Представление списков
3. 1. Представление списков
Список - это простая структура данных, широко используемая в нечисловом программировании. Список - это последовательность, составленная из произвольного числа элементов, например энн, теннис, том, лыжи. На Прологе это записывается так:
[ энн, теннис, том, лыжи ]
Однако таково лишь внешнее представление списков. Как мы уже видели в гл. 2, все структурные объекты Пролога - это деревья. Списки не являются исключением из этого правила.
Каким образом можно представить список в виде стандартного прологовского объекта? Мы должны рассмотреть два случая: пустой список и не пустой список. В первом случае список записывается как атом [ ]. Во втором случае список следует рассматривать как структуру состоящую из двух частей:
(1) первый элемент, называемый головой списка;
(2) остальная часть списка, называемая хвостом.
Например, для списка
[ энн, теннис, том, лыжи ]
энн - это голова, а хвостом является список
[ теннис, том, лыжи ]
В общем случае, головой может быть что угодно (любой прологовский объект, например, дерево или переменная); хвост же должен быть списком. Голова соединяется с хвостом при помощи специального функтора. Выбор этого функтора зависит от конкретной реализации Пролога; мы будем считать, что это точка:
.( Голова, Хвост)
Поскольку Хвост - это список, он либо пуст, либо имеет свои собственную голову и хвост. Таким образом, выбранного способа представления списков достаточно для представления списков любой длины. Наш список представляется следующим образом:
.( энн, .( теннис, .( том, .( лыжи, [ ] ) ) ) )
На Рисунок 3.1 изображена соответствующая древовидная структура. Заметим, что показанный выше пример содержит пустой список [ ]. Дело в том, что самый последний хвост является одноэлементным списком:
[ лыжи ]
Хвост этого списка пуст
[ лыжи ] = .( лыжи, [ ] )
Рассмотренный пример показывает, как общий принцип структуризации объектов данных можно применить к спискам любой длины. Из нашего примера также видно, что такой примитивный способ представления в случае большой глубины вложенности подэлементов в хвостовой части списка может привести к довольно запутанным выражениям. Вот почему в Прологе предусматривается более лаконичный способ изображения списков, при котором они записываются как последовательности элементов, заключенные в квадратные скобки. Программист может использовать оба способа, но представление с квадратными скобками, конечно, в большинстве случаев пользуется предпочтением. Мы, однако, всегда будем помнить, что это всего лишь косметическое улучшение и что во внутреннем представлении наши списки выглядят как деревья. При выводе же они автоматически преобразуются в более лаконичную форму представления. Так, например, возможен следующий диалог:
?- Список1 = [а, b, с],
Список2 = (a, .(b, .(c,[ ]) ) ).
Список1 = [а, b, с]
Список2 = [а, b, с]
?- Увлечения1 = .( теннис, .(музыка, [ ] ) ),
Увлечения2 = [лыжи, еда],
L = [энн, Увлечения1, том, Увлечения2].
Увлечения1 = [теннис, музыка]
Увлечения2 = [лыжи, еда]
L = [энн, [теннис, музыка], том, [лыжи, еда]]
Принадлежность к списку
3. 2. 1. Принадлежность к списку
Мы представим отношение принадлежности как
принадлежит( X, L)
где Х - объект, а L - список. Цель принадлежит( X, L) истинна, если элемент Х встречается в L. Например, верно что
принадлежит( b, [а, b, с] )
и, наоборот, не верно, что
принадлежит b, [а, [b, с] ] )
но
принадлежит [b, с], [а, [b, с]] )
истинно. Составление программы для отношения принадлежности может быть основано на следующих соображениях:
(1) Х есть голова L, либо
(2) Х принадлежит хвосту L.
Это можно записать в виде двух предложений, первое из которых есть простой факт, а второе - правило:
принадлежит( X, [X | Хвост ] ).
принадлежит ( X, [Голова | Хвост ] ) :-
принадлежит( X, Хвост).
Сцепление ( конкатенация)
3. 2. 2. Сцепление ( конкатенация)
Для сцепления списков мы определим отношение
конк( L1, L2, L3)
Здесь L1 и L2 - два списка, a L3 - список, получаемый при их сцеплении. Например,
конк( [а, b], [c, d], [a, b, c, d] )
истинно, а
конк( [а, b], [c, d], [a, b, a, c, d] )
ложно. Определение отношения конк, как и раньше, содержит два случая в зависимости от вида первого аргумента L1:
(1) Если первый аргумент пуст, тогда второй и третий аргументы представляют собой один и тот же список (назовем его L), что выражается в виде следующего прологовского факта:
конк( [ ], L, L ).
(2) Если первый аргумент отношения конк не пуст, то он имеет голову и хвост в выглядит так:
[X | L1]
На Рисунок 3.2 показано, как производится сцепление списка [X | L1] с произвольным списком L2. Результат сцепления - список [X | L3], где L3 получен после сцепления списков L1 и L2. На прологе это можно записать следующим образом:
конк( [X | L1, L2, [X | L3]):-
конк( L1, L2, L3).
Добавление элемента
3. 2. 3. Добавление элемента
Наиболее простой способ добавить элемент в список - это вставить его в самое начало так, чтобы он стал его новой головой. Если Х - это новый элемент, а список, в который Х добавляется - L, тогда результирующий список - это просто
[X | L]
Таким образом, для того, чтобы добавить новый элемент в начало списка, не надо использовать никакой процедуры. Тем не менее, если мы хотим определить такую процедуру в явном виде, то ее можно представить в форме такого факта:
добавить( X, L, [X | L] ).
Удаление элемента
3. 2. 4. Удаление элемента
Удаление элемента Х из списка L можно запрограммировать в виде отношения
удалить( X, L, L1)
где L1 совпадает со списком L, у которого удален элемент X. Отношение удалить можно определить аналогично отношению принадлежности. Имеем снова два случая:
(1) Если Х является головой списка, тогда результатом удаления будет хвост этого списка.
(2) Если Х находится в хвосте списка, тогда его нужно удалить оттуда.
удалить( X, [X | Хвост], Хвост).
удалить( X, [Y | Хвост], [ Y | Хвост1] ) :-
удалить( X, Хвост, Хвост1).
как и принадлежит, отношение удалить по природе своей недетерминировано. Если в списке встречается несколько вхождений элемента X, то удалить сможет исключить их все при помощи возвратов. Конечно, вычисление по каждой альтернативе будет удалять лишь одно вхождение X, оставляя остальные в неприкосновенности. Например:
?- удалить( а, [а, b, а, а], L].
L = [b, а, а];
L = [а, b, а];
L = [а, b, а];
nо (нет)
При попытке исключить элемент, не содержащийся в списке, отношение удалить потерпит неудачу.
Отношение удалить можно использовать в обратном направлении для того, чтобы добавлять элементы в список, вставляя их в произвольные места. Например, если мы хотим во все возможные места списка [1, 2, 3] вставить атом а, то мы можем это сделать, задав вопрос: "Каким должен быть список L, чтобы после удаления из него элемента а получился список [1, 2, 3]?"
?- удалить( а, L, [1, 2, 3] ).
L = [а, 1, 2, 3];
L = [1, а, 2, 3];
L = [1, 2, а, 3];
L = [1, 2, 3, а];
nо (нет)
Вообще операция по внесению Х в произвольное место некоторого списка Список, дающее в результате БольшийСписок, может быть определена предложением:
внести( X, Список, БольшийСписок) :-
удалить( X, БольшийСписок, Список).
В принадлежит1 мы изящно реализовали отношение принадлежности через конк. Для проверки на принадлежность можно также использовать и удалить. Идея простая: некоторый Х принадлежит списку Список, если Х можно из него удалить:
принадлежит2( X, Список) :-
удалить( X, Список, _ ).
Подсписок
3. 2. 5. Подсписок
Рассмотрим теперь отношение подсписок. Это отношение имеет два аргумента - список L и список S, такой, что S содержится в L в качестве подсписка. Так отношение
подсписок( [c, d, e], [a, b, c, d, e, f] )
имеет место, а отношение
подсписок( [c, e], [a, b, c, d, e, f] )
нет. Пролог-программа для отношения подсписок может основываться на той же идее, что и принадлежит1, только на этот раз отношение более общо (см. Рисунок 3.4).
Перестановки
3. 2. 6. Перестановки
Иногда бывает полезно построить все перестановки некоторого заданного списка. Для этого мы определим отношение перестановка с двумя аргументами. Аргументы - это два списка, один из которых является перестановкой другого. Мы намереваемся порождать перестановки списка с помощью механизма автоматического перебора, используя процедуру перестановка, подобно тому, как это делается в следующем примере:
?- перестановка( [а, b, с], Р).
Р = [а, b, с];
Р = [а, с, b];
Р = [b, а, с];
. . .
Некоторые операции над списками
3. 2. Некоторые операции над списками
Списки можно применять для представления множеств, хотя и существует некоторое различие между этими понятиями: порядок элементов множества не существенен, в то время как для списка этот порядок имеет значение; кроме того, один н тот же объект может встретиться в списке несколько раз. Однако наиболее часто используемые операции над списками аналогичны операциям над множествами. Среди них проверка, является ли некоторый объект элементом списка, что соответствует проверке объекта на принадлежность множеству; конкатенация (сцепление) двух списков, что соответствует объединению множеств; добавление нового объекта в список или удаление некоторого объекта из него.
В оставшейся части раздела мы покажем программы, реализующие эти и некоторые другие операции над списками.
Операторная запись (нотация)
3. 3. Операторная запись (нотация)
В математике мы привыкли записывать выражения в таком виде:
2*a + b*с
где + и * - это операторы, а 2, а, b, с - аргументы. В частности, + и * называют инфиксными операторами, поскольку они появляются между своими аргументами. Такие выражения могут быть представлены в виде деревьев, как это сделано на Рисунок 3.6, и записаны как прологовские термы с + и * в качестве функторов:
+( *( 2, а), *( b, с) )
Арифметические действия
3. 4. Арифметические действия
Пролог рассчитан главным образом на обработку символьной информации, при которой потребность в арифметических вычислениях относительно мала. Поэтому и средства для таких вычислений довольно просты. Для осуществления основных арифметических действий можно воспользоваться несколькими предопределенными операторами.
+ сложение
- вычитание
* умножение
/ деление
mod модуль, остаток от целочисленного деления
Заметьте, что это как раз тот исключительный случай. когда оператор может и в самом деле произвести некоторую операцию. Но даже и в этом случае требуется дополнительное указание на выполнение действия. Пролог-система знает, как выполнять вычисления, предписываемые такими операторами, но этого недостаточно для их непосредственного использования. Следующий вопрос - наивная попытка произвести арифметическое действие:
?- Х = 1 + 2.
Пролог-система "спокойно" ответит
Х = 1 + 2
а не X = 3, как, возможно, ожидалось. Причина этого проста: выражение 1 + 2 обозначает лишь прологовский терм, в котором + является функтором, а 1 и 2 - его аргументами. В вышеприведенной цели нет ничего, что могло бы заставить систему выполнить операцию сложения. Для этого в Прологе существует специальный оператор is (есть). Этот оператор заставит систему выполнить вычисление. Таким образом, чтобы правильно активизировать арифметическую операцию, надо написать:
?- Х is 1 + 2.
Вот теперь ответ будет
Х = 3
Сложение здесь выполняется специальной процедурой, связанной с оператором +. Мы будем называть такие процедуры встроенными.
В Прологе не существует общепринятой нотации для записи арифметических действий, поэтому в разных реализациях она может слегка различаться. Например, оператор '/' может в одних реализациях обозначать целочисленное деление, а в других - вещественное. В данной книге под '/' мы подразумеваем вещественное деление, для целочисленного же будем использовать оператор div. В соответствии с этим, на вопрос
?- Х is 3/2,
Y is 3 div 2.
ответ должен быть такой:
Х = 1.5
Y = 1
Левым аргументом оператора is является простой объект. Правый аргумент - арифметическое выражение, составленное с помощью арифметических операторов, чисел и переменных. Поскольку оператор is запускает арифметические вычисления, к моменту начала вычисления этой цели все ее переменные должны быть уже конкретизированы какими-либо числами. Приоритеты этих предопределенных арифметических операторов (см. Рисунок 3.8) выбраны с таким расчетом, чтобы операторы применялись к аргументам в том порядке, который принят в математике. Чтобы изменить обычный порядок вычислений, применяются скобки (тоже, как в математике). Заметьте, что +, -, *, / и div определены, как yfx, что определяет порядок их выполнения слева направо. Например,
Х is 5 - 2 - 1
понимается как
X is (5 - 2) - 1
Арифметические операции используются также и при сравнении числовых величин. Мы можем, например, проверить, что больше - 10000 или результат умножения 277 на 37, с помощью цели
?- 277 * 37 > 10000.
yes
(да)
Заметьте, что точно так же, как и is, оператор '>' вызывает выполнение вычислений.
Предположим, у нас есть программа, в которую входит отношение рожд, связывающее имя человека с годом его рождения. Тогда имена людей, родившихся между 1950 и 1960 годами включительно, можно получить при помощи такого вопроса:
?- рожд( Имя, Год),
Год >= 1950,
Год <= 1960.
Ниже перечислены операторы сравнения:
Х > Y Х больше Y
Х < Y Х меньше Y
Х >= Y Х больше или равен Y
Х =< Y Х меньше или равен Y
Х =:= Y величины Х и Y совпадают (равны)
Х =\= Y величины Х и Y не равны
Обратите внимание на разницу между операторами сравнения '=' и '=:=', например, в таких целях как X = Y и Х =:= Y. Первая цель вызовет сопоставление объектов Х и Y, и, если Х и Y сопоставимы, возможно, приведет к конкретизации каких-либо переменных в этих объектах. Никаких вычислений при этом производиться не будет. С другой стороны, Х =:= Y вызовет арифметическое вычисление и не может привести к конкретизации переменных. Это различие можно проиллюстрировать следующими примерами:
?- 1 + 2 =:= 2 + 1.
yes
>- 1 + 2 = 2 + 1.
no
?- 1 + А = В + 2.
А = 2
В = 1
Давайте рассмотрим использование арифметических операций на двух простых примерах. В первом примере ищется наибольший общий делитель; во втором - определяется количество элементов в некотором списке.
Если заданы два целых числа Х и Y, то их наибольший общий делитель Д можно найти, руководствуясь следующими тремя правилами:
(1) Если Х и Y равны, то Д равен X.
(2) Если Х > Y, то Д равен наибольшему общему делителю Х разности Y - X.
(3) Если Y < X, то формулировка аналогична правилу (2), если Х и Y поменять в нем местами.
На примере легко убедиться, что эти правила действительно позволяют найти наибольший общий делитель. Выбрав, скажем, Х = 20 и Y = 25, мы, руководствуясь приведенными выше правилами, после серии вычитаний получим Д = 5.
Эти правила легко сформулировать в виде прологовской программы, определив трехаргументное отношение, скажем
нод( X , Y, Д)
Тогда наши три правила можно выразить тремя предложениями так:
нод( X, X, X).
нод( X, Y, Д) :-
Х < Y,
Y1 is Y - X,
нод( X, Y1, Д),
нод( X, Y, Д) :-
Y < X,
нод( Y, X, Д).
Разумеется, с таким же успехом можно последнюю цель в третьем предложении заменить двумя:
X1 is Х - Y,
нод( X1, Y, Д)
В нашем следующем примере требуется произвести некоторый подсчет, для чего, как правило, необходимы арифметические действия. Примером такой задачи может служить вычисление длины какого-либо списка; иначе говоря, подсчет числа его элементов. Определим процедуру
длина( Список, N)
которая будет подсчитывать элементы списка Список и конкретизировать N полученным числом. Как и раньше, когда речь шла о списках, полезно рассмотреть два случая:
(1) Если список пуст, то его длина равна 0.
(2) Если он не пуст, то Список = [Голова1 | Хвост] и его длина равна 1 плюс длина хвоста Хвост.
Эти два случая соответствуют следующей программе:
длина( [ ], 0).
длина( [ _ | Хвост], N) :-
длина( Хвост, N1),
N is 1 + N1.
Применить процедуру длина можно так:
?- длина( [a, b, [c, d], e], N).
N = 4
Заметим, что во втором предложении этой процедуры две цели его тела нельзя поменять местами. Причина этого состоит в том, что переменная N1 должна быть конкретизирована до того, как начнет вычисляться цель
N is 1 + N1
Таким образом мы видим, что введение встроенной процедуры is привело нас к примеру отношения, чувствительного к порядку обработки предложений и целей. Очевидно, что процедурные соображения для подобных отношений играют жизненно важную роль.
Интересно посмотреть, что произойдет, если мы попытаемся запрограммировать отношение длина без использования is. Попытка может быть такой:
длина1( [ ], 0).
длина1( [ _ | Хвост], N) :-
длина1( Хвост, N1),
N = 1 + N1.
Теперь уже цель
?- длина1( [a, b, [c, d], e], N).
породит ответ:
N = 1+(1+(1+(1+0)))
Сложение ни разу в действительности не запускалось и поэтому ни разу не было выполнено. Но в процедуре длина1, в отличие от процедуры длина, мы можем поменять местами цели во втором предложении:
длина1( _ | Хвост], N) :-
N = 1 + N1,
длина1( Хвост, N1).
Такая версия длина1 будет давать те же результаты, что и исходная. Ее можно записать короче:
длина1( [ _ | Хвост], 1 + N) :-
длина1( Хвост, N).
и она и в этом случае будет давать те же результаты. С помощью длина1, впрочем, тоже можно вычислять количество элементов списка:
?- длина( [а, b, с], N), Длина is N.
N = 1+(1+(l+0))
Длина = 3
Итак: Для выполнения арифметических действий используются встроенные процедуры. Арифметические операции необходимо явно запускать при помощи встроенной процедуры is. Встроенные процедуры связаны также с предопределенными операторами +, -, *, /, div и mod. К моменту выполнения операций все их аргументы должны быть конкретизированы числами. Значения арифметических выражений можно сравнивать с помощью таких операторов, как <, =< и т.д. Эти операторы вычисляют значения своих аргументов.
часто используемая структура. Он либо
Резюме
Список - часто используемая структура. Он либо пуст, либо состоит из головы и хвоста, который в свою очередь также является списком. Для списков в Прологе имеется специальная нотация. В данной главе рассмотрены следующие операции над списками: принадлежность к списку, конкатенация, добавление элемента, удаление элемента, удаление подсписка. Операторная запись позволяет программисту приспособить синтаксис программ к своим конкретным нуждам. С помощью операторов можно значительно повысить наглядность программ. Новые операторы определяются с помощью директивы ор, в которой указываются его имя, тип и приоритет. Как правило, с оператором не связывается никакой операции; оператор это просто синтаксическое удобство, обеспечивающее альтернативный способ записи термов. Арифметические операции выполняются с помощью встроенных процедур. Вычисление арифметических выражений запускается процедурой is, а также предикатами сравнения <, =< и т.д. Понятия, введенные в данной главе:
список, голова списка, хвост списка
списковая нотация
операторы, операторная нотация
инфиксные, префиксные и постфиксные
операторы
приоритет операторов
арифметические встроенные процедуры
Представление списка [энн теннис том лыжи] в виде дерева
Рисунок 3. 1. Представление списка [энн, теннис, том, лыжи] в виде дерева.

