Что такое Data Mining?
"За последние годы, когда, стремясь к повышению эффективности и прибыльности бизнеса, при создании БД все стали пользоваться средствами обработки цифровой информации, появился и побочный продукт этой активности - горы собранных данных: И вот все больше распространяется идея о том, что эти горы полны золота".
В прошлом процесс добычи золота в горной промышленности состоял из выбора участка земли и дальнейшего ее просеивания большое количество раз. Иногда искатель находил несколько ценных самородков или мог натолкнуться на золотоносную жилу, но в большинстве случаев он вообще ничего не находил и шел дальше к другому многообещающему месту или же вовсе бросал добывать золото, считая это занятие напрасной тратой времени.
Сегодня появились новые научные методы и специализированные инструменты, сделавшие горную промышленность намного более точной и производительной. Data Mining для данных развилась почти таким же способом. Старые методы, применявшиеся математиками и статистиками, отнимали много времени, чтобы в результате получить конструктивную и полезную информацию.
Сегодня на рынке представлено множество инструментов, включающих различные методы, которые делают Data Mining прибыльным делом, все более доступным для большинства компаний.
Термин Data Mining получил свое название из двух понятий: поиска ценной информации в большой базе данных (data) и добычи горной руды (mining). Оба процесса требуют или просеивания огромного количества сырого материала, или разумного исследования и поиска искомых ценностей.
Термин Data Mining часто переводится как добыча данных, извлечение информации, раскопка данных, интеллектуальный анализ данных, средства поиска закономерностей, извлечение знаний, анализ шаблонов, "извлечение зерен знаний из гор данных", раскопка знаний в базах данных, информационная проходка данных, "промывание" данных. Понятие "обнаружение знаний в базах данных" (Knowledge Discovery in Databases, KDD) можно считать синонимом Data Mining [1].
Понятие Data Mining, появившееся в 1978 году, приобрело высокую популярность в современной трактовке примерно с первой половины 1990-х годов. До этого времени обработка и анализ данных осуществлялся в рамках прикладной статистики, при этом в основном решались задачи обработки небольших баз данных.
О популярности Data Mining говорит и тот факт, что результат поиска термина "Data Mining" в поисковой системе Google (на сентябрь 2005 года) - более 18 миллионов страниц.
Что же такое Data Mining?
Data Mining - мультидисциплинарная область, возникшая и развивающаяся на базе таких наук как прикладная статистика, распознавание образов, искусственный интеллект, теория баз данных и др., см. рис. 1.1.
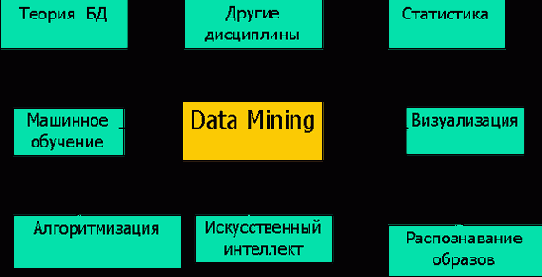
Рис. 1.1. Data Mining как мультидисциплинарная область
Приведем краткое описание некоторых дисциплин, на стыке которых появилась технология Data Mining.
Классификация аналитических систем
Агентство Gartner Group, занимающееся анализом рынков информационных технологий, в 1980-х годах ввело термин "Business Intelligence" (BI), деловой интеллект или бизнес-интеллект. Этот термин предложен для описания различных концепций и методов, которые улучшают бизнес решения путем использования систем поддержки принятия решений.
В 1996 году агентство уточнило определение данного термина.
Business Intelligence - программные средства, функционирующие в рамках предприятия и обеспечивающие функции доступа и анализа информации, которая находится в хранилище данных, а также обеспечивающие принятие правильных и обоснованных управленческих решений.
Понятие BI объединяет в себе различные средства и технологии анализа и обработки данных масштаба предприятия.
На основе этих средств создаются BI-системы, цель которых - повысить качество информации для принятия управленческих решений.
