Winston (1984). Теорема о допустимости впервые доказана авторами статьи Hart, Nilsson, and Raphael (1968). Превосходное и строгое изложение многих разновидностей алгоритмов поиска с предпочтением и связанных с ними математических результатов дано в книге Pearl (1984). В статье Doran and Michie (1966) впервые изложен поиск с предпочтением, управляемый оценкой расстояния до цели.
Головоломка "игра в восемь" использовалась многими исследователями в области искусственного интеллекта в качестве тестовой задачи при изучении эвристических принципов (см., например, Doran and Michie (1966), Michie and Ross (1970) и Gaschnig (1979) ).
Задача планирования, рассмотренная в настоящей главе, также как и многие ее разновидности, возникает во многих прикладных областях в ситуации, когда необходимо спланировать обслуживание запросов на ресурсы. Один из примеров - операционные системы вычислительных машин. Задача планирования со ссылкой на это конкретное приложение изложена в книге Coffman and Denning (1973).
Найти хорошую эвристику - дело важное и трудное, поэтому изучение эвристик - одна из центральных тем в искусственном интеллекте. Существуют, однако, некоторые границы, за которые невозможно выйти, двигаясь в направлении улучшения качества эвристик. Казалось бы, все, что необходимо для эффективного решения комбинаторной задачи - это найти мощную эвристику. Однако есть задачи (в том числе многие задачи планирования), для которых не существует универсальной эвристики, обеспечивающей во всех случаях как эффективность, так и допустимость. Многие теоретические результаты, имеющие отношение к этому ограничению, собраны в работе Garey and Johnson (1979).
Coffman E.G. and Denning P.J. (1973). Operating Systems Theory. Prentice-Hall.
И / ИЛИ-графы и связанные с ними алгоритмы поиска являются частью классических механизмов искусственного интеллекта для решения задач и реализации машинных игр. Ранним примером прикладной задачи, использующей эти методы, может служить программа символического интегрирования (Slagle 1963). И / ИЛИ-поиск используется в самой пролог-системе. Общее описание И / ИЛИ-графов и алгоритма можно найти в учебниках по искусственному интеллекту (Nilsson 1971; Nilsson 1980). Наша программа поиска с предпочтением - это один из вариантов алгоритма, известного под названием АО* . Формальные свойства АО* -алгоритма (включая его допустимость) изучались несколькими авторами. Подробный обзор полученных результатов можно найти в книге Pearl (1984).
Nilsson N.J. (1971). Problem-Solving Methods in Artificial Intelligence. McGraw-Hill.
Nilsson N.J. (1980). Principles of Artificial Intelligence. Tioga; also Springer-Verlag.
Pearl J. (1984). Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley.
Slagle J.R. (1963). A heuristic program that solves symbolic integration problems in freshman calculus. In: Computers and Thought (E. Feigenbaum, J. Feldman, eds.). McGraw-Hill.
Назад | Содержание | Вперёд
Книга Michie (1979) - это сборник статей, относящихся к различным аспектам экспертных систем и инженерии знаний. Две ранние экспертные системы, оказавшие большое влияние на развитие этой области, MYCIN и Prospector, описаны в Shortliffe (1976) и Duda et al (1979). Книга Buchanan and Shortliffe (1984) является хорошим сборником статей, посвященных результатам экспериментов с системой MYCIN. Weiss and Kulikowski (1984) описывают свой практический опыт разработки экспертных систем. Вопрос о работе в условиях неопределенности еще нельзя считать вполне решенным: в статье Quinlan (1983) сравниваются различные подходы к этой проблеме. Способ разработки нашей экспертной системы до некоторой степени аналогичен описанному в Hammond (1984). Некоторые примеры, использовавшиеся в тексте, заимствованы из Winston (1984), Shortliffe (1976), Duda et al (1979), Bratko (1982) и Reiter (1980).
Bratko I. (1982). Knowledge-based problem-solving in AL3. In: Machine Intelligence 10 (J.E. Hayes, D. Michie, Y.H. Pao, eds.). Ellis Horwood.
Buchanan B.G. and Shortliffe E.H. (1984, eds.). Rule-based Expert Systems: The МYСIN Experiments of the Stanford Heuristic Programming Project. Addison-Wesley.