Приведенный пример также напоминает вам о том, что элементами списка могут быть любые объекты, в частности тоже списки.
На практике часто бывает удобным трактовать хвост списка как самостоятельный объект. Например, пусть
L = [а, b, с]
Тогда можно написать:
Хвост = [b, с] и L = .(а, Хвост)
Для того, чтобы выразить это при помощи квадратных скобок, в Прологе предусмотрено еще одно расширение нотации для представления списка, а именно вертикальная черта, отделяющая голову от хвоста:
L = [а | Хвост]
На самом деле вертикальная черта имеет более общий смысл: мы можем перечислить любое количество элементов списка, затем поставить символ " | ", а после этого - список остальных элементов. Так, только что рассмотренный пример можно представить следующими различными способами:
[а, b, с] = [а | [b, с]] = [a, b | [c]] = [a, b, c | [ ]]
Подытожим:
Список - это структура данных, которая либо пуста, либо состоит из двух частей: головы и хвоста. Хвост в свою очередь сам является списком.
Список рассматривается в Прологе как специальный частный случай двоичного дерева. Для повышения наглядности программ в Прологе предусматриваются специальные средства для списковой нотации, позволяющие представлять списки в виде
[ Элемент1, Элемент2, ... ]
или
[ Голова | Хвост ]
или
[ Элемент1, Элемент2, ... | Остальные]
Конкатенация списков
Рисунок 3. 2. Конкатенация списков.

Составленную программу можно теперь использовать для сцепления заданных списков, например:
?- конк( [a, b, с], [1, 2, 3], L ).
L = [a, b, c, 1, 2, 3]
?- конк( [а, [b, с], d], [а, [ ], b], L ).
L = [a, [b, c], d, а, [ ], b]
Хотя программа для конк выглядит довольно просто, она обладает большой гибкостью и ее можно использовать многими другими способами. Например, ее можно применять как бы в обратном направлении для разбиения заданного списка на две части:
?- конк( L1, L2, [а, b, с] ).
L1 = [ ]
L2 = [а, b, c];
L1 = [а]
L2 = [b, с];
L1 = [а, b]
L2 = [c];
L1 = [а, b, с]
L2 = [ ];
no (нет)
Список [а, b, с] разбивается на два списка четырьмя способами, и все они были обнаружены нашей программой при помощи механизма автоматического перебора.
Нашу программу можно также применить для поиска в списке комбинации элементов, отвечающей некоторому условию, задаваемому в виде шаблона или образца. Например, можно найти все месяцы, предшествующие данному, и все месяцы, следующие за ним, сформулировав такую цель:
?- конк( До, [май | После ],
[янв, фев, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
До = [янв, фев, март, апр]
После = [июнь, июль, авг, сент, окт, ноябрь, дек].
Далее мы сможем найти месяц, непосредственно предшествующий маю, и месяц, непосредственно следующий за ним, задав вопрос:
?- конк( _, [Месяц1, май, Месяц2 | _ ],
[янв, февр, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
Месяц1 = апр
Месяц2 = июнь
Более того, мы сможем, например, удалить из некоторого списка L1 все, что следует за тремя последовательными вхождениями элемента z в L1 вместе с этими тремя z. Например, это можно сделать так:
?- L1 = [a, b, z, z, c, z, z, z, d, e],
конк( L2, [z, z, z | _ ], L1).
L1 = [a, b, z, z, c, z, z, z, d, e]
L2 = [a, b, z, z, c]
Мы уже запрограммировали отношение принадлежности. Однако, используя конк, можно было бы определить это отношение следующим эквивалентным способом:
принадлежит1( X, L) :-
конк( L1, [X | L2], L).
Рисунок 3. 3. Процедура принадлежит1 находит элемент в заданном
списке, производя по нему последовательный поиск.

В этом предложении сказано: " X принадлежит L, если список L можно разбить на два списка таким образом, чтобы элемент Х являлся головой второго из них. Разумеется, принадлежит1 определяет то же самое отношение, что и принадлежит. Мы использовали другое имя только для того, чтобы различать таким образом две разные реализации этого отношения, Заметим, что, используя анонимную переменную, можно записать вышеприведенное предложение так:
принадлежит1( X, L) :-
конк( _, [X | _ ], L).
Интересно сравнить между собой эти две реализации отношения принадлежности. Принадлежит имеет довольно очевидный процедурный смысл:
Для проверки, является ли Х элементом списка L, нужно
(1) сначала проверить, не совпадает ли голова списка L с X, а затем
(2) проверить, не принадлежит ли Х хвосту списка L.
С другой стороны, принадлежит1, наоборот, имеет очевидный декларативный смысл, но его процедурный смысл не столь очевиден.
Интересным упражнением было бы следующее: выяснить, как в действительности принадлежит1 что-либо вычисляет. Некоторое представление об этом мы получим, рассмотрев запись всех шагов вычисления ответа на вопрос:
?- принадлежит1( b, [а, b, с] ).
На Рисунок 3.3 приведена эта запись. Из нее можно заключить, что принадлежит1 ведет себя точно так же, как и принадлежит. Он просматривает список элемент за элементом до тех пор, пока не найдет нужный или пока не кончится список.
Отношения принадлежит и подсписок
Рисунок 3. 4. Отношения принадлежит и подсписок.

Его можно сформулировать так:
S является подсписком L, если
(1) L можно разбить на два списка L1 и L2 и
(2) L2 можно разбить на два списка S и L3.
Как мы видели раньше, отношение конк можно использовать для разбиения списков. Поэтому вышеприведенную формулировку можно выразить на Прологе так:
подсписок( S, L) :-
конк( L1, L2, L),
конк( S, L3, L2).
Ясно, что процедуру подсписок можно гибко использовать различными способами. Хотя она предназначалась для проверки, является ли какой-либо список подсписком другого, ее можно использовать, например, для нахождения всех подсписков данного списка:
?- подсписок( S, [а, b, с] ).
S = [ ];
S = [a];
S = [а, b];
S = [а, b, с];
S = [b];
. . .
Один из способов построения перестановки списка [X | L]
Рисунок 3. 5. Один из способов построения перестановки списка [X | L].

Программа для отношения перестановка в свою очередь опять может основываться на рассмотрении двух случаев в зависимости от вида первого списка:
(1) Если первый список пуст, то и второй список должен быть пустым.
(2) Если первый список не пуст, тогда он имеет вид [Х | L], и перестановку такого списка можно построить так, как Это показано на Рисунок 3.5: вначале получить список L1 - перестановку L, а затем внести Х в произвольную позицию L1.
Два прологовских предложения, соответствующих этим двум случаям, таковы:
перестановка( [ ], [ ]).
перестановка( [X | L ], Р) :-
перестановка( L, L1),
внести( X, L1, Р).
Другой вариант этой программы мог бы предусматривать удаление элемента Х из первого списка, перестановку оставшейся его части - получение списка Р, а затем добавление Х в начало списка Р. Соответствующая программа такова:
перестановка2( [ ], [ ]).
перестановка2( L, [X | Р] ) :-
удалить( X, L, L1),
перестановка2( L1, Р).
Поучительно проделать несколько экспериментов с нашей программой перестановки. Ее нормальное использование могло бы быть примерно таким:
?- перестановка( [красный, голубой, зеленый], Р).
Как и предполагалось, будут построены все шесть перестановок:
Р = [ красный, голубой, зеленый];
Р = [ красный, зеленый, голубой];
Р = [ голубой, красный, зеленый];
Р = [ голубой, зеленый, красный];
Р = [ зеленый, красный, голубой];
Р = [ зеленый, голубой, красный];
nо (нет)
Приведем другой вариант использования процедуры перестановка:
?- перестановка( L, [а, b, с] ).
Наша первая версия, перестановка, произведет успешную конкретизацию L всеми шестью перестановками. Если пользователь потребует новых решений, он никогда не получит ответ "нет", поскольку программа войдет в бесконечный цикл, пытаясь отыскать новые несуществующие перестановки. Вторая версия, перестановка2, в этой ситуации найдет только первую (идентичную) перестановку, а затем сразу зациклится. Следовательно, при использовании этих отношений требуется соблюдать осторожность.
Представление выражения 2*а+b*с в виде дерева
Рисунок 3. 6. Представление выражения 2*а+b*с в виде дерева.

Поскольку мы обычно предпочитаем записывать такие выражения в привычной инфиксной форме операторов, Пролог обеспечивает такое удобство. Поэтому наше выражение, записанное просто как
2*а + b*с
будет воспринято правильно. Однако это лишь внешнее представление объекта, которое будет автоматически преобразовано в обычную форму прологовских термов. Такой терм выводится пользователю снова в своей внешней инфиксной форме.
Выражения рассматриваются Прологом просто как дополнительный способ записи, при котором не вводятся какие-либо новые принципы структуризации объектов данных. Если мы напишем а + b, Пролог поймет эту запись, как если бы написали +(а, b). Для того, чтобы Пролог правильно воспринимал выражения типа а + b*с, он должен знать, что * связывает сильнее, чем +. Будем говорить, что + имеет более низкий приоритет, чем *. Поэтому верная интерпретация выражений зависит от приоритетов операторов. Например, выражение а + b*с, в принципе можно понимать и как
+( а, *( b, с) )
и как
*( +( а, b), с)
Общее правило состоит в том, что оператор с самым низким приоритетом расценивается как главный функтор терма. Если мы хотим, чтобы выражения, содержащие + и *, понимались в соответствии с обычными соглашениями, то + должен иметь более низкий приоритет, чем *. Тогда выражение а + b*с означает то же, что и а + (b*с). Если имеется в виду другая интерпретация, то это надо указать явно с помощью скобок, например ( а+b)*с.
Программист может вводить свои собственные операторы. Так, например, можно определить атомы имеет и поддерживает в качестве инфиксных операторов, а затем записывать в программе факты вида:
питер имеет информацию.
пол поддерживает стол.
Эти факты в точности эквивалентны следующим:
имеет( питер, информацию).
поддерживает( пол, стол).
Программист определяет новые операторы, вводя в программу особый вид предложений, которые иногда называют директивами. Такие предложения играют роль определений новых операторов. Определение оператора должно появиться в программе раньше, чем любое выражение, использующее этот оператор. Например, оператор имеет можно определить директивой
:- ор( 600, xfx, имеет).
Такая запись сообщит Прологу, что мы хотим использовать "имеет" в качестве оператора с приоритетом 600 и типом 'xfx', обозначающий одну из разновидностей инфиксного оператора. Форма спецификатора 'xfx' указывает на то, что оператор, обозначенный через 'f', располагается между аргументами, обозначенными через 'х'.
Обратите внимание на то, что определения операторов не содержат описания каких-либо операций или действий. В соответствии с принципами языка ни с одним оператором не связывается каких-либо операций над данными (за исключением особых, редких случаев). Операторы обычно используются так же, как и функторы, только для объединения объектов в структуры и не вызывают действия над данными, хотя само слово "оператор", казалось бы, должно подразумевать какое-то действие.
Имена операторов это атомы, а их приоритеты - точнее, номера их приоритетов - должны находиться в некотором диапазоне, зависящем от реализации. Мы будем считать, что этот диапазон располагается в пределах от 1 до 1200.(Чем выше приоритет, тем меньше его номер. - Прим. перев.)
Существуют три группы типов операторов, обозначаемые спецификаторами, похожими на xfx:
(1) инфиксные операторы трех типов:
xfx xfy yfx
(2) префиксные операторы двух типов:
fx fy
(3) постфиксные операторы двух типов:
хf yf
Спецификаторы выбраны с таким расчетом, чтобы нагляднее отразить структуру выражения, в котором 'f' соответствует оператору, а 'х' и 'у' представляют его аргументы. Расположение 'f' между аргументами указывает на то, что оператор инфиксный. Префиксные и постфиксные спецификаторы содержат только один аргумент, который, соответственно, либо следует за оператором, либо предшествует ему.
Две интерпретации
Рисунок 3. 7. Две интерпретации выражения а-b-с в предположении, что '-' имеет приоритет 500. Если тип '-' есть yfx, то интерпретация 2 неверна, так как приоритет b-с не выше, чем приоритет '-'.