BI-системы также известны под названием Систем Поддержки Принятия Решений (СППР, DSS, Decision Support System). Эти системы превращают данные в информацию, на основе которой можно принимать решения, т.е. поддерживающую принятие решений.
Gartner Group определяет состав рынка систем Business Intelligence как набор программных продуктов следующих классов:
средства построения хранилищ данных (data warehousing, ХД); системы оперативной аналитической обработки (OLAP);информационно-аналитические системы (Enterprise Information Systems, EIS);средства интеллектуального анализа данных (data mining);инструменты для выполнения запросов и построения отчетов (query and reporting tools).Классификация Gartner базируется на методе функциональных задач, где программные продукты каждого класса выполняют определенный набор функций или операций с использованием специальных технологий.
Мнение экспертов о Data Mining
Приведем несколько кратких цитат [4] наиболее влиятельных членов бизнес-сообществ, которые являются экспертами в этой относительно новой технологии.
Руководство по приобретению продуктов Data Mining (Enterprise Data Mining Buying Guide) компании Aberdeen Group: "Data Mining - технология добычи полезной информации из баз данных. Однако в связи с существенными различиями между инструментами, опытом и финансовым состоянием поставщиков продуктов, предприятиям необходимо тщательно оценивать предполагаемых разработчиков Data Mining и партнеров.
Чтобы максимально использовать мощность масштабируемых инструментов Data Mining коммерческого уровня, предприятию необходимо выбрать, очистить и преобразовать данные, иногда интегрировать информацию, добытую из внешних источников, и установить специальную среду для работы Data Mining алгоритмов.
Результаты Data Mining в большой мере зависят от уровня подготовки данных, а не от "чудесных возможностей" некоего алгоритма или набора алгоритмов. Около 75% работы над Data Mining состоит в сборе данных, который совершается еще до того, как запускаются сами инструменты. Неграмотно применив некоторые инструменты, предприятие может бессмысленно растратить свой потенциал, а иногда и миллионы долларов".
Мнение Херба Эдельштайна (Herb Edelstein), известного в мире эксперта в области Data Mining, Хранилищ данных и CRM: "Недавнее исследование компании Two Crows показало, что Data Mining находится все еще на ранней стадии развития. Многие организации интересуются этой технологией, но лишь некоторые активно внедряют такие проекты. Удалось выяснить еще один важный момент: процесс реализации Data Mining на практике оказывается более сложным, чем ожидается.
IT-команды увлеклись мифом о том, что средства Data Mining просты в использовании. Предполагается, что достаточно запустить такой инструмент на терабайтной базе данных, и моментально появится полезная информация. На самом деле, успешный Data Mining-проект требует понимания сути деятельности, знания данных и инструментов, а также процесса анализа данных".
Прежде чем использовать технологию Data Mining, необходимо тщательно проанализировать ее проблемы, ограничения и критические вопросы, с ней связанные, а также понять, чего эта технология не может.
Data Mining не может заменить аналитика
Технология не может дать ответы на те вопросы, которые не были заданы. Она не может заменить аналитика, а всего лишь дает ему мощный инструмент для облегчения и улучшения его работы.
Сложность разработки и эксплуатации приложения Data Mining
Поскольку данная технология является мультидисциплинарной областью, для разработки приложения, включающего Data Mining, необходимо задействовать специалистов из разных областей, а также обеспечить их качественное взаимодействие.
Квалификация пользователя
Различные инструменты Data Mining имеют различную степень "дружелюбности" интерфейса и требуют определенной квалификации пользователя. Поэтому программное обеспечение должно соответствовать уровню подготовки пользователя. Использование Data Mining должно быть неразрывно связано с повышением квалификации пользователя. Однако специалистов по Data Mining, которые бы хорошо разбирались в бизнесе, пока еще мало.
