Больцмановское обучение
Этот стохастический метод непосредственно применим к обучению искусственных нейронных сетей:
Определить переменную

Если изменение веса приводит к увеличению целевой функции, то вероятность сохранения этого изменения вычисляется с помощью распределения Больцмана:

где



Выбирается случайное число

Для завершения больцмановского обучения повторяют шаги 3 и 4 для каждого из весов сети, постепенно уменьшая температуру
Величина случайного изменения веса на шаге 3 может определяться различными способами. Например, подобно тепловой системе, весовое изменение


где


Так как требуется величина изменения веса

Найти кумулятивную вероятность, соответствующую
Свойства машины Больцмана широко изучены. Скорость уменьшения температуры должна быть обратно пропорциональна логарифму времени, чтобы была достигнута сходимость к глобальному минимуму. Скорость охлаждения в такой системе выражается следующим образом:

где



Этот разочаровывающий результат предсказывает очень медленную скорость охлаждения (и вычислений). Вывод подтвержден и экспериментально. Машины Больцмана часто требуют для обучения очень большого ресурса времени.
Использование обучения
Искусственная нейронная сеть обучается с помощью некоторого процесса, модифицирующего ее веса. Если обучение успешно, то предъявление сети множества входных сигналов приводит к появлению желаемого множества выходных сигналов. Имеется два класса обучающих методов: детерминистский и стохастический.
Детерминистский метод обучения шаг за шагом осуществляет процедуру коррекции весов сети, основанную на использовании их текущих значений, а также величин входов, фактических выходов и желаемых выходов. Обучение персептрона является примером подобного детерминистского метода.
Стохастические методы обучения выполняют псевдослучайные изменения величин весов, сохраняя те изменения, которые ведут к улучшениям. Чтобы показать это наглядно, рассмотрим рис. 7.1, на котором изображена типичная сеть, где нейроны соединены с помощью весов. Выход нейрона является здесь взвешенной суммой его входов, которая преобразована с помощью нелинейной функции. Для обучения сети могут быть использованы следующие процедуры:
Выбрать вес случайным образом и подкорректировать его на небольшое случайное число. Предъявить множество входов и вычислить получающиеся выходы.Сравнить эти выходы с желаемыми выходами и вычислить величину разности между ними. Общепринятый метод состоит в нахождении разности между фактическим и желаемым выходами для каждого элемента обучаемой пары, возведение разностей в квадрат и нахождение суммы этих квадратов. Целью обучения является минимизация этой разности, часто называемой целевой функцией.Выбрать вес случайным образом и подкорректировать его на небольшое случайное значение. Если коррекция помогает (уменьшает целевую функцию), то сохранить ее, в противном случае вернуться к первоначальному значению веса.Повторять шаги с 1 по 3 до тех пор, пока сеть не будет обучена в достаточной степени.
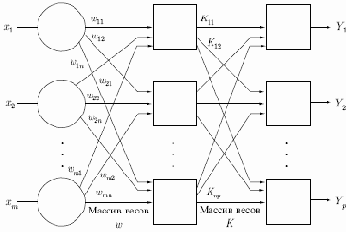
Рис. 7.1.
Этот процесс стремится минимизировать целевую функцию, но может попасть, как в ловушку, в неудачное решение. На рис. 7.2 показано, как это может происходить в системе с единственным весом.
Допустим, что первоначально вес взят равным значению в точке


будут часто посещаться, но то же самое будет верно и для каждой другой точки. Вес будет меняться так резко, что он никогда не установится в желаемом минимуме.
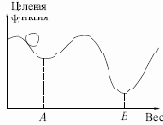
Рис. 7.2.
Таким образом, окончательно шарик остановится в точке глобального минимума, когда амплитуда встряхивания уменьшится до нуля.
Искусственные нейронные сети могут обучаться, по существу, тем же способом при помощи случайной коррекции весов. Вначале делаются большие случайные коррекции с сохранением только тех изменений весов, которые уменьшают целевую функцию. Затем средний размер шага постепенно уменьшается, и глобальный минимум в конце концов достигается.
Эта процедура весьма напоминает отжиг металла, поэтому для ее описания часто используют термин "имитация отжига". В металле, который нагрет до температуры, превышающей его точку плавления, атомы находятся в сильном беспорядочном движении. Как и во всех физических системах, атомы стремятся к состоянию минимума энергии (единому кристаллу, в данном случае), но при высоких температурах энергия атомных движений препятствует этому. В процессе постепенного охлаждения металла возникают все более низкоэнергетические состояния, пока, в конце концов, не будет достигнуто самое малое из возможных состояний, глобальный минимум. В процессе отжига распределение энергетических уровней описывается следующим соотношением:

где


При высоких температурах
Экспериментальные результаты
Комбинированный алгоритм, использующий обратное распространение и обучение Коши, применялся для обучения нескольких больших сетей. Например, этим методом была успешно обучена система, распознающая рукописные китайские иероглифы. Все же время обучения оказалось отнюдь не маленьким (было потрачено приблизительно 36 часов машинного времени).
В другом эксперименте эта сеть обучалась на задаче ИСКЛЮЧАЮЩЕЕ ИЛИ, которая была использована в качестве теста для сравнения с другими алгоритмами. Для сходимости сети в среднем требовалось около 76 предъявлений обучающего множества. В качестве сравнения можно указать, что при использовании обратного распространения в среднем требовалось около 245 предъявлений для решения этой же задачи и 4986 итераций при использовании обратного распространения второго порядка.
Ни одно из обучений не привело к локальному минимуму. Более того, ни одно из 160 обучений не обнаружило неожиданных патологий, сеть всегда правильно обучалась.
Эксперименты же с чистой машиной Коши потребовали значительно большх времен обучения. Например, при

Несмотря на такие обнадеживающие результаты, метод еще не исследован до конца, особенно на больших задачах. Значительно большая работа потребуется для определения его достоинств и недостатков.
Метод искусственной теплоемкости
Несмотря на улучшение, достигаемое с помощью метода Коши, время обучения может оказаться все еще слишком большим. Для дальнейшего ускорения этого процесса может быть использован способ, уходящий своими корнями в термодинамику. В этом методе скорость уменьшения температуры изменяется в соответствии с искусственной "теплоемкостью", вычисляемой в процессе обучения.
Во время отжига металла происходят фазовые переходы, связанные с дискретными изменениями уровней энергии. При каждом фазовом переходе может происходить резкое изменение величины, называемой теплоемкостью. Теплоемкость определяется как скорость изменения температуры в зависимости от изменения энергии. Изменения теплоемкости происходят из-за попадания системы в локальные энергетические минимумы.
Искусственные нейронные сети проходят аналогичные фазы в процессе обучения. На границе фазового перехода искусственная теплоемкость может скачкообразно измениться. Эта псевдотеплоемкость определяется как средняя скорость изменения температуры с целевой функцией. В примере шарика в коробке, приведенном выше, сильная начальная встряска делает среднюю величину целевой функции фактически не зависящей от малых изменений температуры, т. е. теплоемкость близка к константе. Аналогично, при очень низких температурах система замерзает в точке минимума, так что теплоемкость снова близка к константе. Ясно, что в каждой из этих областей допустимы сильные изменения температуры, так как не происходит улучшения целевой функции.
При критической температуре небольшое уменьшение ее значения приводит к большому изменению средней величины целевой функции. Возвращаясь к аналогии с шариком, при "температуре", когда шарик обладает достаточной средней энергией, чтобы перейти из
Обратное распространение и обучение Коши
Обратное распространение обладает преимуществом прямого поиска, т.е. веса всегда корректируются в направлении, минимизирующем функцию ошибки. Хотя время обучения и велико, оно существенно меньше, чем при случайном поиске, выполняемом машиной Коши, когда отыскивается глобальный минимум, но многие шаги выполняются в неверном направлении и "съедают" много времени.
Соединение этих двух методов дало хорошие результаты. Коррекция весов, равная сумме, вычисленной алгоритмом обратного распространения, и случайный шаг, задаваемый алгоритмом Коши, приводят к системе, которая сходится и находит глобальный минимум быстрее, чем система, обучаемая каждым из методов в отдельности. Простая эвристика используется для избежания паралича сети, который может возникнуть как при обратном распространении, так и при обучении по методу Коши.
Обучение Коши
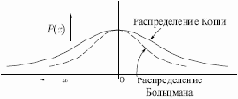
Рис. 7.3.
В этом методе при вычислении величины шага распределение Больцмана заменяется на распределение Коши. Распределение Коши имеет, как показано на рис. 7.3, более длинные "хвосты", увеличивая тем самым вероятность больших шагов. В действительности, распределение Коши имеет бесконечную (неопределенную) дисперсию. С помощью такого простого изменения максимальная скорость уменьшения температуры становится обратно пропорциональной линейной величине, а не логарифму, как для алгоритма обучения Больцмана. Это резко уменьшает время обучения. Зависимость может быть выражена следующим образом:

Распределение Коши имеет вид

где


В данном уравнении

где


Теперь применение метода Монте-Карло становится очень простым. Для нахождения x в этом случае выбирается случайное число из равномерного распределения на открытом интервале