Между 'х' и 'у' есть разница. Для ее объяснения нам потребуется ввести понятие приоритета аргумента. Если аргумент заключен в скобки или не имеет структуры (является простым объектом), тогда его приоритет равен 0; если же он структурный, тогда его приоритет равен приоритету его главного функтора. С помощью 'х' обозначается аргумент, чей приоритет должен быть строго выше приоритета оператора (т. е. его номер строго меньше номера приоритета оператора); с помощью 'у' обозначается аргумент, чей приоритет выше или равен приоритету оператора.
Такие правила помогают избежать неоднозначности при обработке выражений, в которых встречаются операторы с одинаковым приоритетом. Например, выражение
а-b-с
обычно понимается как (а-b)-с , а не как а-(b-с). Чтобы обеспечить такую обычную интерпретацию, оператор '-' следует определять как yfx. На Рисунок 3.7 показано, каким образом исключается вторая интерпретация.
В качестве еще одного примера рассмотрим оператор not (логическое отрицание "не"). Если not oпределён как fy, тогда выражение
not not р
записано верно; однако, если not определен как fx, оно некорректно, потому что аргументом первого not является структура not p, которая имеет тот же приоритет, что и not. В этом случае выражение следует писать со скобками:
not (not р)
line();:- ор( 1200, xfx, ':-').
:- ор( 1200, fx, [:-, ?-] ).
:- op( 1100, xfy, ';').
:- ор( 1000, xfy, ',').
:- op( 700, xfx, [=, is, <, >, =<, >=, ==, =\=, \==, =:=]).
:- op( 500, yfx, [+, -] ).
:- op( 500, fx, [+, -, not] ).
:- op( 400, yfx, [*, /, div] ).
:- op( 300, xfx, mod).
line();Множество предопределенных операторов
Рисунок 3. 8. Множество предопределенных операторов.
Для удобства некоторые операторы в пролог-системах определены заранее, чтобы ими можно было пользоваться сразу, без какого-либо определения их в программе. Набор таких операторов и их приоритеты зависят от реализации. Мы будем предполагать, что множество этих "стандартных" операторов ведет себя так, как если бы оно было определено с помощью предложений, приведенных на Рисунок 3.8. Как видно из того же рисунка, несколько операторов могут быть определены в одном предложении, если только они все имеют одинаковый приоритет и тип. В этом случае имена операторов записываются в виде списка. Использование операторов может значительно повысить наглядность, "читабельность" программы. Для примера предположим, что мы пишем программу для обработки булевских выражений. В такой программе мы, возможно, захотим записать утверждение одной из теорем де Моргана, которое в математических обозначениях записывается так:
~ (А & В) <===> ~А v ~В
Приведем один из способов записи этого утверждения в виде прологовского предложения:
эквивалентно( not( и( А, В)), или( not( A, not( B))).
Однако хорошим стилем программирования было бы попытаться сохранить по возможности больше сходства между видом записи исходной задачи и видом, используемом в программе ее решения. В нашем примере этого можно достичь почти в полной мере, применив операторы. Подходящее множество операторов для наших целей можно определить так:
:- ор( 800, xfx, <===>).
:- ор( 700, xfy, v).
:- ор( 600, хfу, &).
:- ор( 500, fy, ~).
Теперь правило де Моргана можно записать в виде следующего факта:
~(А & В) <===> ~А v ~В.
В соответствии с нашими определениями операторов этот терм понимается так, как это показано на Рисунок 3.9.
Интерпретация терма ~(А & В) <===> ~A v ~В
Рисунок 3. 9. Интерпретация терма ~(А & В) <===> ~A v ~В