Duda R., Gasschnig J. and Hart P. (1979). Model design in the Prospector consultant system for mineral exploration. In: Expert Systems in the Microelectronic Age (D. Michie, ed.). Edinburgh University Press.
Hammond P. (1984). vMicro-PROLOG for Expert Systems. In: Micro-PROLOG: Programming in Logic (K.L. Clark, F.G. McCabe, eds.). Prentice-Hall.
Michie D. (1979, ed.). Expert Systems in the Microelectronic Age. Edinburgh University Press.
Quinlan J.R. (1983). Inferno: a cautious approach to uncertain reasoning. The Computer Journal 26: 255-270.
Reiter J. (1980). AL/X: An Expert System Using Plausible Inference. Oxford: Intelligent Terminals Ltd.
Shortliffe E. (1976). Computer-based Medical Consultations: MYCIN. Elsevier.
Weiss S.M. and Kulikowski CA. (1984). A Practical Guide to Designing Expert Systems. Chapman and Hall.
Winston P. H. (1984). Artificial Intelligence (second edition). Addison-Wesley. [Имеется перевод первого издания: Уинстон П. Искусственный интеллект. - М.: Мир, 1980.]
Назад | Содержание | Вперёд
Минимаксный принцип, реализованный в форме альфа-бета алгоритма, - это наиболее популярный метод в игровом программировании. Особенно часто он применяется в шахматных программах. Минимаксный принцип был впервые предложен Шенноном (Shannon 1950). Возникновение и становление альфа-бета алгоритма имеет довольно запутанную историю. Несколько исследователей независимо друг от друга открыли либо реализовали этот метод полностью или частично. Эта интересная история описана в статье Knuth and Moore (1978). Там же приводится более компактная формулировка альфа-бета алгоритма, использующая вместо минимаксного принципа принцип "него-макса" ("neg-max" principle), и приводится математический анализ производительности алгоритма. Наиболее полный обзор различных минимаксных алгоритмов вместе с их теоретическим анализом содержится в книге Pearl (1984). Существует еще один интересный вопрос, относящийся к минимаксному принципу. Мы знаем, что статическим оценкам следует доверять только до некоторой степени. Можно ли считать, что рабочие оценки являются более надежными, чем исходные статические оценки, из которых они получены? В книге Pearl (1984) собран ряд математических результатов, имеющих отношение к ответу на этот вопрос. Приведенные в этой книге результаты, касающиеся распространения ошибок по минимаксному дереву, объясняют, в каких случаях и почему минимаксный принцип оказывается полезным.
Сборник статей Bramer (1983) охватывает несколько аспектов игрового программирования. Frey (1983) - хороший сборник статей по шахматным программам. Текущие разработки в области машинных шахмат регулярно освещаются в серии Advances in Computer Chess и в журнале ICCA.
Метод Языка Советов, позволяющий использовать знания о типовых ситуациях, был предложен Д. Мики. Дальнейшее развитие этого метода отражено в Bratko and Michi (1980 a, b) и Bratko (1982, 1984, 1985). Программа для игры в эндшпиле "король и ладья против короля", описанная в этой главе, совпадает с точностью до незначительных модификаций с таблицей советов, корректность которой была математически доказана в статье Bratko (1978).
Waterman and Hayes-Roth (1978) - классическая книга по системам, управляемым образцами. В книге Nilsson (1980) можно найти фундаментальные понятия, относящиеся к задаче автоматического доказательства теорем, включая алгоритм преобразования логических формул в конъюнктивную нормальную форму. Прологовская программа для выполнения этого преобразования приведена в Clocksin and Mellish (1981).
Clocksin F. W. and Mellish С S. (1981). Programming in Prolog. Springer- Verlag. [Имеется перевод: Клоксин У., Мелиш К. Программирование на языке Пролог. - М.: Мир, 1987.]
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; Springer-Verlag.
Waterman D. A. and Hayes-Roth F. (1978, eds). Pattern-Directed Inference Systems. Academic Press.