Трудности с алгоритмом обучения Коши
Несмотря на улучшение скорости обучения, даваемое машиной Коши по сравнению с машиной Больцмана, время сходимости все еще может в 100 раз превышать время для алгоритма обратного распространения. Отметим, что сетевой паралич особенно опасен для алгоритма обучения Коши, в особенности для сети с нелинейностью типа логистической функции. Бесконечная дисперсия распределения Коши приводит к изменениям весов до неограниченных величин. Далее, большие изменения весов будут иногда приниматься даже в тех случаях, когда они неблагоприятны, часто приводя к сильному насыщению сетевых нейронов с вытекающим отсюда риском паралича.
Комбинирование обратного распространения с shape обучением Коши. Коррекция весов в комбинированном алгоритме, использующем обратное распространение и обучение Коши, состоит из двух компонент: (1) направленной компоненты, вычисляемой с использованием алгоритма обратного распространения, и (2) случайной компоненты, определяемой распределением Коши. Эти компоненты вычисляются для каждого веса, и их сумма является величиной, на которую изменяется вес. Как и в алгоритме Коши, после вычисления изменения веса вычисляется целевая функция. Если происходит улучшение, изменение сохраняется безусловно. В противном случае, оно сохраняется с вероятностью, определяемой распределением Больцмана. Коррекция веса вычисляется с использованием представленных ранее уравнений для каждого из алгоритмов:

где

Таким образом, имеется конечная вероятность того, что ухудшающее множество приращений весов будет сохранено. Так как распределение Коши имеет бесконечную дисперсию (диапазон изменения тангенса простирается от


Очевидное решение, состоящее в ограничении диапазона изменения весовых шагов, ставит вопрос о математической корректности полученного таким образом алгоритма. На сегодняшний день доказана сходимость системы к глобальному минимуму лишь для исходного алгоритма. Подобного доказательства при искусственном ограничении размера шага не существует. В действительности экспериментально выявлены случаи, когда для реализации некоторой функции требуются большие веса и два больших веса, вычитаясь, дают малую разность.
Другое решение состоит в рандомизации весов тех нейронов, которые оказались в состоянии насыщения. Его недостаток в том, что оно может серьезно нарушить обучающий процесс, иногда затягивая его до бесконечности.
Для решения проблемы паралича был найден метод, не нарушающий достигнутого обучения. Насыщенные нейроны выявляются с помощью измерения их сигналов OUT. Когда величина OUT приближается к своему предельному значению, положительному или отрицательному, на веса, питающие этот нейрон, действует сжимающая функция. Она подобна используемой для получения нейронного сигнала OUT, за исключением того, что диапазоном ее изменения является интервал


Эта функция заметно уменьшает величину очень больших весов, воздействие на малые веса значительно более слабое. Далее, она поддерживает симметрию, сохраняя небольшие различия между большими весами. Экспериментально было показано, что эта функция выводит нейроны из состояния насыщения без нарушения достигнутого в сети обучения. Не было затрачено серьезных усилий для оптимизации используемой функции, и другие значения констант могут оказаться лучшими.
Трудности, связанные с обратным распространением
Несмотря на богатые возможности, продемонстрированные методом обратного распространения, при его применении возникает ряд трудностей, часть из которых, однако, облегчается благодаря использованию нового алгоритма.
Сходимость. Д.Е.Румелхарт доказал сходимость на языке дифференциальных уравнений в частных производных. Таким образом, доказательство справедливо лишь в том случае, когда коррекция весов выполняется с помощью бесконечно малых шагов. Это условие ведет к бесконечному времени сходимости, и тем самым метод теряет силу в практических применениях. В действительности нет доказательства, что обратное распространение будет сходиться при конечном размере шага. Эксперименты показывают, что сети обычно обучаются, но время обучения велико и непредсказуемо.
Локальные минимумы. В обратном распространении для коррекции весов сети используется градиентный спуск, продвигающийся к минимуму в соответствии с локальным наклоном поверхности ошибки. Он хорошо работает в случае сильно изрезанных невыпуклых поверхностей, которые встречаются в практических задачах. В одних случаях локальный минимум является приемлемым решением, в других случаях он неприемлем.
Даже после того как сеть обучена, невозможно сказать, найден ли с помощью обратного распространения глобальный минимум. Если решение неудовлетворительно, приходится давать весам новые начальные случайные значения и повторно обучать сеть без гарантии, что обучение закончится на этой попытке или что глобальный минимум вообще будет когда-либо найден.
Паралич. При некоторых условиях сеть может при обучении попасть в такое состояние, когда модификация весов не ведет к действительным изменениям сети. Такой "паралич сети" является серьезной проблемой: один раз возникнув, он может увеличить время обучения на несколько порядков.
Паралич возникает, когда значительная часть нейронов получает веса достаточно большие, чтобы дать большие значения NET. В результате величина OUT приближается к своему предельному значению, а производная от сжимающей функции приближается к нулю. Как мы видели, алгоритм обратного распространения при вычислении величины изменения веса использует эту производную в формуле в качестве коэффициента. Для пораженных параличом нейронов близость производной к нулю приводит к тому, что изменение веса становится близким к нулю.
Если подобные условия возникают во многих нейронах сети, то обучение может замедлиться до почти полной остановки.
Нет теории, способной предсказывать, будет ли сеть парализована во время обучения или нет. Экспериментально установлено, что малые размеры шага реже приводят к параличу, но шаг, малый для одной задачи, может оказаться большим для другой. Цена же паралича может быть высокой. При моделировании многие часы машинного времени могут уйти на то, чтобы выйти из паралича.