Подытожим: Наглядность программы часто можно улучшить, использовав операторную нотацию. Операторы бывают инфиксные, префиксные и постфиксные. В принципе, с оператором не связываются никакие действия над данными, за исключением особых случаев. Определение оператора не содержит описания каких-либо действий, оно лишь вводит новый способ записи. Операторы, как и функторы, лишь связывают компоненты в единую структуру. Программист может вводить свои собственные операторы. Каждый оператор определяется своим именем, приоритетом и типом. Номер приоритета - это целое число из некоторого диапазона, скажем, между 1 и 1200. Оператор с самым больший номером приоритета соответствует главному функтору выражения, в котором этот оператор встретился. Операторы с меньшими номерами приоритетов связывают свои аргументы сильнее других операторов. Тип оператора зависит от двух условий: (1) его расположения относительно своих аргументов, (2) приоритета его аргументов по сравнению с его собственным. В спецификаторах, таких, как xfy, х обозначает аргумент, чей номер приоритета строго меньше номера приоритета оператора; у - аргумент с номером приоритета, меньшим или равным номеру приоритета оператора.
Используя отношение конк, напишите цель,
Упражнения
3. 1. (а) Используя отношение конк, напишите цель, соответствующую вычеркиванию трех последних элементов списка L, результат - новый список L1. Указание: L - конкатенация L1 и трехэлементного списка.
(b) Напишите последовательность целей для порождения списка L2, получающегося из списка L вычеркиванием его трех первых и трех последних элементов.
Посмотреть ответ
3. 2. Определите отношение
последний( Элемент, Список)
так, чтобы Элемент являлся последним элементом списка Список. Напишите два варианта определения: (а) с использованием отношения конк, (b) без использования этого отношения.
Посмотреть ответ
Упражнения
3. 3. Определите два предиката
четнаядлина( Список) и нечетнаядлина( Список)
таким образом, чтобы они были истинными, если их аргументом является список четной или нечетной длины соответственно. Например, список [а, b, с, d] имеет четную длину, a [a, b, c] - нечетную.
Посмотреть ответ
3. 4. Определите отношение
обращение( Список, ОбращенныйСписок),
которое обращает списки. Например,
обращение( [a, b, c, d], [d, c, b, a] ).
Посмотреть ответ
3. 5. Определите предикат
палиндром( Список).
Список называется палиндромом, если он читается одинаково, как слева направо, так и справа налево. Например, [м, а, д, а, м].
Посмотреть ответ
3. 6. Определите отношение
сдвиг( Список1, Список2)
таким образом, чтобы Список2 представлял собой Список1, "циклически сдвинутый" влево на один символ. Например,
?- сдвиг( [1, 2, 3, 4, 5], L1),
сдвиг1( LI, L2)
дает
L1 = [2, 3, 4, 5, 1]
L2 = [3, 4, 5, 1, 2]
Посмотреть ответ
3. 7. Определите отношение
перевод( Список1, Список2)
для перевода списка чисел от 0 до 9 в список соответствующих слов. Например,
перевод( [3, 5, 1, 3], [три, пять, один, три] )
Используйте в качестве вспомогательных следующие отношения:
означает( 0, нуль).
означает( 1, один).
означает( 2, два).
. . .
Посмотреть ответ
3. 8. Определите отношение
подмножество( Множество, Подмножество)
где Множество и Подмножество - два списка представляющие два множества. Желательно иметь возможность использовать это отношение не только для проверки включения одного множества в другое, но и для порождения всех возможных подмножеств заданного множества. Например:
?- подмножество( [а, b, с], S ).
S = [a, b, c];
S = [b, c];
S = [c];
S = [ ];
S = [a, c];
S = [a];
. . .
Посмотреть ответ
3. 9. Определите отношение
разбиениесписка( Список, Список1, Список2)
так, чтобы оно распределяло элементы списка между двумя списками Список1 и Список2 и чтобы эти списки были примерно одинаковой длины. Например:
разбиениесписка( [а, b, с, d, e], [a, с, е], [b, d]).
Посмотреть ответ
3. 10. Перепишите программу об обезьяне и бананах из главы 2 таким образом, чтобы отношение
можетзавладеть( Состояние, Действия)
давало не только положительный или отрицательный ответ, но и порождало последовательность действий обезьяны, приводящую ее к успеху. Пусть Действия будет такой последовательностью, представленной в виде списка ходов:
Действия = [ перейти( дверь, окно),
передвинуть( окно, середина),
залезть, схватить ]
Посмотреть ответ
3. 11. Определите отношение
линеаризация( Список, ЛинейныйСписок)
где Список может быть списком списков, а ЛинейныйСписок - это тот же список, но "выровненный" таким образом, что элементы его подсписков составляют один линейный список. Например:
? - линеаризация( [а, d, [с, d], [ ], [[[е]]], f, L).
L = [a, b, c, d, e, f]
Посмотреть ответ
Упражнения
3. 12. Если принять такие определения
:- ор( 300, xfy, играет_в).
:- ор( 200, xfy, и).
то два следующих терма представляют собой синтаксически правильные объекты:
Tepмl = джимми играет_в футбол и сквош
Терм1 = сьюзан играет_в теннис и баскетбол и волейбол
Как эти термы интерпретируются пролог-системой? Каковы их главные функторы и какова их структура?
Посмотреть ответ
3. 13. Предложите подходящее определение операторов ("работает", "в", "нашем"), чтобы можно было писать предложения типа:
диана работает секретарем в нашем отделе.
а затем спрашивать:
?- Кто работает секретарем в нашем отделе.
Кто = диана
?- диана работает Кем.
Кем = секретарем в нашем отдела
Посмотреть ответ
3. 14. Рассмотрим программу:
t( 0+1, 1+0).
t( X+0+1, X+1+0).
t( X+1+1, Z) :-
t( X+1, X1),
t( X1+1, Z).
Как данная программа будет отвечать на ниже перечисленные вопросы, если '+' "- это (как обычно) инфиксный оператор типа yfx?
(a) ?- t( 0+1, А).
(b) ?- t( 0+1+1, В).
(с) ?- t( 1+0+1+1+1, С).
(d) ?- t( D, 1+1+1+0).
Посмотреть ответ
3. 15. В предыдущем разделе отношения между списка ми мы записывали так:
принадлежит( Элемент, Список),
конк( Список1, Список2, Список3),
удалить( Элемент, Список, НовыйСписок), . . .
Предположим, что более предпочтительной для нас является следующая форма записи:
Элемент входит_в Список,
конкатенация_списков Список1 и Список2
дает Список3,
удаление_элемента Элемент из_списка Список
дает НовыйСписок, ...
Определите операторы "входит_в", "конкатенация_списков", "и" и т.д. таким образом, чтобы обеспечить эту возможность. Переопределите также и соответствующие процедуры.
Посмотреть ответ
Упражнения
3. 16. Определите отношение
mах( X, Y, Мах)
так, чтобы Мах равнялось наибольшому из двух чисел Х и Y.
Посмотреть ответ
3. 17. Определите предикат
максспис( Список, Мах)
так, чтобы Мах равнялось наибольшему из чисел, входящих в Список.
Посмотреть ответ
3. 18. Определите предикат
сумспис( Список, Сумма)
так, чтобы Сумма равнялось сумме чисел, входящих в Список.
Посмотреть ответ
3. 19. Определите предикат
упорядоченный( Список)
который принимает значение истина, если Список
представляет собой упорядоченный список чисел. Например: упорядоченный [1, 5, 6, 6, 9, 12] ).
Посмотреть ответ
3. 20. Определите предикат
подсумма( Множ, Сумма, ПодМнож)
где Множ это список чисел, Подмнож
подмножество этих чисел, а сумма чисел из ПодМнож
равна Сумма. Например:
?- подсумма( [1, 2. 5. 3. 2], 5, ПМ).
ПМ = [1, 2, 2];
ПМ = [2, 3];
ПМ = [5];
. . .
Посмотреть ответ
3. 21. Определите процедуру
между( Nl, N2, X)
которая, с помощью перебора, порождает все целые числа X, отвечающие условию Nl <=X <=N2.
Посмотреть ответ
3. 22. Определите операторы 'если', 'то', 'иначе' и ':=" таким образом, чтобы следующее выражение стало правильным термом:
если Х > Y то Z := Х иначе Z := Y
Выберите приоритеты так, чтобы 'если' стал главным функтором. Затем определите отношение 'если' так, чтобы оно стало как бы маленьким интерпретатором выражений типа 'если-то-иначе'. Например, такого
если Вел1 > Вел2 то Перем := Вел3
иначе Перем := Вел4
где Вел1, Вел2, Вел3 и Вел4
- числовые величины (или переменные, конкретизированные числами), а Перем - переменная. Смысл отношения 'если' таков: если значение Вел1 больше значения Вел2, тогда Перем конкретизируется значением Вел3, в противном случае - значением Вел4. Приведем пример использования такого интерпретатора:
?- Х = 2, Y = 3,
Вел2 is 2*X,
Вел4 is 4*X,
Если Y>Вел2 то Z:=Y иначе Z:=Вел4.
Если Z > 5 то W := 1 иначе W :=0.
Х = 2
Y = 3
Z = 8
W = 1
Вел2 = 4
Вел4 = 8
Посмотреть ответ
Получение структурированной информации из базы данных
4. 1. Получение структурированной информации из базы данных
Это упражнение развивает навыки представления структурных объектов данных и управления ими. Оно показывает также, что Пролог является естественным языком запросов к базе данных.
База данных может быть представлена на Прологе в виде множества фактов. Например, в базе данных о семьях каждая семья может описываться одним предложением. На Рисунок 4.1 показано, как информацию о каждой семье можно представить в виде структуры. Каждая семья состоит из трех компонент: мужа, жены и детей. Поскольку количество детей в разных семьях может быть разным, то их целесообразно представить в виде списка, состоящего из произвольного числа элементов. Каждого члена семьи в свою очередь можно представить структурой, состоящей из
Абстракция данных
4. 2. Абстракция данных
Абстракцию данных можно рассматривать как процесс организации различных фрагментов информации в единые логические единицы (возможно, иерархически), придавая ей при этом некоторую концептуально осмысленную форму. Каждая информационная единица должна быть легко доступна в программе. В идеальном случае все детали реализации такой структуры должны быть невидимы пользователю этой структуры. Самое главное в этом процессе - дать программисту возможность использовать информацию, не думая о деталях ее действительного представления.
Обсудим один из способов реализации этого принципа на Прологе. Рассмотрим снова пример с семьей из предыдущего раздела. Каждая семья - это набор некоторых фрагментов информации. Все эти фрагменты объединены в естественные информационные единицы, такие, как "член семьи" или "семья", и с ними можно обращаться как с едиными объектами. Предположим опять, что информация о семье структурирована так же, как на Рисунок 4.1. Определим теперь некоторые отношения, с помощью которых пользователь может получать доступ к конкретным компонентам семьи, не зная деталей Рисунок 4.1. Такие отношения можно назвать селекторами, поскольку они позволяют выбирать конкретные компоненты. Имя такого отношения-селектора будет совпадать с именем компоненты, которую нужно выбрать. Отношение будет иметь два аргумента: первый - объект, который содержит компоненту, и второй - саму компоненту:
отношение_селектор(Объект, Выбранная_компонента)
Вот несколько селекторов для структуры семья:
муж( семья( Муж, _, _ ), Муж).
жена( семья( _, Жена, _ ), Жена).
дети( семья( _, _, СписокДетей ), СписокДетей).
Можно также создать селекторы для отдельных детей семьи:
первыйребенок( Семья, Первый) :-
дети( Семья, [Первый | _ ]).
второйребенок( Семья, Второй) :-
дети( Семья, [ _, Второй | _ ]).
. . .
Можно обобщить этот селектор для выбора N-го ребенка:
nребенок( N, Семья, Ребенок) :-
дети( Семья, СписокДетей),
n_элемент( N, СписокДетей, Ребенок)
% N-й элемент списка
Другим интересным объектом является "член семьи". Вот некоторые связанные с ним селекторы, соответствующие Рисунок 4.1:
имя( членсемьи( Имя, _, _, _ ), Имя).
фамилия( членсемьи( _, Фамилия, _, _ ), Фамилия).
датарождения( членсемьи( _, _, Дата), Дата).
Какие преимущества мы можем получить от использования отношений-селекторов? Определив их, мы можем теперь забыть о конкретном виде структуры представления информации. Для пополнения и обработки этой информации нужно знать только имена отношений-селекторов и в оставшейся части программы пользоваться только ими. В случае, если информация представлена сложной структурой, это легче, чем каждый раз обращаться к ней в явном виде. В частности, в нашем примере с семьей пользователь не обязан знать, что дети представлены в виде списка. Например, предположим, мы хотим сказать, что Том Фокс и Джим Фокс принадлежат к одной семье и что Джим - второй ребенок Тома. Используя приведенные выше отношения-селекторы, мы можем определить двух человек, назовем их Человек1 и Человек2, и семью. Следующий список целей приводит к желаемому результату:
имя( Человек1, том), фамилия( Человек1, фокс),
% Человек1 - Том Фокс
имя( Человек2, джим), фамилия( Человек1, фокс),
% Человек2 - Джим Фокс
муж( Семья, Человек1),
второйребенок( Семья, Человек2)
Использование отношений-селекторов облегчает также и последующую модификацию программ. Представьте себе, что мы захотели повысить эффективность программы, изменив представление информации. Все, что нужно сделать для этого, - изменить определения отношений-селекторов, и вся остальная программа без изменений будет работать с этим новым представлением.
Моделирование недетерминированного автомата
4. 3. Моделирование недетерминированного автомата
Данное упражнение показывает, как абстрактную математическую конструкцию можно представить на Прологе. Кроме того, программа, которая получится, окажется значительно более гибкой, чем предполагалось вначале.
Недетерминированный конечный автомат - это абстрактная машина, которая читает символы из входной цепочки и решает, допустить или отвергнуть эту цепочку. Автомат имеет несколько состояний и всегда находится в одном из них. Он может изменить состояние, перейдя из одного состояния в другое. Внутреннюю структуру такого автомата можно представить графом переходов, как показано на Рисунок 4.3. В этом примере S1, S2, S3 и S4 - состояния автомата. Стартовав из начального состояния (в нашем примере это S1 ), автомат переходит из состояния в состояние по мере чтения входной цепочки. Переход зависит от текущего входного символа, как указывают метки на дугах графа переходов.
Планирование поездки
4. 4. Планирование поездки
В данном разделе мы создадим программу, которая дает советы по планированию воздушного путешествия. Эта программа будет довольно примитивным советчиком, тем не менее она сможет отвечать на некоторые полезные вопросы, такие как: По каким дням недели есть прямые рейсы из Лондона в Любляну? Как в четверг можно добраться из Любляны в Эдинбург? Мне нужно посетить Милан, Любляну и Цюрих; вылетать нужно из Лондона во вторник и вернуться обратно в Лондон в пятницу. В какой последовательности мне следует посещать эти города, чтобы ни разу на протяжении поездки не пришлось совершать более одного перелета в день.
Центральной частью программы будет база данных, содержащая информацию о рейсах. Эта информация будет представлена в виде трехаргументного отношения:
расписание( Пункт1, Пункт2, Список_рейсов)
где Список_рейсов - это список, состоящий из структурированных объектов вида:
Время_отправления / Время_прибытия / Номер_рейса
/ Список_дней_вылета
Список_дней_вылета - это либо список дней недели, либо атом "ежедневно". Одно из предложений, входящих в расписание могло бы быть, например, таким:
расписание( лондон, эдинбург,
[ 9:40 / 10:50 / bа4733/ ежедневно,
19:40 / 20:50 / bа4833 / [пн, вт, ср, чт, пт, сб]] ).
Время представлено в виде структурированных объектов, состоящих из двух компонент - часов и минут, объединенных оператором ":".
Главная задача состоит в отыскании точных маршрутов между двумя заданными городами в определенные дни недели. Ее решение мы будем программировать в виде четырехаргументного отношения:
маршрут( Пункт1, Пункт2, День, Маршрут)
Здесь Маршрут - это последовательность перелетов, удовлетворяющих следующим критериям:
(1) начальная точка маршрута находится в Пункт1;
(2) конечная точка - в Пункт2;
(3) все перелеты совершаются в один и тот же день недели - День;
(4) все перелеты, входящие в Маршрут, содержатся в определении отношения расписание;
(5) остается достаточно времени для пересадки с рейса на рейс.
Маршрут представляется в виде списка структурированных объектов вида
Откуда - Куда : Номер_рейса : Время_отправления
Мы еще будем пользоваться следующими вспомогательными предикатами:
(1) рейс( Пункт1, Пункт2, День, N_рейса, Вр_отпр, Вр_приб)
Здесь сказано, что существует рейс N_рейса между Пункт1 и Пункт2 в день недели День с указанными временами отправления и прибытия.
(2) вр_отпр( Маршрут, Время)
Время - это время отправления по маршруту Маршрут.
(3) пересадка( Время1, Время2)
Между Время1 и Время2 должен существовать промежуток не менее 40 минут для пересадки с одного рейса на другой.
Задача нахождения маршрута напоминает моделирование недетерминированного автомата из предыдущего раздела: Состояния автомата соответствуют городам. Переход из состояния в состояние соответствует перелету из одного города в другой. Отношение переход автомата соответствует отношению расписание. Модель автомата находит путь в графе переходов между исходным и конечным состояниями; планировщик поездки находит маршрут между начальным н конечным пунктами поездки.
Неудивительно поэтому, что отношение маршрут можно определить аналогично отношению допускает, с той разницей, что теперь нет "спонтанных переходов". Существуют два случая:
(1) Прямой рейс: если существует прямой рейс между пунктами Пункт1 и Пункт2, то весь маршрут состоит только из одного перелета:
маршрут( Пункт1, Пункт2, День, [Пункт1-Пункт2 : Nр : Отпр]):-
рейс( Пункт1, Пункт2, День, Np, Отпр, Приб).
(2) Маршрут с пересадками: маршрут между пунктами Р1 и Р2 состоит из первого перелета из P1 в некоторый промежуточный пункт Р3 и маршрута между Р3 и Р2. Кроме того, между окончанием первого перелета и отправлением во второй необходимо оставить достаточно времени для пересадки.
маршрут( Р1, Р2, День, [Р1-Р3 : Nр1 : Отпр1 | Маршрут]) :-
маршрут( Р3, Р2, День, Маршрут ),
рейс( Р1, Р3, День, Npl, Oтпpl, Приб1),
вр_отпр( Маршрут, Отпр2),
пересадка( Приб1, Отпр2).
Вспомогательные отношения рейс, пересадка и вр_отпр запрограммировать легко; мы включили их в полный текст программы планировщика поездки на Рисунок 4.5. Там же приводится и пример базы данных расписания.
Наш планировщик исключительно прост и может рассматривать пути, очевидно ведущие в никуда. Тем не менее его оказывается вполне достаточно, если база данных о рейсах самолетов невелика. Для больших баз данных потребовалось бы разработать более интеллектуальный планировщик, который мог бы справиться с большим количеством путей, участвующих в перебора при нахождении нужного пути.
Вот некоторые примеры вопросов к планировщику:
По каким дням недели существуют прямые рейсы из Лондона в Люблину?
?- рейс( лондон, любляна, День, _, _, _ ).
День = пт;
День = сб;
no
(нет)
line();
% ПЛАНИРОВЩИК ВОЗДУШНЫХ МАРШРУТОВ
:- ор( 50, xfy, :).
рейс( Пункт1, Пункт2, День, Np, ВрОтпр, ВрПриб) :-
расписание( Пункт1, Пункт2, СписРейсов),
принадлежит( ВрОтпр / ВрПриб / Nр / СписДней, СписРейсов),
день_выл( День, СписДней).
принадлежит( X, [X | L] ).
принадлежит( X, [Y | L] ) :-
принадлежит( X, L ).
день_выл( День, СписДней) :-
принадлежит( День, СписДней).
день_выл( День, ежедневно) :-
принадлежит( День, [пн, вт, ср, чт, пт, сб, вс] ).
маршрут( P1, P2, День, [Р1-Р2 : Np : ВрОтпр] ) :-
% прямой рейс
рейс( P1, P2, День, Np, ВрОтпр, _ ).
маршрут( Р1, Р2, День, [Pl-P3 : Np1 : Oтпp1 | Маршрут]) :-
% маршрут с пересадками
маршрут( Р3, P2, День, Маршрут ),
рейс( Р1, Р3, День, Npl, Oтпp1, Приб1),
вр_отпр( Маршрут, Отпр2),
пересадка( Приб1, Отпр2).
вр_отпр( [Р1-Р2 : Np : Отпр | _ ], Отпр).
пересадка( Часы1 : Минуты1, Часы2 : Минуты2) :-
60 * (Часы2-Часы1) + Минуты2 - Минуты1 >= 40
% БАЗА ДАННЫХ О РЕЙСАХ САМОЛЕТОВ
расписание( эдинбург, лондон,
[ 9:40 / 10:50 / bа4733 / ежедневно,
13:40 / 14:50 / ba4773 / ежедневно,
19:40 / 20:50 / bа4833 / [пн, вт, ср, чт, пт, вс] ] ).
расписание( лондон, эдинбург,
[ 9:40 / 10:50 / bа4732 / ежедневно,
11:40 / 12:50 / bа4752 / ежедневно,
18:40 / 19:50 / bа4822 / [пн, вт, ср, чт, пт] ] ),
расписание( лондон, любляна,
[13:20 / 16:20 / ju201 / [пт],
13:20 / 16:20 / ju213 / [вс] ] ).
расписание( лондон, цюрих,
[ 9:10 / 11:45 / bа614 / ежедневно,
14:45 / 17:20 / sr805 / ежедневно ] ).
расписание( лондон, милан,
[ 8:30 / 11:20 / bа510 / ежедневно,
11:00 / 13:50 / az459 / ежедневно ] ).
расписание( любляна, цюрих,
[11:30 / 12:40 / ju322 / [вт,чт] ] ).
расписание( любляна, лондон,
[11:10 / 12:20 / yu200 / [пт],
11:25 / 12:20 / yu212 / [вс] ] ).
расписание( милан, лондон,
[ 9:10 / 10:00 / az458 / ежедневно,
12:20 / 13:10 / bа511 / ежедневно ] ).
расписание( милан, цюрих,
[ 9:25 / 10:15 / sr621 / ежедневно,
12:45 / 13:35 / sr623 / ежедневно ] ).
расписание( цюрих, любляна,
[13:30 / 14:40 / yu323 / [вт, чт] ] ).
расписание( цюрих, лондон,
9:00 / 9:40 / bа613 /
[ пн, вт, ср, чт, пт, сб],
16:10 / 16:55 / sr806 / [пн, вт, ср, чт, пт, сб] ] ).
расписание( цюрих, милан,
[ 7:55 / 8:45 / sr620 / ежедневно ] ).
представлением доски каждое решение
4. 5. 2. Программа 2
В соответствии с принятым в программе 1 представлением доски каждое решение имело вид
[1/Y1, 2/Y2, 3/Y3, ..., 8/Y8]
так как ферзи расставлялись попросту в последовательных вертикалях. Никакая информация не была бы потеряна, если бы Х-координаты были пропущены. Поэтому можно применить более экономное представление позиции на доске, оставив в нем только Y-координаты ферзей:
[Y1, Y2, Y3, ..., Y8]
Чтобы не было нападений по горизонтали, никакие два ферзя не должны занимать одну и ту же горизонталь. Это требование накладывает ограничение на Y-координаты: ферзи должны занимать все горизонтали с 1-й по 8-ю. Остается только выбрать порядок следования этих восьми номеров. Каждое решение представляет собой поэтому одну из перестановок списка:
[1, 2, 3, 4, 5, 6, 7, 8]
Такая перестановка S является решением, если каждый ферзь в ней не находится под боем (список S - "безопасный"). Поэтому мы можем написать:
решение( S) :-
перестановка( [1, 2, 3, 4, 5, 6, 7, 8], S),
безопасный( S).
4. 5. 3. Программа 3
Наша третья программа для задачи о восьми ферзях опирается на следующие соображения. Каждый ферзь должен быть размещен на некотором поле, т. е. на некоторой вертикали, некоторой горизонтали, а также на пересечении каких-нибудь двух диагоналей. Для того, чтобы была обеспечена безопасность каждого ферзя, все они должны располагаться в разных вертикалях, разных горизонталях и в разных диагоналях (как идущих сверху вниз, так и идущих снизу вверх). Естественно поэтому рассмотреть более богатую систему представления с четырьмя координатами:
x вертикали
у горизонтали
u диагонали, идущие снизу вверх
v диагонали, идущие сверху вниз
Эти координаты не являются независимыми: при заданных х и у, u и v определяются однозначно (пример на Рисунок 4.10). Например,
u = х - у
v = х + у
Программирование на языке Пролог для искусственного интеллекта
4. 5. 3. Программа 3
Наша третья программа для задачи о восьми ферзях опирается на следующие соображения. Каждый ферзь должен быть размещен на некотором поле, т. е. на некоторой вертикали, некоторой горизонтали, а также на пересечении каких-нибудь двух диагоналей. Для того, чтобы была обеспечена безопасность каждого ферзя, все они должны располагаться в разных вертикалях, разных горизонталях и в разных диагоналях (как идущих сверху вниз, так и идущих снизу вверх). Естественно поэтому рассмотреть более богатую систему представления с четырьмя координатами:
x вертикали
у горизонтали
u диагонали, идущие снизу вверх
v диагонали, идущие сверху вниз
Эти координаты не являются независимыми: при заданных х и у, u и v определяются однозначно (пример на Рисунок 4.10). Например,
u = х - у
v = х + у
Заключительные замечания
4. 5. 4. Заключительные замечания
Три решения задачи о восьми ферзях показывают, как к одной и той же задаче можно применять различные подходы. Мы варьировали также и представление данных. В одних случаях это представление было более экономным, в других - более наглядным и, до некоторой степени, избыточным. К недостаткам более экономного представления можно отнести то, что какая-то информация всякий раз, когда она требовалась, должна была перевычисляться.
В некоторых случаях основным шагом к решению было обобщение задачи. Как ни парадоксально, но при рассмотрении более общей задачи решение оказывалось проще сформулировать. Принцип такого обобщения - стандартный прием программирования, и его можно часто применять.
Из всех трех программ третья лучше всего показывает, как подходить к общей задаче построения структуры из заданного множества элементов при наличии ограничений.
Возникает естественный вопрос: " Какая из трех программ наиболее эффективна?" В этом отношение программа 2 значительно хуже двух других, а эти последние - одинаковы. Причина в том, что основанная на перестановках программа 2 строит все перестановки, тогда как две другие программы способны отбросить плохую перестановку не дожидаясь, пока она будет полностью построена. Программа 3 наиболее эффективна. Она избегает некоторых арифметических вычислений, результаты которых уже сразу заложены в избыточное представление доски, используемое этой программой.
Задача о восьми ферзях
4. 5. Задача о восьми ферзях
Эта задача состоит в отыскании такой расстановки восьми ферзей на пустой шахматной доске, в которой ни один из ферзей не находится под боем другого. Решение мы запрограммируем в виде унарного отношения:
решение( Поз)
которое истинно тогда и только тогда, когда Поз изображает позицию, в которой восемь ферзей не бьют друг друга. Будет интересно сравнить различные идеи, лежащие в основе программирования этой задачи. Поэтому мы приведем три программы, основанные на слегка различающихся ее представлениях.
4. 5. 1. Программа 1
Вначале нужно выбрать способ представления позиции на доске. Один из наиболее естественных способов - представить позицию в виде списка из восьми элементов, каждый из которых соответствует одному из ферзей. Каждый такой элемент будет описывать то поле доски, на которой стоит соответствующий ферзь. Далее, каждое поле доски можно описать с помощью пары координат ( Х и Y), где каждая координата - целое число от 1 до 8. В программе мы будем записывать такую пару в виде
Х / Y
где оператор "/" обозначает, конечно, не деление, а служит лишь для объединения координат поля в один элемент списка. На Рисунок 4.6 показано одно из решений задачи о восьми ферзях и его запись в виде списка.
После того. как мы выбрали такое представление, задача свелась к нахождению списка вида:
[Xl/Yl, X2/Y2, X3/Y3, X4/Y4, X5/Y5, X6/Y6, X7/Y7, X8/Y8]
удовлетворяющего требованию отсутствия нападений. Наша процедура решение должна будет найти подходящую конкретизацию переменных X1, Y1, Х2, Y2, ..., Х8, Y8. Поскольку мы знаем, что все ферзи должны находиться на разных вертикалях во избежание нападений по вертикальным линиям, мы можем сразу же ограничить перебор, чтобы облегчать поиск решения. Можно поэтому сразу зафиксировать Х-координаты так, чтобы список, изображающий решение, удовлетворял следующему, более конкретному шаблону:
[1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]
в данном разделе, иллюстрируют некоторые
Резюме
Примеры, рассмотренные в данном разделе, иллюстрируют некоторые достоинства и характерные черты программирования на Прологе: Базу данных можно естественным образом представить в виде множества прологовских фактов. Такие механизмы Пролога, как вопросы и сопоставление, можно гибко использовать для получения информации из базы данных. Кроме этого можно использовать вспомогательные процедуры-утилиты, еще больше облегчающие взаимодействие с конкретной базой данных. Абстракцию данных можно рассматривать как метод программирования, который облегчает работу со сложными структурами данных и вносит большую ясность и наглядность в программы. В Прологе легко соблюдать основные принципы абстракции данных. Часто легко можно осуществить перевод абстрактных математических конструкций, таких как автоматы, на язык определений Пролога, готовых к выполнению. Как это было в случае восьми ферзей, многие задачи допускают различные подходы, связанные с разными представлениями этих задач. Часто внесение избыточности в представление экономит вычисления. Происходит как бы проигрыш в рабочем пространстве, но выигрыш во времени. Часто основным шагом на пути к решению оказывается обобщение задачи. Парадоксально, но рассмотрение более общей задачи позволяет облегчить формулировку решения.
Структурированная информация о семье
Рисунок 4. 1. Структурированная информация о семье.