Назад | Содержание | Вперёд
Clocksin W. F. and Mellish С. S. (1981). Programming in Prolog. Springer-Verlag. [Имеется перевод: Клоксин У., Меллиш К. Программирование на языке Пролог. - М.: Мир, 1987.]
Lloyd J. W. (1984). Foundations of Logic Programming. Springer-Verlag.
Nilsson N. J. (1981). Principies of Artificial Intelligence. Tioga; Springer-Verlag.
Robinson A. J. (1965). A machine-oriented logic based on the resolution principle. JACM 12: 23-41. [Имеется перевод: Робинсон Дж. Машинно-ориентированная логика, основанная на принципе резолюции.- В кн. Кибернетический сборник, вып. 7, 1970, с. 194-218.]
Назад | Содержание | Вперёд
Различать "зеленые и "красные" отсечения предложил ван Эмден (1982).
van Emden M. (1982). Red and green cuts. Logic Programming Newsletter: 2.
Назад | Содержание | Вперёд
В этой главе мы занимались такими важными темами, как сортировка и работа со структурами данных для представления множеств. Общее описание структур данных, а также алгоритмов, запрограммированных в данной главе, можно найти, например, в Aho, Hopcroft and Ullman (1974, 1983) или Baase (1978). В литературе рассматривается также поведение этих алгоритмов, особенно их временная сложность. Хороший и краткий обзор соответствующих алгоритмов и результатов их математического анализа можно найти в Gonnet (1984).
Прологовская программа для внесения нового элемента на произвольный уровень дерева (раздел 9.3) была впервые показана автору М. Ван Эмденом (при личном общении).
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1974). The Design and Analysis of Computer Algorithms. Addison-Wesley. [Имеется перевод: Ахо А., Хопкрофт Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ. - М-: Мир, 1979.]
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1983). Data Structures and Algorithms. Addison-Wesley.
Baase S. (1978). Computer Algorithms. Addison-Wesley.
Gonnet G. H. (1984). Handbook of Algorithms and Data Structures. Addison-Wesley.
Назад | Содержание | Вперёд
Реализация на Прологе миниатюрного, не
Реализация на Прологе миниатюрного, не зависящего от конкретной игры интерпретатора языка AL0 показана на рис. 15.6. Эта программа осуществляет также взаимодействие с пользователем во время игры. Центральная задача этой программы - использовать знания, записанные в таблице советов, то есть интерпретировать программу на языке советов AL0 с целью построения форсированных деревьев и их "исполнения" в процессе игры. Базовый алгоритм порождения форсированных деревьев аналогичен поиску с предпочтением в И / ИЛИ-графах гл. 13, при этом форсированное дерево соответствует решающему И / ИЛИ-дереву. Этот алгоритм также напоминает алгоритм построения решающего дерева ответа на вопрос пользователя, применявшийся в оболочке экспертной системы (гл. 14).
Программа на рис. 15.6 составлена в предположении, что она играет белыми, а ее противник - черными. Программа запускается процедурой
line(); % Миниатюрный интерпретатор языка AL0
%
% Эта программа играет, начиная с заданной позиции,
% используя знания, записанные на языке AL0
:- ор( 200, xfy, :).
:- ор( 220, xfy, ..).
:- ор( 185, fx, если).
:- ор( 190, xfx, то).
:- ор( 180, xfy, или).
:- ор( 160, xfy, и).
:- ор( 140, fx, не).
игра( Поз) :- % Играть, начиная с Поз
игра( Поз, nil).
% Начать с пустого форсированного дерева
игра( Поз, ФорсДер) :-
отобр( Поз),
( конец_игры( Поз), % Конец игры?
write( 'Конец игры'), nl, !;
сделать_ход( Поз, ФорсДер, Поз1, ФорсДер1), !,
игра( Поз1, ФорсДер1) ).
% Игрок ходит в соответствии с форсированным деревом
сделать_ход( Поз, Ход .. ФДер1, Поз1, ФДер1) :-
чей_ход( Поз, б), % Программа играет белыми
разрход( Поз, Ход, Поз1),
показать_ход( Ход).