Извлечение полезных сведений невозможно без хорошего понимания сути данных
Необходим тщательный выбор модели и интерпретация зависимостей или шаблонов, которые обнаружены. Поэтому работа с такими средствами требует тесного сотрудничества между экспертом в предметной области и специалистом по инструментам Data Mining. Построенные модели должны быть грамотно интегрированы в бизнес-процессы для возможности оценки и обновления моделей. В последнее время системы Data Mining поставляются как часть технологии хранилищ данных.
Сложность подготовки данных
Успешный анализ требует качественной предобработки данных. По утверждению аналитиков и пользователей баз данных, процесс предобработки может занять до 80% процентов всего Data Mining-процесса.
Таким образом, чтобы технология работала на себя, потребуется много усилий и времени, которые уходят на предварительный анализ данных, выбор модели и ее корректировку.
Большой процент ложных, недостоверных или бессмысленных результатов
С помощью Data Mining можно отыскивать действительно очень ценную информацию, которая вскоре даст большие дивиденды в виде финансовой и конкурентной выгоды.
Однако Data Mining достаточно часто делает множество ложных и не имеющих смысла открытий. Многие специалисты утверждают, что Data Mining-средства могут выдавать огромное количество статистически недостоверных результатов. Чтобы этого избежать, необходима проверка адекватности полученных моделей на тестовых данных.
Высокая стоимость
Качественная Data Mining-программа может стоить достаточно дорого для компании. Вариантом служит приобретение уже готового решения с предварительной проверкой его использования, например на демо-версии с небольшой выборкой данных.
Наличие достаточного количества репрезентативных данных
Средства Data Mining, в отличие от статистических, теоретически не требуют наличия строго определенного количества ретроспективных данных. Эта особенность может стать причиной обнаружения недостоверных, ложных моделей и, как результат, принятия на их основе неверных решений. Необходимо осуществлять контроль статистической значимости обнаруженных знаний.
Отличия Data Mining от других методов анализа данных
Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы на проверку заранее сформулированных гипотез (verification-driven data mining) и на "грубый" разведочный анализ, составляющий основу оперативной аналитической обработки данных (OnLine Analytical Processing, OLAP), в то время как одно из основных положений Data Mining - поиск неочевидных закономерностей. Инструменты Data Mining могут находить такие закономерности самостоятельно и также самостоятельно строить гипотезы о взаимосвязях. Поскольку именно формулировка гипотезы относительно зависимостей является самой сложной задачей, преимущество Data Mining по сравнению с другими методами анализа является очевидным.
Большинство статистических методов для выявления взаимосвязей в данных используют концепцию усреднения по выборке, приводящую к операциям над несуществующими величинами, тогда как Data Mining оперирует реальными значениями.
OLAP больше подходит для понимания ретроспективных данных, Data Mining опирается на ретроспективные данные для получения ответов на вопросы о будущем.
Перспективы технологии Data Mining
Потенциал Data Mining дает "зеленый свет" для расширения границ применения технологии. Относительно перспектив Data Mining возможны следующие направления развития:
выделение типов предметных областей с соответствующими им эвристиками, формализация которых облегчит решение соответствующих задач Data Mining, относящихся к этим областям;создание формальных языков и логических средств, с помощью которых будет формализованы рассуждения и автоматизация которых станет инструментом решения задач Data Mining в конкретных предметных областях;создание методов Data Mining, способных не только извлекать из данных закономерности, но и формировать некие теории, опирающиеся на эмпирические данные;преодоление существенного отставания возможностей инструментальных средств Data Mining от теоретических достижений в этой области.Если рассматривать будущее Data Mining в краткосрочной перспективе, то очевидно, что развитие этой технологии наиболее направлено к областям, связанным с бизнесом.
В краткосрочной перспективе продукты Data Mining могут стать такими же обычными и необходимыми, как электронная почта, и, например, использоваться пользователями для поиска самых низких цен на определенный товар или наиболее дешевых билетов.