четырех компонент: имени, фамилии, даты рождения и работы. Информация о работе - это либо "не работает", либо указание места работа и оклада (дохода). Информацию о семье, изображенной на Рисунок 4.1, можно занести в базу данных с помощью предложения:
семья( членсемьи( том, фокс, дата( 7, май, 1950),
работает( bbс, 15200) ),
членсемьи( энн, фокс, дата( 9, май, 1951), неработает),
[членсемьи( пат, фокс, дата( 5, май, 1973), неработает),
членсемьи( джим, фокс, дата( 5, май, 1973), неработает) ] ).
Тогда база данных будет состоять из последовательности фактов, подобных этому, и описывать все семьи, представляющие интерес для нашей программы.
В действительности Пролог очень удобен для извлечения необходимой информации из такой базы данных. Здесь хорошо то, что можно ссылаться на объекты, не указывая в деталях всех их компонент. Можно задавать только структуру интересующих нас объектов и оставлять конкретные компоненты без точного описания или лишь с частичным описанием. На Рисунок 4.2 приведено несколько примеров. Так, а запросах к базе данных можно ссылаться на всех Армстронгов с помощью терма
семья( членсемьи( _, армстронг, _, _ ), _, _ )
Символы подчеркивания обозначают различные анонимные переменные, значения которых нас не заботят. Далее можно сослаться на все семьи с тремя детьми при помощи терма:
семья( _, _, [ _, _, _ ])
Чтобы найти всех замужних женщин, имеющих по крайней мере троих детей, можно задать вопрос:
?- семья( _, членсемьи( Имя, Фамилия, _, _ ), [ _, _, _ | _ ]).
Главным моментом в этих примерах является то, что указывать интересующие нас объекты можно не только по их содержимому, но и по их структуре. Мы задаем одну структуру и оставляем ее аргументы в виде слотов (пропусков).
Описания объектов
Рисунок 4. 2. Описания объектов по их структурным свойствам: (а) любая семья Армстронгов; (b) любая семья, имеющая ровно трех детей; (с) любая семья, имеющая по крайней мере три ребенка. Структура (с) дает возможность получить имя и фамилию жены конкретизацией переменных Имя и Фамилия.

Можно создать набор процедур, который служил бы утилитой, делающей взаимодействие с нашей базой данных более удобным. Такие процедуры являлись бы частью пользовательского интерфейса. Вот некоторые полезные процедуры для нашей базы данных:
муж( X) :-
% X - муж
семья( X, _, _ ).
жена( X) :-
% X - жена
семья( _, X, _ ).
ребенок( X) :-
% X - ребенок
семья( _, _, Дети),
принадлежит( X, Дети).
принадлежит( X, [X | L ]).
принадлежит( X, [Y | L ]) :-
принадлежит( X, L).
существует( Членсемьи) :-
% Любой член семьи в базе данных
муж( Членсемьи);
жена( Членсемьи);
ребенок( Членсемьи).
дата рождения( Членсемьи( _, _, Дата, _ ), Дата).
доход( Членсемьи( _, _, _, работает( _, S) ), S).
% Доход работающего
доход( Членсемьи( _, _, _, неработает), 0).
% Доход неработающего
Этими процедурами можно воспользоваться, например, в следующих запросах к базе данных:
Найти имена всех людей из базы данных:
?- существует( членсемьи( Имя,Фамилия, _, _ )).
Найти всех детей, родившихся в 1981 году:
?- ребенок( X), датарождения( X, дата( _, _, 1981) ).
Найти всех работающих жен:
?- жена( членсемьи( Имя, Фамилия, _, работает( _, _ ))).
Найти имена и фамилии людей, которые не работают и родились до 1963 года:
?- существует членсемьи( Имя, Фамилия, дата( _, _, Год), неработает) ),
Год < 1963.
Найти людей, родившихся до 1950 года, чей доход меньше, чем 8000:
?- существует( Членсемьи),
датарождения( Членсемьи, дата( _, _, Год) ),
Год < 1950,
доход( Членсемьи, Доход),
Доход < 8000.
Найти фамилии людей, имеющих по крайней мере трех детей:
?- семья( членсемьи( _, Фамилия, _, _ ), _, [ _, _, _ | _ ]).
Для подсчета общего дохода семья полезно определить сумму доходов людей из некоторого списка в виде двухаргументного отношения:
общий( Список_Людей, Сумма_их_доходов)
Это отношение можно запрограммировать так:
общий( [ ], 0). % Пустой список людей
общий( [ Человек | Список], Сумма) :-
доход( Человек, S),
% S - доход первого человека
общий( Список, Остальные),
% Остальные - сумма доходов остальных
Сумма is S + Остальные.
Теперь общие доходы всех семей могут быть найдены с помощью вопроса:
?- семья( Муж, Жена, Дети),
общий( [Муж, Жена | Дети], Доход).
Пусть отношение длина подсчитывает количество элементов списка, как это было определено в разд. 3.4. Тогда мы можем найти все семьи, которые имеют доход на члена семьи, меньший, чем 2000, при помощи вопроса:
?- семья( Муж, Жена, Дети),
общий( [ Муж, Жена | Дети], Доход),
длина( [ Муж, Жена | Дети], N),
Доход/N < 2000.
Пример недетерминированного конечного автомата
Рисунок 4. 3. Пример недетерминированного конечного автомата.

Переход выполняется всякий раз при чтении входного символа. Заметим, что переходы могут быть недетерминированными. На Рисунок 4.3 видно, что если автомат находится в состоянии S1, и текущий входной символ равен а, то переход может осуществиться как в S1, так и в S2. Некоторые дуги помечены меткой пусто, обозначающей "пустой символ". Эти дуги соответствуют "спонтанным переходам" автомата. Такой переход называется спонтанным, потому что он выполняется без чтения входной цепочки. Наблюдатель, рассматривающий автомат как черный ящик, не сможет обнаружить, что произошел какой-либо переход.
Состояние S3 обведено двойной линией, это означает, что S3 - конечное состояние. Про автомат говорят, что он допускает входную цепочку, если в графе переходов существует путь, такой, что:
(1) он начинается в начальном состоянии,
(2) он оканчивается в конечном состоянии, и
(3) метки дуг, образующих этот путь, соответствуют полной входной цепочке.
Решать, какой из возможных переходов делать в каждый момент времени - исключительно внутреннее дело автомата. В частности, автомат сам решает, делать ли спонтанный переход, если он возможен в
Допущение цепочки
Рисунок 4. 4. Допущение цепочки: (a) при чтении первого символа X;
(b) при совершении спонтанного перехода.

текущем состоянии. Однако абстрактные недетерминированные машины такого типа обладают волшебным свойством: если существует выбор, они всегда избирают "правильный" переход, т.е. переход, ведущий к допущению входной цепочки при наличии такого перехода. Автомат на Рисунок 4.3, например, допускает цепочки аb и aabaab, но отвергает цепочки abb и abba. Легко видеть, что этот автомат допускает любые цепочки, оканчивающиеся на аb и отвергает все остальные.
Некоторый автомат можно описать на Прологе при помощи трех отношений:
(1) Унарного отношения конечное, которое определяет конечное состояние автомата.
(2) Трехаргументного отношения переход, которое определяет переход из состояния в состояние, при этом
переход( S1, X, S2)
означает переход из состояния S1 в S2, если считан входной символ X.
(3) Бинарного отношения
спонтанный( S1, S2)
означающего, что возможен спонтанный переход из S1 в S2.
Для автомата, изображенного на Рисунок 4.3, эти отношения будут такими:
конечное( S3).
переход( S1, а, S1).
переход( S1, а, S2).
переход( S1, b, S1).
переход( S2, b, S3).
переход( S3, b, S4).
спонтанный( S2, S4).
спонтанный( S3, S1).
Представим входные цепочки в виде списков Пролога. Цепочка ааb будет представлена как [а, а, b]. Модель автомата, получив его описание, будет обрабатывать заданную входную цепочку, и решать, допускать ее или нет. По определению, недетерминированный автомат допускает заданную цепочку, если (начав из начального состояния) после ее прочтения он способен оказаться в конечном состоянии. Модель программируется в виде бинарного отношения допускается, которое определяет принятие цепочки из данного состояния. Так
допускается( Состояние, Цепочка)
истинно, если автомат, начав из состояния Состояние как из начального, допускает цепочку Цепочка. Отношение допускается можно определить при помощи трех предложений. Они соответствуют следующим трем случаям:
(1) Пустая цепочка [ ] допускается из состояния S, если S - конечное состояние.
(2) Непустая цепочка допускается из состояния S, если после чтения первого ее символа автомат может перейти в состояние S1, и оставшаяся часть цепочки допускается из S1. Этот случай иллюстрируется на Рисунок 4.4(а).
(3) Цепочка допускается из состояния S, если автомат может сделать спонтанный переход из S в S1, а затем допустить (всю) входную цепочку из S1. Такой случай иллюстрируется на Рисунок 4.4(b).
Эти правила можно перевести на Пролог следующим образом:
допускается( S, [ ]) :-
% Допуск пустой цепочки
конечное( S).
допускается( S, [X | Остальные]) :-
% Допуск чтением первого символа
переход( S, X, S1),
допускается( S1, Остальные).
допускается( S, Цепочка) :-
% Допуск выполнением спонтанного перехода
спонтанный( S, S1),
допускается( S1, Цепочка).
Спросить о том, допускается ли цепочка аааb, можно так:
?- допускается( S1, [a, a, a, b]).
yes (да)
Как мы уже видели, программы на Прологе часто оказываются способными решать более общие задачи, чем те, для которых они первоначально предназначались. В нашем случае мы можем спросить модель также о том, в каком состоянии должен находиться автомат в начале работы, чтобы он допустил цепочку аb:
?- допускается( S, [a, b]).
S = s1;
S = s3
Как ни странно, мы можем спросить также "Каковы все цепочки длины 3, допустимые из состояния s1?"
?- допускается( s1, [XI, Х2, X3]).
X1 = а
Х2 = а
Х3 = b;
X1 = b
Х2 = а
Х3 = b;
nо (нет)
Если мы предпочитаем, чтобы допустимые цепочки выдавались в виде списков, тогда наш вопрос следует сформулировать так:
?- Цепочка = [ _, _, _ ], допускается( s1, Цепочка).
Цепочка = [а, а, b];
Цепочка = [b, а, b];
nо (нет)
Можно проделать и еще некоторые эксперименты, например спросить: "Из какого состояния автомат допустит цепочку длиной 7?"
Эксперименты могут включать в себя переделки структуры автомата, вносящие изменения в отношения конечное, переход и спонтанный. В автомате, изображенном на Рисунок 4.3, отсутствуют циклические "спонтанные пути" (пути, состоящие только из спонтанных переходов). Если на Рисунок 4.3 добавить новый переход
спонтанный( s1, s3)
то получится "спонтанный цикл". Теперь наша модель может столкнуться с неприятностями. Например, вопрос
?- допускается( s1, [а]).
приведет к тому, что модель будет бесконечно переходить в состояние s1, все время надеясь отыскать какой-либо путь в конечное состояние.
Планировщик воздушных маршрутов и база данных о рейсах самолетов
Рисунок 4. 5. Планировщик воздушных маршрутов и база данных о рейсах самолетов.
Как мне добраться из Любляны в Эдинбург в четверг?
?- маршрут( любляна, эдинбург, чт, R).
R = [любляна-цюрих : уu322 : 11:30, цюрих-лондон:
sr806 : 16:10,
лондон-эдинбург : bа4822 : 18:40 ]
Как мне посетить Милан, Любляну и Цюрих, вылетев из Лондона во вторник и вернувшись в него в пятницу, совершая в день не более одного перелета? Этот вопрос сложнее, чем предыдущие. Его можно сформулировать, использовав отношение перестановка, запрограммированное в гл. 3. Мы попросим найти такую перестановку городов Милан, Любляна и Цюрих, чтобы соответствующие перелеты можно было осуществить в несколько последовательных дней недели:
?- перестановка( [милан, любляна, цюрих],
[Город1, Город2, Город3] ),
рейс( лондон, Город1, вт, Np1, Oтпp1, Пpиб1),
peйc( Город1, Город2, ср, Np2, Отпр2, Приб2),
рейс( Город2, Город3, чт, Np3, Отпp3, Приб3),
рейс( Город3, лондон, пт, Np4, Отпр4, Приб4).
Город1 = милан
Город2 = цюрих
Город3 = любляна
Npl = ba510
Отпр1 = 8:30
Приб1 = 11:20
Np2 =sr621
Отпр2 = 9:25
Приб2 = 10:15
Np3 = yu323
Отпр3 = 13:30
Приб3 = 14:40
Np4 = yu200
Отпр4 = 11:10
Приб4 = 12:20
Решение задачи о восьми
Рисунок 4. 6. Решение задачи о восьми ферзях. Эта позиция может быть
представлена в виде списка [1/4, 2/2, 3/7, 4/3, 5/6, 6/8, 7/5, 8/1].