% Прием хода противника
сделать_ход( Поз, ФДер, Поз1, ФДер1) :-
чей_ход( Поз, ч),
write( 'Ваш ход:'),
read( Ход),
( разрход( Поз, Ход, Поз1),
поддер( ФДер, Ход, ФДер1), !;
% Вниз по форс. дереву
write( 'Неразрешенный ход'), nl,
сделать_ход( Поз, ФДер, Поз1, ФДер1) ).
% Если текущее форсированное дерево пусто, построить новое
сделать_ход( Поз, nil, Поз1, ФДер1) :-
чей_ход( Поз, б),
восст_глуб( Поз, Поз0),
% Поз0 = Поз с глубиной 0
стратегия( Поз0, ФДер), !,
% Новое форсированное дерево
сделать_ход( Поз0, ФДер, Поз1, ФДер1).
% Выбрать форсированное поддерево, соответствующее Ход' у
поддер( ФДеревья, Ход, Фдер) :-
принадлежит( Ход . . Фдер, ФДеревья), !.
поддер( _, _, nil).
стратегия( Поз, ФорсДер) :-
% Найти форс. дерево для Поз
Прав : если Условие то СписСов,
% Обращение к таблице советов
удовл( Условие, Поз, _ ), !,
% Сопоставить Поз с предварительным условием
принадлежит( ИмяСовета, СписСов),
% По очереди попробовать элем. советы
nl, write( 'Пробую'), write( ИмяСовета),
выполн_совет( ИмяСовета, Поз, ФорсДер), !.
выполн_совет( ИмяСовета, Поз, Фдер) :-
совет( ИмяСовета, Совет),
% Найти элементарный совет
выполн( Совет, Поз, Поз, ФДер).
% "выполн" требует две позиции для сравнивающих предикатов
выполн( Совет, Поз, КорнПоз, ФДер) :-
поддержка( Совет, ЦП),
удовл( ЦП, Поз, КорнПоз),
% Сопоставить Поз с целью-поддержкой
выполн1( Совет, Поз, КорнПоз, ФДер).
выполн1( Совет, Поз, КорнПоз, nil) :-
главцель( Совет, ГлЦ),
удовл( ГлЦ, Поз, КорнПоз), !.
% Главная цель удовлетворяется
выполн1( Совет, Поз, КорнПоз, Ход .. ФДеревья) :-
чей_ход( Поз, б), !, % Программа играет белыми
ходы_игрока( Совет, ХодыИгрока),
% Ограничения на ходы игрока
ход( ХодыИгрока, Поз, Ход, Поз1),
% Ход, удовлетворяющий ограничению
выполн( Совет, Поз1, КорнПоз, ФДеревья).
выполн1( Совет, Поз, КорнПоз, ФДеревья) :-
чей_ход( Поз, ч), !, % Противник играет черными
ходы_противника( Совет, ХодыПр),
bagof ( Ход . . Поз1, ход( ХодыПр, Поз, Ход, Поз1), ХПспис),
выполн_все( Совет, ХПспис, КорнПоз, ФДеревья).
% Совет выполним во всех преемниках Поз
выполн_все( _, [ ], _, [ ]).
выполн_все( Совет, [Ход . . Поз | ХПспис], КорнПоз,
[Ход . . ФД | ФДД] ) :-
выполн( Совет, Поз, КорнПоз, ФД),
выполн_все( Совет, ХПспис, КорнПоз, ФДД).
% Интерпретация главной цели и цели-поддержки:
% цель - это И / ИЛИ / НЕ комбинация. имен предикатов
удовл( Цель1 и Цель2, Поз, КорнПоз) :- !,
удовл( Цель1, Поз, КорнПоз),
удовл( Цель2, Поз, КорнПоз).
удовл( Цель1 или Цель2, Поз, КорнПоз) :- !,
( удовл( Цель1, Поз, КорнПоз);
удовл( Цель2, Поз, КорнПоз) ).
удовл( не Цель, Поз, КорнПоз) :- !,
not удовл( Цель, Поз, КорнПоз ).
удовл( Пред, Поз, КорнПоз) :-
( Усл =.. [Пред, Поз];
% Большинство предикатов не зависит от КорнПоз
Усл =.. [Пред, Поз, КорнПоз] ),
call( Усл).