В долгосрочной перспективе будущее Data Mining является действительно захватывающим - это может быть поиск интеллектуальными агентами как новых видов лечения различных заболеваний, так и нового понимания природы вселенной.
Однако Data Mining таит в себе и потенциальную опасность - ведь все большее количество информации становится доступным через всемирную сеть, в том числе и сведения частного характера, и все больше знаний возможно добыть из нее:
Не так давно крупнейший онлайновый магазин "Amazon" оказался в центре скандала по поводу полученного им патента "Методы и системы помощи пользователям при покупке товаров", который представляет собой не что иное как очередной продукт Data Mining, предназначенный для сбора персональных данных о посетителях магазина.
Новая методика позволяет прогнозировать будущие запросы на основании фактов покупок, а также делать выводы об их назначении. Цель данной методики - то, о чем говорилось выше - получение как можно большего количества информации о клиентах, в том числе и частного характера (пол, возраст, предпочтения и т.д.). Таким образом, собираются данные о частной жизни покупателей магазина, а также членах их семей, включая детей. Последнее запрещено законодательством многих стран - сбор информации о несовершеннолетних возможен там только с разрешения родителей.
Исследования отмечают, что существуют как успешные решения, использующие Data Mining, так и неудачный опыт применения этой технологии [5]. Области, где применения технологии Data Mining, скорее всего, будут успешными, имеют такие особенности:
требуют решений, основанных на знаниях;имеют изменяющуюся окружающую среду;имеют доступные, достаточные и значимые данные;обеспечивают высокие дивиденды от правильных решений.
Понятие Data Mining
Data Mining - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации) [3].
Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро (Gregory Piatetsky-Shapiro) - один из основателей этого направления:
Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Суть и цель технологии Data Mining можно охарактеризовать так: это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидных - это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
Объективных - это значит, что обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным.
Практически полезных - это значит, что выводы имеют конкретное значение, которому можно найти практическое применение.
Знания - совокупность сведений, которая образует целостное описание, соответствующее некоторому уровню осведомленности об описываемом вопросе, предмете, проблеме и т.д.
Использование знаний (knowledge deployment) означает действительное применение найденных знаний для достижения конкретных преимуществ (например, в конкурентной борьбе за рынок).
Приведем еще несколько определений понятия Data Mining.
Data Mining - это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для использования.
Data Mining - это процесс выделения, исследования и моделирования больших объемов данных для обнаружения неизвестных до этого структур (patterns) с целью достижения преимуществ в бизнесе (определение SAS Institute).
Data Mining - это процесс, цель которого - обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов плюс применение статистических и математических методов (определение Gartner Group).
В основу технологии Data Mining положена концепция шаблонов (patterns), которые представляют собой закономерности, свойственные подвыборкам данных, кои могут быть выражены в форме, понятной человеку.
"Mining" по-английски означает "добыча полезных ископаемых", а поиск закономерностей в огромном количестве данных действительно сродни этому процессу.
Цель поиска закономерностей - представление данных в виде, отражающем искомые процессы. Построение моделей прогнозирования также является целью поиска закономерностей.
Понятие Искусственного интеллекта
Искусственный интеллект - научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования видов человеческой деятельности, традиционно считающихся интеллектуальными.
Термин интеллект (intelligence) происходит от латинского intellectus, что означает ум, рассудок, разум, мыслительные способности человека.
Соответственно, искусственный интеллект (AI, Artificial Intelligence) толкуется как свойство автоматических систем брать на себя отдельные функции интеллекта человека. Искусственным интеллектом называют свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека.
Каждое из направлений, сформировавших Data Mining, имеет свои особенности. Проведем сравнение с некоторыми из них.
Понятие Машинного обучения
Единого определения машинного обучения на сегодняшний день нет.
Машинное обучение можно охарактеризовать как процесс получения программой новых знаний. Митчелл в 1996 году дал такое определение: "Машинное обучение - это наука, которая изучает компьютерные алгоритмы, автоматически улучшающиеся во время работы".