Нас интересует решение для доске размером 8х8. Однако, как это часто бывает в программировании, ключ к решению легче найти, рассмотрев более общую постановку задачи. Как это ни парадоксально, но часто оказывается, что решение более общей задачи легче сформулировать, чем решение более частной, исходной задачи; после этого исходная задача решается просто как частный случай общей задачи.
Основная часть работы при таком подходе ложится на нахождение правильного обобщения исходной задачи. В нашем случае хорошей является идея обобщать задачу в отношении количества ферзей (количества вертикалей в списке), разрешив количеству ферзей принимать любое значение, включая нуль. Тогда отношение решение можно сформулировать, рассмотрев два случая:
Случай 1. Список ферзей пуст. Пустой список без сомнения является решением, поскольку нападений в этом случае нет.
Случай 2. Список ферзей не пуст. Тогда он выглядит так:
[ X/Y | Остальные ]
В случае 2 первый ферзь находится на поле Х / Y, а остальные - на полях, указанных в списке Остальные. Если мы хотим, чтобы это было решением, то должны выполняться следующие условия:
(1) Ферзи, перечисленные в списке Остальные, не должны бить друг друга; т. е. список Остальные сам должен быть решением.
(2) Х и Y должны быть целыми числами от 1 до 8.
(3) Ферзь, стоящий на поле X / Y, не должен бить ни одного ферзя из списка Остальные.
Чтобы запрограммировать первое условие, можно воспользоваться самим отношением решение. Второе условие можно сформулировать так: Y должен принадлежать списку целых чисел от 1 до 8. т. е. [1, 2, 3, 4, 5, 6, 7, 8]. С другой стороны, о координате Х можно не беспокоиться, поскольку список-решение должен соответствовать шаблону, у которого Х-координаты уже определены. Поэтому Х гарантированно получит правильное значение от 1 до 8. Третье условие можно обеспечить с помощью нового отношения небьет. Все это можно записать на Прологе так:
решение( [X/Y | Остальные] ) :-
решение( Остальные),
принадлежит( Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
небьет( X/Y, Остальные).
Осталось определить отношение небьет:
небьет( Ф, Фспис)
И снова его описание можно разбить на два случая:
(1) Если список Фспис пуст, то отношение, конечно, выполнено, потому что некого бить (нет ферзя, на которого можно было бы напасть).
(2) Если Фспис не пуст, то он имеет форму
[Ф1 | Фспис1]
и должны выполняться два условия:
(а) ферзь на поле Ф не должен бить ферзя на поле Ф1 и
(b) ферзь на поле Ф не должен бить ни одного ферзя из списка Фспис1.
Выразить требование, чтобы ферзь, находящийся на некотором поле, не бил другое поле, довольно просто: эти поля не должны находиться на одной и той же горизонтали, вертикали или диагонали: Наш шаблон решения гарантирует, что все ферзи находятся на разных вертикалях, поэтому остается только обеспечить, чтобы Y-координаты ферзей были различны и ферзи не находились на одной диагонали, т.е. расстояние между полями по направлению Х не должно равняться расстоянию между ними по Y.
На Рисунок 4.7 приведен полный текст программы. Чтобы облегчить ее использование, необходимо добавить список-шаблон. Это можно сделать в запросе на генерацию решений. Итак:
?- шаблон( S), решение( S).
line();решение( [ ] ).
решение( [X/Y | Остальные ] ) :-
% Первый ферзь на поле X/Y,
% остальные ферзи на полях из списка Остальные
решение( Остальные),
принадлежит Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
небьет( X/Y | Остальные).
% Первый ферзь не бьет остальных
небьет( _, [ ]). % Некого бить
небьет( X/Y, [X1/Y1 | Остальные] ) :-
Y =\= Y1,
% Разные Y-координаты
Y1-Y =\= X1-X
% Разные диагонали
Y1-Y =\= X-X1,
небьет( X/Y, Остальные).
принадлежит( X, [X | L] ).
принадлежит( X, [Y | L] ) :-
принадлежит( X, L).
% Шаблон решения
шаблон( [1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]).
line();Программа1 для задачи о восьми ферзях
Рисунок 4. 7. Программа1 для задачи о восьми ферзях.
Система будет генерировать решения в таком виде:
S = [1/4, 2/2, 3/7, 4/3, 5/6, 6/8, 7/5, 8/1];
S = [1/5, 2/2, 3/4, 4/7, 5/3, 6/8, 7/6, 8/1];
S = [1/3, 2/5, 3/2, 4/8, 5/6, 6/4, 7/7, 8/1].
. . .
а) Расстояние по
Рисунок 4. 8. (а) Расстояние по Х между Ферзь и Остальные равно 1.
(b) Расстояние по Х между Ферзь и Остальные равно 3

Отношение перестановка мы уже определила в гл. 3, а вот отношение безопасный нужно еще определить. Это определение можно разбить на два случая:
(1) S - пустой список. Тогда он, конечно, безопасный, ведь нападать не на кого.
(2) S - непустой список вида [Ферзь | Остальные]. Он безопасный, если список Остальные - безопасный и Ферзь не бьет ни одного ферзя из списка Остальные.
На Прологе это выглядит так:
безопасный( [ ]).
безопасный( [Ферзь | Остальные ] :-
безопасный( Остальные),
небьет(Ферзь | Остальные).
В этой программе отношение небьет более хитрое.
line();решение( Ферзи) :-
перестановка( [1, 2, 3, 4, 5, 6, 7, 8], Ферзи),
безопасный( Ферзи).
перестановка( [ ], [ ]).
перестановка( [Голова | Хвост], СписПер) :-
перестановка( Хвост, ХвостПер),
удалить( Голова, СписПер, ХвостПер).
% Вставка головы в переставленный хвост
удалить( А, [А | Список).
удалять( А, [В | Список], [В, Список1] ) :-
удалить( А, Список, Список1).
безопасный( [ ]).
безопасный( [Ферзь | Остальные]) :-
безопасный( Остальные),
небьет( Ферзь, Остальные, 1).
небьет( _, [ ], _ ).
небьет( Y, [Y1 | СписY], РасстХ) :-
Y1-Y =\= РасстХ,
Y-Y1 =\= РасстХ,
Расст1 is РасстХ + 1,
небьет( Y, СписY, Расст1).
Программа 2 для задачи о восьми ферзях
Рисунок 4. 9. Программа 2 для задачи о восьми ферзях.
Трудность состоит в том, что расположение ферзей определяется только их Y-координатами, а Х-координаты в представлении позиции не присутствуют в явном виде. Этой трудности можно избежать путем небольшого обобщения отношения небьет, как это показано на Рисунок 4.8. Предполагается, что цель
небьет( Ферзь, Остальные)
обеспечивает отсутствие нападении ферзя Ферзь на поля списка Остальные в случае, когда расстояние по Х между Ферзь и Остальные равно 1. Остается рассмотреть более общий случай произвольного расстояния. Для этого мы добавим его в отношение небьет в качестве третьего аргумента:
небьет( Ферзь, Остальные, РасстХ)
Соответственно и цель небьет в отношении безопасный должна быть изменена на
небьет( Ферзь, Остальные, 1)
Теперь отношение небьет может быть сформулировано в соответствии с двумя случаями, в зависимости от списка Остальные: если он пуст, то бить некого и, естественно, нет нападений; если же он не пуст, то Ферзь не должен бить первого ферзя из списка Остальные (который находится от ферзя Ферзь на расстоянии РасстХ вертикалей), а также ферзей из хвоста списка Остальные, находящихся от него на расстоянии РасстХ + 1. Эти соображения приводят к программе, изображенной на Рисунок 4.9.
Связь между вертикалями
Рисунок 4. 10. Связь между вертикалями, горизонталями и диагоналями. Помеченное
поле имеет следующие координаты: x = 2, у = 4, u = 2 - 4 = -2, v = 2 + 4 = 6.