% Интерпретация ограничений на ходы
ход( Ходы1 и Ходы2, Поз, Ход, Поз1) :- !,
ход( Ходы1, Поз, Ход, Поз1),
ход( Ходы2, Поз, Ход, Поз1).
ход( Ходы1 затем Ходы2, Поз, Ход, Поз1) :- !,
( ход( Ходы1, Поз, Ход, Поз1);
ход( Ходы2, Поз, Ход, Поз1) ).
% Доступ к компонентам элементарного совета
главцель( ГлЦ : _, ГлЦ).
поддержка( ГлЦ : ЦП : _, ЦП).
ходы_игрока( ГлЦ : ЦП : ХодыИгрока : _, Ходы Игрока).
ходы_противника( ГлЦ : ЦП: ХодыИгр : ХодыПр :_,
ХодыПр).
принадлежит( X, [X | Спис]).
принадлежит( X, [Y | Спис]) :-
принадлежит( X, Спис).
line(); Рис. 15. 6. Миниатюрный интерпретатор языка AL0.
игра( Поз)
где Поз - выбранная начальная позиция. Если в позиции Поз ходит противник, то программа принимает его ход, в противном случае - "консультируется" с таблицей советов, приложенной к программе, порождает форсированное дерево и делает свой ход в соответствии с этим деревом. Так продолжается до окончания игры, которое обнаруживает предикат конец_игры (например, если поставлен мат).
Форсированное дерево - это дерево ходов, представленное в программе следующей структурой:
Ход . . [ Ответ1 . . Фдер1, Ответ2 . . Фдер2, . . . ]
Здесь ".." - инфиксный оператор; Ход - первый ход "игрока"; Ответ1, Ответ2, ... - возможные ответы противника; Фдер1, Фдер2, ... - форсированные поддеревья для каждого из этих ответов.
Минимаксные игровые программы: усовершенствования и ограничения
Минимаксный принцип и альфа-бета алгоритм лежат в основе многих удачных игровых программ, чаще всего шахматных. Общая схема подобной программы такова: произвести альфа-бета поиск из текущей позиции вплоть до некоторого предела по глубине (диктуемого временными ограничениями турнирных правил). Для оценки терминальных поисковых позиций использовать подобранную специально для данной игры оценочную функцию. Затем выполнить на игровой доске наилучший ход, найденный альфа-бета алгоритмом, принять ответный ход противника и запустить тот же цикл с начала.
Таким образом, две основных составляющих игровой программы - это альфа-бета алгоритм и эвристическая оценочная функция. Для того, чтобы создать действительно хорошую программу для такой сложной игры, как шахматы, необходимо внести в эту базовую схему много различных усовершенствований. Ниже приводится краткое описание некоторых из стандартных приемов.
Многое зависит от оценочной функции. Если бы мы располагали абсолютно точной оценочной функцией, мы могли бы ограничить поиск рассмотрением только непосредственных преемников текущей позиции, фактически исключив перебор. Но для таких игр, как шахматы, любая оценочная функция, имеющая практически приемлемую вычислительную сложность, по необходимости будет всего лишь эвристической оценкой. Такая оценка базируется на "статических" свойствах позиции (например, на количестве фигур) и в одних позициях работает надежнее, чем в других. Допустим, например, что мы имеем именно такую оценочную функцию, основанную на соотношении материала, и представим себе позицию, в которой у белых лишний конь. Ясно, что оценка будет в пользу белых. Здесь все в порядке, если позиция "спокойная" и черные не располагают какой-либо сильной угрозой. Но, с другой стороны, если на следующем ходу черные могут взять белого ферзя, то такая оценка может привести к фатальному просмотру из-за своей неспособности к динамическому восприятию позиции. Очевидно, что в спокойных позициях мы можем доверять такой статической оценке в большей степени, чем в активных позициях, когда с каждой из сторон имеются непосредственные угрозы взятия фигур.
Поэтому статическую оценку следует использовать только для спокойных позиций. Что же касается активных позиций, то здесь существует такой стандартный прием: следует продолжить поиск из активной позиции за пределы ограничения по глубине и продолжать его до тех пор, пока не встретится спокойная позиция. В частности, таким образом производится просчет разменов фигур в шахматах.