Одним из наиболее популярных примеров алгоритма машинного обучения являются нейронные сети.
Понятие Статистики
Статистика - это наука о методах сбора данных, их обработки и анализа для выявления закономерностей, присущих изучаемому явлению.
Статистика является совокупностью методов планирования эксперимента, сбора данных, их представления и обобщения, а также анализа и получения выводов на основании этих данных.
Статистика оперирует данными, полученными в результате наблюдений либо экспериментов. Одна из последующих глав будет посвящена понятию данных.
Развитие технологии баз данных
1960-е гг.
В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM.
1970-е гг.
В 1975 году появился первый стандарт ассоциации по языкам систем обработки данных - Conference on Data System Languages (CODASYL), определивший ряд фундаментальных понятий в теории систем баз данных, которые до сих пор являются основополагающими для сетевой модели данных. В дальнейшее развитие теории баз данных большой вклад был сделан американским математиком Э.Ф. Коддом, который является создателем реляционной модели данных.
1980-е гг.
В течение этого периода многие исследователи экспериментировали с новым подходом в направлениях структуризации баз данных и обеспечения к ним доступа. Целью этих поисков было получение реляционных прототипов для более простого моделирования данных. В результате, в 1985 году был создан язык, названный SQL. На сегодняшний день практически все СУБД обеспечивают данный интерфейс.
1990-е гг.
Появились специфичные типы данных - "графический образ", "документ", "звук", "карта". Типы данных для времени, интервалов времени, символьных строк с двухбайтовым представлением символов были добавлены в язык SQL. Появились технологии DataMining, хранилища данных, мультимедийные базы данных и web-базы данных.
Возникновение и развитие Data Mining обусловлено различными факторами, основные среди которых являются следующие [2]:
совершенствование аппаратного и программного обеспечения; совершенствование технологий хранения и записи данных; накопление большого количества ретроспективных данных; совершенствование алгоритмов обработки информации.Сравнение статистики, машинного обучения и Data Mining
Статистика Более, чем Data Mining, базируется на теории.Более сосредотачивается на проверке гипотез.Машинное обучение Более эвристично.Концентрируется на улучшении работы агентов обучения.Data Mining. Интеграция теории и эвристик.Сконцентрирована на едином процессе анализа данных, включает очистку данных, обучение, интеграцию и визуализацию результатов.
Понятие Data Mining тесно связано с технологиями баз данных и понятием данные, которые будут подробно рассмотрены в следующей лекции.
Существующие подходы к анализу
Достаточно долго дисциплина Data Mining не признавалась полноценной самостоятельной областью анализа данных, иногда ее называют "задворками статистики" (Pregibon, 1997).
На сегодняшний день определилось несколько точек зрения на Data Mining. Сторонники одной из них считают его миражом, отвлекающим внимание от классического анализа данных. Сторонники другого направления - это те, кто принимает Data Mining как альтернативу традиционному подходу к анализу. Есть и середина, где рассматривается возможность совместного использования современных достижений в области Data Mining и классическом статистическом анализе данных.
Технология Data Mining постоянно развивается, привлекает к себе все больший интерес как со стороны научного мира, так и со стороны применения достижений технологии в бизнесе.
Ежегодно проводится множество научных и практических конференций, посвященных Data Mining, одна из которых - Международная конференция по Knowledge Discovery Data Mining (International Conferences on Knowledge Discovery and Data Mining).
Среди наиболее известных WWW-источников - сайт www.kdnuggets.com, который ведет один из основателей Data Mining Григорий Пиатецкий-Шапиро.
Периодические издания по Data Mining: Data Mining and Knowledge Discovery, KDD Explorations, ACM-TODS, IEEE-TKDE, JIIS, J. ACM, Machine Learning, Artificial Intelligence.
Материалы конференций: ACM-SIGKDD, IEEE-ICDM, SIAM-DM, PKDD, PAKDD, Machine learning (ICML), AAAI, IJCAI, COLT (Learning Theory).