Области изменения всех четырех координат таковы:
Dx = [1, 2, 3, 4, 5, 6, 7, 8]
Dy = [1, 2, 3, 4, 5, 6, 7, 8]
Du = [-7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7]
Dv = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
Задачу о восьми ферзях теперь можно сформулировать следующим образом: выбрать восемь четверок (X, Y, U, V), входящих в области изменения (X в Dx, Y в Dy и т.д.), так, чтобы ни один их элемент не выбирался дважды из одной области. Разумеется, выбор Х и Y определяет выбор U и V. Решение при такой постановке задачи может быть вкратце таким: при заданных 4-х областях изменения выбрать позицию для первого ферзя, вычеркнуть соответствующие элементы из 4-х областей изменения, а затем использовать оставшиеся элементы этих областей для размещения остальных ферзей. Программа, основанная на таком подходе, показана на Рисунок 4.11. Позиция на доске снова представляется списком Y-координат. Ключевым отношением в этой программе является отношение
peш( СписY, Dx, Dy, Du, Dv)
которое конкретизирует Y-координаты (в СписY) ферзей, считая, что они размещены в последовательных вертикалях, взятых из Dx. Все Y-координаты и соответствующие координаты U и V берутся из списков Dy, Du и Dv. Главную процедуру решение можно запустить вопросом
?- решение( S)
Это вызовет запуск реш с полными областями изменения координат, что соответствует пространству
line();решение( СписY) :-
реш( СписY,
% Y-координаты ферзей
[1, 2, 3, 4, 5, 6, 7, 8],
% Область изменения Y-координат
[1, 2, 3, 4, 5, 6, 7, 8],
% Область изменения Х-координат
[-7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7],
% Диагонали, идущие снизу вверх
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 14, 15, 16] ).
% Диагонали, идущие сверху вниз
реш([ ], [ ], Dy, Du, Dv).
реш( [Y | СписY], [X | Dx1], Dy, Du, Dv) :-
удалить( Y, Dy, Dy1),
% Выбор Y-координаты
U is X-Y
% Соответствующая диагональ вверх
удалить( U, Du, Du1),
% Ее удаление
V is X+Y
% Соответствующая диагональ вниз
удалить( V, Dv, Dv1),
% Ее удаление
реш( СписY, Dх1, Dy1, Du1, Dv1).
% Выбор из оставшихся значений
удалить( А, [А | Список], Список).
удалить(A, [В | Список ], [В | Список1 ] ) :-
удалить( А, Список, Список1).
Программа 3 для задачи о восьми ферзях
Рисунок 4. 11. Программа 3 для задачи о восьми ферзях.
задачи о восьми ферзях.
Процедура реш универсальна в том смысле, что ее можно использовать для решения задачи об N ферзях (на доске размером N х N). Нужно только правильно задеть области Dx, Dy и т.д.
Удобно автоматизировать получение этих областей. Для этого нам потребуется процедура
генератор( Nl, N2, Список)
которая для двух заданных целых чисел Nl и N2 порождает список
Список = [Nl, Nl + 1, Nl + 2, ..., N2 - 1, N2]
Вот она:
генератор( N, N, [N]).
генератор( Nl, N2, [Nl | Список]) :-
Nl < N2,
М is Nl + 1,
генератор( М, N2, Список).
Главную процедуру решение нужно соответствующим образом обобщить:
решение( N, S)
где N - это размер доски, а S - решение, представляемое в виде списка Y-координат N ферзей. Вот обобщенное отношение решение:
решение( N, S) :-
генератор( 1, N, Dxy),
Nu1 is 1 - N, Nu2 is N - 1,
генератор( Nu1, Nu2, Du),
Nv2 is N + N,
генератор( 2, Nv2, Dv),
реш( S, Dxy, Dxy, Du, Dv).
Например, решение задачи о 12 ферзях будет получено с помощью:
?- решение( 12, S).
S = [1, 3, 5, 8, 10, 12, 6, 11, 2, 7, 9, 4]
Завершите определение отношения nребенок, определив
Упражнение
4. 3. Завершите определение отношения nребенок, определив отношение
n_элемент( N, Список, X)
которое выполняется, если Х является N-м элементом списка Список.
Посмотреть ответ
Упражнение
4. 6. При поиске решения программа, приведенная на Рисунок 4.7, проверяет различные значения Y-координат ферзей. В каком месте программы задается порядок перебора альтернативных вариантов? Как можно без труда модифицировать программу, чтобы этот порядок изменился? Поэкспериментируйте с разными порядками, имея в виду выяснить, как порядок перебора альтернатив влияет на эффективность программы.
Упражнение
4. 7. Пусть поля доски представлены парами своих координат в виде X/Y, где как X, так и Y принимают значения от 1 до 8.
(а) Определите отношение ходконя( Поле1, Поле2), соответствующее ходу коня на шахматной доске. Считайте, что Поле1 имеет всегда конкретизированные координаты, в то время, как координаты поля Поле2 могут и не быть конкретизированы. Например:
?- ходконя( 1/1, S).
S = 3/2;
S = 2/3;
no (нет)
(b) Определите отношение путьконя( Путь), где Путь - список полей, представляющих соответствующую правилам игры последовательность ходов коня по пустой доске.
(с) Используя отношение путьконя, напишите вопрос для нахождения любого пути, состоящего из 4-х ходов, и начинающегося с поля 2/1, а заканчивающегося на противоположном крае доски (Y= 8). Этот путь должен еще проходить после второго хода через поле 5/4.
Посмотреть ответ
в возрасте родителей которых составляет
Упражнения
4. 1. Напишите вопросы для поиска в базе данных о семьях.
(а) семей без детей;
(b) всех работающих детей;
(с) семей, где жена работает, а муж нет,
(d) всех детей, разница в возрасте родителей которых составляет не менее 15 лет.
Посмотреть ответ
4. 2. Определите отношение
близнецы( Ребенок1, Ребенок2)
для поиска всех близнецов в базе данных о семьях.
Посмотреть ответ
Упражнения
4. 4. Почему не могло возникнуть зацикливание модели исходного автомата на Рисунок 4.3, когда в его графе переходов не было "спонтанного цикла"?
Посмотреть ответ
4. 5. Зацикливание при вычислении допускается можно предотвратить, например, таким способом: подсчитывать число переходов, сделанных к настоящему моменту. При этом модель должна будет искать пути только некоторой ограниченной длины. Модифицируйте так отношение допускается. Указание: добавьте третий аргумент - максимально допустимое число переходов:
допускается( Состояние, Цепочка, Макс_переходов)
Посмотреть ответ
что произойдет, если задать следующий
5. 1. 1. Эксперимент 1
Проанализируем, что произойдет, если задать следующий вопрос:
?- f( 1, Y), 2 < Y.
5. 1. 2. Эксперимент 2
Проделаем теперь еще один эксперимент со второй версией нашей программы. Предположим, мы задаем вопрос:
?- f( 7, Y).
Y = 4
Проанализируем, что произошло. Перед тем, как был получен ответ, система пробовала применить все три правила. Эти попытки породили следующую последовательность целей:
Попытка применить правило 1:
7 < 3 терпит неудачу, происходит возврат, и попытка применить правило 2 (точка отсечения достигнута не была)
Попытка применить правило 2:
3 <= 7 успех, но 7 < 6 терпит неудачу; возврат и попытка применить правило 3 (точка отсечения снова не достигнута)
Попытка применить правило 3:
6 <= 7 - успех
Приведенные этапы вычисления обнаруживают еще один источник неэффективности. В начале выясняется, что X < 3 не является истиной (7 < 3 терпит неудачу). Следующая цель - 3 =< Х (3 <= 7- успех). Но нам известно, что, если первая проверка неуспешна, то вторая обязательно будет успешной, так как второе целевое утверждение является отрицанием первого. Следовательно, вторая проверка лишняя и соответствующую цель можно опустить. То же самое верно и для цели 6 =< Х в правиле 3. Все эти соображения приводят к следующей, более экономной формулировке наших трех правил:
если Х < 3, то Y = 0
иначе, если 3 <= X и Х < 6, то Y = 2,
иначе Y = 4.
Теперь мы можем опустить в нашей программе те условия, которые обязательно выполняются при любом вычислении. Получается третья версия программы:
f( X, 0) :- X < 3, !.
f( X, 2) :- X < 6, !.
f( X, 4).
Эта программа дает тот же результат, что и исходная, но более эффективна, чем обе предыдущие. Однако, что будет, если мы теперь удалим отсечения? Программа станет такой:
f( X, 0) :- X < 3.
f( X, 2) :- X < 6.
f( X, 4).
Она может порождать различные решения, часть из которых неверны. Например:
?- f( 1, Y).
Y = 0;
Y = 2;
Y = 4;
nо (нет)
Важно заметить, что в последней версии, в отличие от предыдущей, отсечения затрагивают не только процедурное поведение, но изменяют также и декларативный смысл программы.
Более точный смысл механизма отсечений можно сформулировать следующим образом:
line(); Назовем "целью-родителем" ту цель, которая сопоставилась с головой предложения, содержащего отсечение. Когда в качестве цели встречается отсечение, такая цель сразу же считается успешной и при этом заставляет систему принять те альтернативы, которые были выбраны с момента активизации цели-родителя до момента, когда встретилось отсечение. Все оставшиеся в этом промежутке (от цели-родителя до отсечения) альтернативы не рассматриваются.
line(); Чтобы прояснить смысл этого определения, рассмотрим предложение вида
Н :- В1, В2, ..., Вm, !, ..., Вn.
Будем считать, что это предложение активизировалось, когда некоторая цель G сопоставилась с Н. Тогда G является целью-родителем. В момент, когда встретилось отсечение, успех уже наступил в целях В1, ..., Вm. При выполнении отсечения это (текущее) решение В1, ..., Вm "замораживается" и все возможные оставшиеся альтернативы больше не рассматриваются. Далее, цель G связывается теперь с этим предложением: любая попытка сопоставить G с головой какого-либо другого предложения пресекается.
Применим эти правила к следующему примеру:
С :- Р, Q, R, !, S, Т, U.
С :- V.
А :- В, С, D.
?- А.
Здесь А, В, С, D, Р и т.д. имеют синтаксис термов. Отсечение повлияет на вычисление цели С следующим образом. Перебор будет возможен в списке целей Р, Q, R; однако, как только точка отсечения будет достигнута, все альтернативные решения для этого списка изымаются из рассмотрения. Альтернативное предложение, входящее в С:
С :- V.
также не будет учитываться. Тем не менее, перебор будет возможен в списке целей S, Т, U. "Цель-родитель" предложения, содержащего отсечения, -это цель С в предложении
А :- В, С, D.
Поэтому отсечение повлияет только на цель С. С другой стороны, оно будет "невидимо" из цели А. Таким образом, автоматический перебор все равно будет происходить в списке целей В, С, D, вне зависимости от наличия отсечения в предложении, которое используется для достижения С.
Ограничение перебора
5. 1. Ограничение перебора
В процессе достижения цели пролог-система осуществляет автоматический перебор вариантов, делая возврат при неуспехе какого-либо из них. Такой перебор - полезный программный механизм, поскольку он освобождает пользователя от необходимости программировать его самому. С другой стороны, ничем не ограниченный перебор может стать источником
Вычисление максимума
5. 2. 1. Вычисление максимума
Процедуру нахождения наибольшего из двух чисел можно запрограммировать в виде отношения
mах( X, Y, Мах)
где Мах = X, если Х больше или равен Y, и Мах есть Y, если Х меньше Y. Это соответствует двум таким предложениям:
mах( X, Y, X) :- Х >= Y.
max( X, Y, Y) :- Х < Y.
Эти правила являются взаимно исключающими. Если выполняется первое, второе обязательно потерпит неудачу. Если неудачу терпит первое, второе обязательно должно выполниться. Поэтому возможна более экономная формулировка, использующая понятие "иначе":
если Х >= Y, то Мах = X,
иначе Мах = Y.
На Прологе это записывается при помощи отсечения:
mах( X, Y, X) :- Х >= Y, !.
mах( X, Y, Y).
Процедура проверки принадлежности списку дающая единственное решение
5. 2. 2. Процедура проверки принадлежности списку, дающая единственное решение
Для того, чтобы узнать, принадлежит ли Х списку L, мы пользовались отношением
принадлежит( X, L)
Программа была следующей:
принадлежит( X, [X | L] ).
принадлежит X, [Y | L] ) :- принадлежит( X, L).
Эта программа дает "недетерминированный" ответ: если Х встречается в списке несколько раз, то будет найдено каждое его вхождение. Исправить этот недостаток не трудно: нужно только предотвратить дальнейший перебор сразу же после того, как будет найден первый X, а это произойдет, как только в первом предложении наступит успех. Измененная программа выглядит так:
принадлежит( X, [X | L] ) :- !.
принадлежит( X, [Y | L] ) :- принадлежит( X, L).
Эта программа породит только одно решение. Например:
?- принадлежит( X, [а, b, с] ).
Х = а;
nо
(нет)
Добавление элемента к списку если он в нем отсутствует (добавление без дублирования)
5. 2. 3. Добавление элемента к списку, если он в нем отсутствует (добавление без дублирования)
Часто требуется добавлять элемент Х в список L только в том случае, когда в списке еще нет такого элемента. Если же Х уже есть в L, тогда L необходимо оставить без изменения, поскольку нам не нужны лишние дубликаты X. Отношение добавить имеет три аргумента:
добавить( X, L, L1)
где Х - элемент, который нужно добавить, L - список, в который его нужно добавить, L1 - результирующий новый список. Правила добавления можно сформулировать так:
если Х принадлежит к L, то L1 = L,
иначе L1 - это список L с добавленным к нему
элементом X.
Проще всего добавлять Х в начало списка L так, чтобы Х стал головой списка L1. Запрограммировать это можно так:
добавить( X, L, L) :- принадлежит( X, L), !.
добавить( X, L, [X | L] ).
Поведение этой процедуры можно проиллюстрировать следующим примером:
?- добавить( а, [b,с], L).
L = [a, b, c]
?- до6авить( X, [b, с], L).
L = [b, с]
Х = b
?- добавить( а, [b, с, X], L).
L = [b, с, а]
Х = а
Этот пример поучителен, поскольку мы не можем легко запрограммировать "недублирующее добавление", не используя отсечения или какой-либо другой конструкции, полученной из него. Если мы уберем отсечение в только что рассмотренной программе, то отношение добавить будет добавлять дубликаты элементов, уже имеющихся в списке. Например:
?- добавить( a, [a, b, c], L),
L = [а, b, с]
L = [а, а, b, с]
Поэтому отсечение требуется здесь для правильного определения отношения, а не только для повышения эффективности. Этот момент иллюстрируется также и следующим примером.
Задача классификации объектов
5. 2. 4. Задача классификации объектов
Предположим, что у нас есть база данных, содержащая результаты теннисных партий, сыгранных членами некоторого клуба. Подбор пар противников для каждой партия не подчинялся какой-либо системе, просто каждый игрок встречался с несколькими противниками. Результаты представлены в программе в виде фактов, таких как
победил( том, джон).
победил( энн, том).
победил( пат, джим).
Мы хотим определить
отношение класс( Игрок, Категория)
которое распределяет игроков по категориям. У нас будет три категории:
победитель - любой игрок, победивший во всех сыгранных им играх
боец - любой игрок, в некоторых играх победивший, а в некоторых проигравший
спортсмен - любой игрок, проигравший во всех сыгранных им партиях
Например, если в нашем распоряжении есть лишь приведенные выше результаты, то ясно, что Энн и Пат - победители. Том - боец и Джим - спортсмен.
Легко сформулировать правило для бойца:
Х - боец, если существует некоторый Y, такой, что Х победил
Y, и
существует некоторый Z, такой, что Z победил
X.
Теперь правило для победителя:
Х - победитель, если
X победил некоторого Y и
Х не был побежден никем.
Эта формулировка содержит отрицание "не", которое нельзя впрямую выразить при помощи тех возможностей Пролога, которыми мы располагаем к настоящему моменту. Поэтому оказывается, что формулировка отношения победитель должна быть более хитрой. Та же проблема возникает и при формулировке правил для отношения спортсмен. Эту проблему можно обойти, объединив определения отношений победитель и боец и использовав связку "иначе". Вот такая формулировка:
Если Х победил кого-либо и Х был кем-то
побежден,
то Х - боец,
иначе, если Х победил кого-либо,
то Х - победитель,
иначе, если Х был кем-то побежден,
то Х - спортсмен.
Такую формулировку можно сразу перевести на Пролог. Взаимные исключения трех альтернативных категорий выражаются при помощи отсечений:
класс( X, боец) :-
победил( X, _ ),
победил( _, X), !.
класс( X, победитель) :-
победил( X, _ ), !.
класс( X, спортсмен) :-
победил( _, X).
Заметьте, что использование отсечения в предложении для категории победитель не обязательно, что связано с особенностями наших трех классов.
Примеры использующие отсечение
5. 2. Примеры, использующие отсечение
Отрицание как неуспех
5. 3. Отрицание как неуспех
"Мэри любит всех животных, кроме змей". Как выразить это на Прологе? Одну часть этого утверждения выразить легко: "Мэри любит всякого X, если Х - животное". На Прологе это записывается так:
любит( мэри, X) :- животное ( X).
Но нужно исключить змей. Это можно сделать, использовав другую формулировку:
Если Х - змея, то "Мэри любит X" - не есть
истина,
иначе, если Х - животное, то Мэри любит X.
Сказать на Прологе, что что-то не есть истина, можно при помощи специальной цели fail (неуспех), которая всегда терпит неудачу, заставляя потерпеть неудачу и ту цель, которая является ее родителем. Вышеуказанная формулировка, переведенная на Пролог с использованием fail, выглядит так:
любит( мэри, X) :-
змея( X), !, fail.
любит( Мэри, X) :-
животное ( X).
Здесь первое правило позаботится о змеях: если Х - змея, то отсечение предотвратит перебор (исключая таким образом второе правило из рассмотрения), а fail вызовет неуспех. Эти два предложения можно более компактно записать в виде одного:
любит( мэри, X) :-
змея( X), !, fail;
животное ( X).
Ту же идею можно использовать для определения отношения
различны( X, Y)
которое выполняется, если Х и Y не совпадают. При этом, однако, мы должны быть точными, потому что "различны" можно понимать по-разному: Х и Y не совпадают буквально; Х и Y не сопоставимы; значения арифметических выражений Х и Y не равны.
Давайте считать в данном случае, что Х и Y различны, если они не сопоставимы. Вот способ выразить это на Прологе:
Если Х и Y сопоставимы, то
цель различны( X, Y) терпит неуспех
иначе цель различны( X, Y) успешна.
Мы снова используем сочетание отсечения и fail:
различны( X, X) :- !, fail.
различны( X, Y).
То же самое можно записать и в виде одного предложения:
различны( X, Y) :-
Х = Y, !, fail;
true.
Здесь true - цель, которая всегда успешна.
Эти примеры показывают, что полезно иметь унарный предикат "not" (не), такой, что
nоt( Цель)
истинна, если Цель не истинна. Определим теперь отношение not следующим образом:
Если Цель
успешна, то not( Цель) неуспешна,
иначе not( Цель)
успешна.
Это определение может быть записано на Прологе так:
not( Р) :-
P, !, fail;
true.
Начиная с этого момента мы будем предполагать, что not - это встроенная прологовская процедура, которая ведет себя так, как это только что было определено. Будем также предполагать, что оператор not определен как префиксный, так что цель
not( змея( X) )
можно записывать и как
not змея( X)
Многие версии Пролога поддерживают такую запись. Если же приходится иметь дело с версией, в которой нет встроенного оператора not, его всегда можно определить самим.
Следует заметить, что not, как он здесь определен с использованием неуспеха, не полностью соответствует отрицанию в математической логике. Эта разница может породить неожиданности в поведении программы, если оператором not пользоваться небрежно. Этот вопрос будет рассмотрен в данной главе позже.
Тем не менее not - полезное средство, и его часто можно с выгодой применять вместо отсечения. Наши два примера можно переписать с not:
любит( мэри, X) :-
животное ( X),
not змея( X).
различны( X, Y) :-
not( Х = Y).
Это, конечно, выглядит лучше, нежели наши прежние формулировки. Вид предложений стал более естественным, и программу стало легче читать.
Нашу программу теннисной классификации из предыдущего раздела можно переписать с использованием not так, чтобы ее вид был ближе к исходным определениям наших трех категорий:
класс( X, боец) :-
победил( X, _ ),
победил( _, X).
класс( X, победитель) :-
победил( X, _ ),
not победил( _, X).
класс( X, спортсмен) :-
not победил( X, _ ).
В качестве еще одного примера использования not рассмотрим еще раз программу 1 для решения задачи о восьми ферзях из предыдущей главы (Рисунок 4.7). Мы определили там отношение небьет между некоторым ферзем и остальными ферзями. Это отношение можно определить также и как отрицание отношения "бьет". На Рисунок 5.3 приводится соответствующим образом измененная программа.
Трудности с отсечением и отрицанием
5. 4. Трудности с отсечением и отрицанием
Используя отсечение, мы кое-что выиграли, но не совсем даром. Преимущества и недостатки применения отсечения были показаны на примерах из предыдущих разделов. Давайте подытожим сначала преимущества:
(1) При помощи отсечения часто можно повысить эффективность программы. Идея состоит в том, чтобы прямо сказать пролог-системе: не пробуй остальные альтернативы, так как они все равно обречены на неудачу.
(2) Применяя отсечение, можно описать взаимоисключающие правила, поэтому есть возможность запрограммировать утверждение:
если условие Р, то
решение Q,
иначе решение R
Выразительность языка при этом повышается.
Ограничения на использование отсечения проистекают из того, что есть опасность потерять такое важное для нас соответствие между декларативным и процедурным смыслами программы. Если в программе нет отсечений, то мы можем менять местами порядок предложений и целей, что повлияет только на ее эффективность, но не на декларативный смысл. Если же отсечения в ней присутствуют, то изменение порядка предложений может повлиять на ее декларативный смысл. Это значит, что программа с измененным порядком, возможно, будет давать результаты, отличные от результатов исходной программы. Вот пример, демонстрирующий этот факт:
р :- а, b.
р :- с.
Декларативный смысл программы: р истинно тогда и только тогда, когда истинны одновременно и а, и b или истинно с. Это можно записать в виде такой логической формулы:
р <===> (а & b) U с
Можно поменять порядок этих двух предложений, но декларативный смысл останется прежним. Введем теперь отсечение
p :- а, !, b.
р :- с.
Декларативный смысл станет теперь таким:
р <===> (а & b) U ( ~а & с)
Если предложения поменять местами
р :- с.
р :- а, !, b.
декларативный смысл станет таким:
р <===> с U ( а & b)
Важным моментом здесь является то, что при использовании отсечения требуется уделять больше внимания процедурным аспектам. К несчастью, эта дополнительная трудность повышает вероятность ошибок программирования.
В наших примерах из предыдущего раздела мы видели, что удаление отсечений из программы может привести к изменению ее декларативного смысла. Но были также в такие случаи, когда отсечение на него не влияло. Использование отсечений последнего типа требует меньшей осторожности, и поэтому такие отсечения иногда называют "зелеными отсечениями". С точки зрения наглядности программы такие отсечения "невинны" и их использование вполне приемлемо. При чтении программы их можно просто игнорировать.
Напротив, отсечения, влияющие на декларативный смысл, называются "красными". Красные отсечения -это такие отсечения, которые делают программу трудной для понимания, и их нужно применять с особой осторожностью.
Отсечение часто используется в комбинации со специальной целью fail. В частности, мы определили отрицание какой-либо цели (not), как ее неуспех. Определенное таким образом отрицание представляет собой просто особый (более ограниченный) вид отсечения. Из соображений ясности программ мы предпочтем пользоваться not вместо комбинации отсечение - неуспех (всюду, где возможно), поскольку отрицание является понятием более высокого уровня, чем отсечение - неуспех.
Следует заметить, что использование оператора not также может приводить к неприятностям, и его тоже следует применять с осторожностью. Трудность заключается в том, что тот оператор not, который был нами определен, не в точности соответствует отрицанию в математике. Если спросить
?- not человек( мэри).
система, возможно, ответит "да". Не следует понимать этот ответ как "мэри не человек". Что в действительности пролог-система хочет сказать своим "да", так это то, что программе не хватает информации для доказательства утверждения "Мэри - человек". Это происходит потому, что при обработке цели not система не пытается доказать истинность этой цели впрямую. Вместо этого она пытается доказать противоположное утверждение, и если такое противоположное утверждение доказать не удается, система считает, что цель not - успешна. Такое рассуждение основано на так называемом предположении о замкнутости мира. В соответствии с этим постулатом мир замкнут в том смысле, что все в нем существующее либо указано в программе, либо может быть из нее выведено. И наоборот - если что-либо не содержится в программе (или не может быть из нее выведено), то оно не истинно и, следовательно, истинно его отрицание. Это обстоятельство требует особого внимания, поскольку мы обычно не считаем мир замкнутым: если в программе явно не сказано, что
человек( мэри)
то мы этим обычно вовсе не хотим сказать, что Мэри не человек.
Дальнейшее изучение опасных аспектов использования not проведем на таком примере:
r( а).
g( b).
р( X) :- not r( X).
Если спросить теперь
?- g( X), р( Х).
система ответит
Х = b
Если же задать тот же вопрос, но в такой форме
?- р( X), g( X).
система ответит
nо (нет)
Читателю предлагается проследить работу программы по шагам, чтобы понять, почему получились разные ответы. Основная разница между вопросами состоит в том, что переменная Х к моменту вычисления р( X) в первом случае была уже конкретизирована, в то время как во втором случае этого еще не произошло.
Мы детально обсудили аспекты применения отсечения, которое неявно присутствует в not. При этом нами руководило желание предупредить пользователей о соблюдении необходимой осторожности, а вовсе не желание убедить их совсем не пользоваться этим оператором. Отсечение полезно, а часто и необходимо. А что касается трудностей Пролога, порождаемых отсечением, то подобные неудобства часто возникают и при программировании на других языках.
Литература
Литература
Различать "зеленые и "красные" отсечения предложил ван Эмден (1982).
van Emden M. (1982). Red and green cuts. Logic Programming Newsletter: 2.
Отсечение подавляет перебор. Его применяют
Резюме
Отсечение подавляет перебор. Его применяют как для повышения эффективности программ, так и для повышения выразительности языка. Эффективность повышается путем прямого указания (при помощи отсечения) пролог - системе не проверять альтернативы, про которые нам заранее известно, что они должны потерпеть неудачу. Отсечение дает возможность сформулировать взаимно исключающие утверждения при помощи правил вида:
если Условие то Утверждение1 иначе Утверждение2
Отсечение дает возможность ввести отрицание как неуспех: not( Цель) определяется через неуспех цели Цель. Иногда бывают полезными две особые цели true и fail. true - всегда успешна и fail - всегда терпит неудачу. Существуют ограничения в применении отсечения: его появление может нарушить, соответствие между декларативным и процедурным смыслами программы. Поэтому хороший стиль программирования предполагает осторожное применение отсечений и отказ от их применения без достаточных оснований. Оператор not, определенный через неуспех, не полностью соответствует отрицанию в математической логике. Поэтому not тоже нужно применять с осторожностью.
Двухступенчатая функция
Рисунок 5. 1. Двухступенчатая функция