Еще одно усовершенствование - эвристическое отсечение (ветвей). Целью его является достижение большей предельной глубины поиска за счет отбрасывания менее перспективных продолжений. Этот метод позволяет отсекать ветви в дополнение к тем, которые отсекаются самим альфа-бета алгоритмом. В связи с этим возникает риск пропустить какое-нибудь хорошее продолжение и неправильно вычислить минимаксную оценку.
Существует еще один прием, называемый последовательным углублением. Программа многократно выполняет альфа-бета поиск сначала до некоторой небольшой глубины, а затем, увеличивая предел по глубине при каждой итерации. Процесс завершается, когда истекает время, отведенное для вычисления очередного хода. Выполняется наилучший ход, найденный при наибольшей глубине, достигнутой программой. Этот метод имеет следующие преимущества:
он облегчает контроль времени: в момент, когда время истекает, всегда имеется некоторый ход - лучший из всех, найденных к настоящему моменту;
минимаксные оценки, вычисленные во время предыдущей итерации, можно использовать для предварительного упорядочивания позиций в следующей итерации, что помогает альфа-бета алгоритму следовать стратегии "самые сильные ходы - первыми".
Метод последовательного углубления влечет за собой некоторые накладные расходы (из-за повторного поиска в верхней части игрового дерева), но они незначительны по сравнению c суммарными затратами.
Для наших программ, основанных на описанной выше схеме, существует проблема, известная как "эффект горизонта". Представьте себе шахматную позицию, в которой программе грозит неминуемая потеря коня, однако эту потерю можно отложить, пожертвовав какую-либо менее ценную фигуру, скажем пешку.
Эта немедленная жертва сможет отодвинуть потерю коня за пределы доступной глубины поиска (за "горизонт" программы). Не видя грозящей опасности, программа отдаст предпочтение продолжению с жертвой пешки, чтобы избежать быстрой гибели своего коня. В действительности программа потеряет обе фигуры - и пешку (без необходимости), и коня. Эффект горизонта можно несколько смягчить за счет углубления поиска вплоть до спокойных позиций.
Существует, однако, более фундаментальное ограничение на возможности минимаксных игровых программ, проистекающее из той ограниченной формы представления знаний, которая в них используется. Это становится особенно заметным при сравнении лучших шахматных программ с шахматными мастерами (людьми). Хорошая программа просматривает миллионы (и даже больше) позиций, прежде чем принимает решение об очередном ходе. Психологические опыты показали, что шахматные мастера, как правило, просматривают десятки (максимум, несколько сотен) позиций. Несмотря на эту явно меньшую производительность, мастера-шахматисты обыгрывают программы без особых усилий. Преимущество их состоит в их знаниях, значительно превосходящих знания шахматных программ. Игры между машинами и сильными шахматистами показали, что огромное превосходство в вычислительной мощности не способно скомпенсировать недостаток знаний.
Знания в минимаксных игровых программах имеют следующие три основные формы:
оценочная функция
эвристики для отсечения ветвей
эвристики для распознавания спокойных позиций
Оценочная функция сводит все разнообразные аспекты игровой ситуации к одному числу, и это упрощение может нанести вред. В противоположность этому хороший игрок обладает пониманием позиции, охватывающим многие "измерения". Вот пример из области шахмат: оценочная функция оценивает позицию как равную и выдает значение 0. Оценка той же позиции, данная мастером-шахматистом, может быть значительно более информативной, а также может указывать на дальнейший ход игры, например: у белых лишняя пешка, но черные имеют неплохие атакующие возможности, что компенсирует материальный перевес, следовательно, шансы равны.
Минимаксные шахматные программы часто хорошо проявляют себя в острой тактической борьбе, когда решающее значение имеет точный просчет форсированных вариантов. Их слабости обнаруживаются в спокойных позициях, так как они не способны к долговременному планированию, преобладающему при медленной, стратегической игре. Из-за отсутствия плана создается внешнее впечатление, что программа все время перескакивает с одной идеи" на другую. Особенно это заметно в эндшпилях.
В оставшейся части главы мы рассмотрим еще один подход к программированию игр, основанный на внесении в программу знаний о типовых ситуациях при помощи так называемых "советов".