неэффективности программы. Поэтому иногда требуется его ограничить или исключить вовсе. Для этого в Прологе предусмотрена конструкция "отсечение".
Давайте сначала рассмотрим простую программу, процесс вычислений, по которой содержит ненужный перебор. Мы выделим те точки этого процесса, где перебор бесполезен и ведет к неэффективности.
Рассмотрим двухступенчатую функцию, изображенную на Рисунок 5.1. Связь между Х и Y можно определить с помощью следующих трех правил:
Правило 1: если Х < 3, то Y = 0
Правило 2: если 3 <= X и Х < 6, то Y = 2
Правило 3: если 6 <= X, то Y = 4
На Прологе это можно выразите с помощью бинарного отношения
f( X, Y)
так:
f( X, 0) :- X < 3. % Правило 1
f( X, 2) :- 3 =< X, X < 6. % Правило 2
f( X, 4) :- 6 =< X. % Правило 3
В этой программе предполагается, конечно, что к моменту начала вычисления f( X, Y) Х уже конкретизирован каким-либо числом; это необходимо для выполнения операторов сравнения.
Мы проделаем с этой программой два эксперимента. Каждый из них обнаружит в ней свой источник неэффективности, и мы устраним оба этих источника по очереди, применив оператор отсечения.
В точке помеченной
Рисунок 5. 2. В точке, помеченной словом "ОТСЕЧЕНИЕ", уже известно,
что правила 2 и 3 должны потерпеть неудачу.
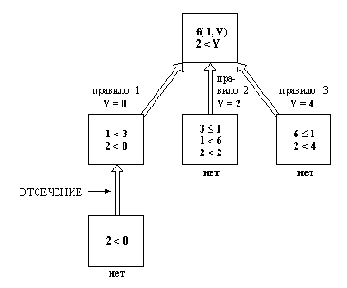
При вычислении первой цели f( l, Y) Y конкретизируется нулем. Поэтому вторая цель становится такой:
2 < 0
Она терпит неудачу, а поэтому и весь список целей также терпит неудачу. Это очевидно, однако перед тем как признать, что такому списку целей удовлетворить нельзя, пролог-система при помощи возвратов попытается проверить еще две бесполезные в данном случае альтернативы. Пошаговое описание процесса вычислений приводится на Рисунок 5.2.
Три правила, входящие в отношение f, являются взаимоисключающими, поэтому успех возможен самое большее в одном из них. Следовательно, мы (но не пролог-система) знаем, что, как только успех наступил в одном из них, нет смысла проверять остальные, поскольку они все равно обречены на неудачу. В примере, приведенном на Рисунок 5.2, о том, что в правиле 1 наступил успех, становится известно в точке, обозначенной словом "ОТСЕЧЕНИЕ". Для предотвращения бессмысленного перебора мы должны явно указать пролог-системе, что не нужно осуществлять возврат из этой точки. Мы можем сделать это при помощи конструкции отсечения. "Отсечение" записывается в виде символа '!', который вставляется между целями и играет роль некоторой псевдоцели. Вот наша программа, переписанная с использованием отсечения:
f( X, 0) :- X < 3, !.
f( X, 2) :- 3 =< X, X < 6, !.
f( X, 4) :- 6 =< X.
Символ '!' предотвращает возврат из тех точек программы, в которых он поставлен. Если мы теперь спросим
?- f( 1, Y), 2 < Y.
то пролог-система породит левую ветвь дерева, изображенного на Рисунок 5.2. Эта ветвь потерпит неудачу на цели 2 < 0. Система попытается сделать возврат, но вернуться она сможет не далее точки, помеченной в программе символом '!' . Альтернативные ветви, соответствующие правилу 2 и правилу 3, порождены не будут.
Новая программа, снабженная отсечениями, во всех случаях более эффективна, чем первая версия, в которой они отсутствуют. Неудачные варианты новая программа распознает всегда быстрее, чем старая.
Вывод: добавив отсечения, мы повысили эффективность. Если их теперь убрать, программа породит тот же результат, только на его получение она истратит скорее всего больше времени. Можно сказать, что в нашем случае после введения отсечений мы изменили только процедурный смысл программы, оставив при этом ее декларативный смысл в неприкосновенности. В дальнейшем мы покажем, что использование отсечения может также затронуть и декларативный смысл программы.
Еще одна программа для решения задачи о восьми ферзях
Рисунок 5. 3. Еще одна программа для решения задачи о восьми ферзях.
разность( Множ1, Множ2, Разность)
где все три множества представлены в виде списков. Например,
разность( [a, b, c, d], [b, d, e, f], [a, c] )
5. 6. Определите предикат
унифицируемые( Спис1, Терм, Спис2)
где Спис2 - список всех элементов Спис1, которые сопоставимы с Терм'ом, но не конкретизируются таким сопоставлением. Например:
?- унифицируемые( [X, b, t( Y)], t( a), Спис).
Спис = [ X, t( Y)]
Заметьте, что и Х и Y должны остаться неконкретизированными, хотя сопоставление с t( a) вызывает их конкретизацию. Указание: используйте not ( Терм1 = Терм2). Если цель Терм1 = Терм2 будет успешна, то not( Терм1 = Tepм2) потерпит неудачу и получившаяся конкретизация будет отменена!
Следующие отношения распределяют числа на
Упражнения
5. 1. Пусть есть программа:
р( 1).
р( 2) :- !.
р( 3).
Напишите все ответы пролог-системы на следующие вопросы:
(a) ?- р( X).
(b) ?- р( X), p(Y).
(c) ?- р( X), !, p(Y).
Посмотреть ответ
5. 2. Следующие отношения распределяют числа на три класса - положительные, нуль и отрицательные:
класс( Число, положительные) :- Число > 0.
класс( 0, нуль).
класс( Число, отрицательные) :- Число < 0.
Сделайте эту процедуру более эффективной при помощи отсечений.
Посмотреть ответ
5. 3. Определите процедуру
разбить( Числа, Положительные, Отрицательные)
которая разбивает список чисел на два списка: список, содержащий положительные числа (и нуль), и список отрицательных чисел. Например,
разбить( [3, -1, 0, 5, -2], [3, 0, 5], [-1, -2] )
Предложите две версии: одну с отсечением, другую - без.
Посмотреть ответ
Упражнения
5. 4. Даны два списка Кандидаты и Исключенные, напишите последовательность целей (используя принадлежит и not), которая, при помощи перебора, найдет все элементы списка Кандидаты, не входящие в список Исключенные.
Посмотреть ответ
5.5. Определите отношение, выполняющее вычитание множеств:
line(); решение( [ ]).
решение( [X/Y | Остальные] ) :-
решение( Остальные),
принадлежит( Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
not бьет( X/Y, Остальные).
бьет( X/Y, Остальные) :-
принадлежит( X1/Y1, Остальные),
( Y1 = Y;
Y1 is Y + X1 - X;
Y1 is Y - X1 + X ).
принадлежит( А, [А | L] ).
принадлежит( А, [В | L] ) :-
принадлежит( А, L).
% Шаблон решения
шаблон( [1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]).
line();