Особенности методологии моделирования с применением Cognos 4Thought
Инструментальное средство Cognos 4Thought (рис. 25.2) входит в состав семейства современных программных средств обработки, анализа и прогнозирования данных, разработанного компанией Cognos.
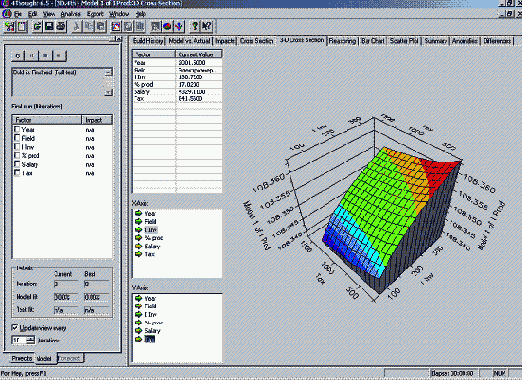
Рис. 25.2. Интерфейс инструментального средства Cognos 4Thought
В основу программного продукта Cognos 4Thought положена технология нейронных сетей. Использование нейронных сетей позволяет строить достаточно точные сложные нелинейные модели на основе неполной статистической выборки данных.
Cognos 4Thought предназначен для моделирования и прогнозирования. 4Thought может анализировать исторические данные во времени, затем продолжить эту временную линию в будущее, предсказывая тенденции.
На рис. 25.3 представлена типичная схема взаимодействия Cognos 4Thought с другими продуктами семейства, выполняющими подготовку данных для 4Thought.
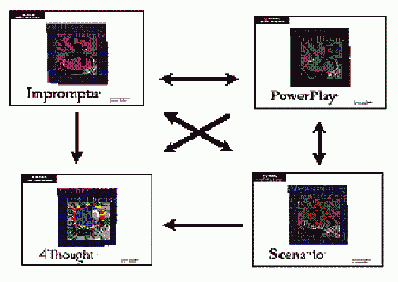
Рис. 25.3. Взаимодействие систем Impromptu, PowerPlay, Scenario и 4Thought
Системы Impromptu, PowerPlay, Scenario и 4Thought представляют собой взаимосвязанные и дополняющие друг друга инструментальные средства, поддерживающие наиболее эффективные технологии обработки данных и обеспечивающие решение широкого круга задач в бизнес-приложениях, от доступа к информации в распределенных базах данных до вычислительной обработки и интеллектуального анализа.
Cognos PowerPlay - это инструментальное средство для оперативного анализа данных и формирования отчетов по OLAP-технологии. Оно позволяет аналитикам исследовать данные под любым углом зрения, обеспечивая реальное многоуровневое видение текущего состояния организации. Главная особенность инструмента заключается в исключительной автоматизации процесса создания аналитического приложения, что позволяет за очень короткий срок создавать полномасштабные аналитические приложения, в основу которых положена технология OLAP.
Кроме того, инструмент отличается удобством применения: от пользователя требуются лишь навыки работы в среде Windows.
PowerPlay обеспечивает эффективный доступ ко всей имеющейся в организации информации, хранящейся в форме реляционных или не реляционных данных, таких как базы данных (Databases), склады данных (Data Warehouses), витрины данных (Data Marts) и электронные таблицы (Spreadsheets).
Созданный с помощью PowerPlay гиперкуб можно открыть в 4Thought. Гиперкуб представляет собой файл многомерных данных с расширением .mdc. Данные в таком файле организованы специальным образом для обеспечения быстрого доступа и детализации.
OLAP-кубы Cognos можно использовать как источники данных для модулей Data Mining (4Thought и Scenario), таким образом в продукции Cognos реализована интеграция технологий OLAP и Data Mining.
Cognos Impromptu - это инструмент фирмы Cognos для построения запросов любой сложности и отчетов произвольного формата пользователями, от которых не требуется навыков программирования. Отличительная черта этого средства - простота в использовании, которая достигается благодаря продуманному и интуитивно понятному интерфейсу.
Impromptu обеспечивает пользователей оперативной и детальной информацией, необходимой для принятия решений. Одним из основных достоинств Impromptu является возможность быстрого построения широкого спектра различных отчетов в зависимости от того, какие данные необходимы для принятия решения. Это означает, что пользователи могут формировать отчеты любой нужной структуры гораздо оперативнее и проще, чем при использовании других построителей отчетов.
Отчеты Impromptu также могут быть использованы в качестве входных данных для построения модели в Cognos 4Thought.
Cognos Scenario - это интеллектуальное инструментальное средство поиска (разведки) данных (Data Mining), которое позволяет руководителям (даже не знакомым с методиками статистического анализа) выявлять скрытые тенденции и модели бизнеса и "извлекать на поверхность" его ранее неизвестные закономерности и корреляционные связи.
Система Scenario спроектирована для построения моделей, описывающих особенности бизнеса по данным, которые при использовании традиционных методов анализа могли бы быть незамеченными. Удобный интерфейс этого приложения позволяет пользователям легко визуализировать имеющиеся сведения о бизнесе. Он автоматизирует обнаружение и ранжирование наиболее важных факторов, влияющих на бизнес, и выявление скрытых связей между этими факторами.
Обладая подобным интерфейсом, Scenario делает процесс анализа данных, традиционно трудоемкий и дорогостоящий, простым и оперативным.
Результаты работы Scenario (ключевые показатели и факторы) могут быть переданы в 4Thought для выполнения прогнозирования.
Cognos 4Thought использует технологии математического моделирования, которые позволяют изучить взаимную связь факторов, влияющих на выбранную сферу деятельности. Это программное средство дает возможность плановикам создавать точную модель бизнеса, используемую для сравнения, прогнозирования, интерпретации результатов измерений.
4Thought поддерживает анализ на всех этапах:
Сбор данных. Данные вводятся непосредственно или получаются из внешних источников, например, MS Excel. Данные могут быть взяты у других программных средств семейства Cognos (Impromptu, ReportNet, PowerPlay и Scenario) или прямо из хранилища. Введенные данные отображаются в 4Thought в виде электронных таблиц, что позволяет достаточно просто их просматривать и анализировать;Преобразование данных. Прежде чем попасть в модуль 4Thought, данные обычно очищаются в модуле Impromptu, который делает запросы к источникам данных (реляционным базам данных), позволяет накладывать фильтры на выборки данных (например, исключать строки, в которых значение показателя - целевой функции равно нулю, либо превращать одинаковые строки в одну строку, либо отсеивать строки если значение показателя является аномальным - выходит за пределы двух среднеквадратичных отклонений вверх и трех вниз, и т.п., правила очистки данных можно произвольно настраивать). Отчеты Impromptu могут быть использованы в качестве входных данных для построения модели в 4Thought. В модуле 4Thought также есть возможность просматривать данные и исключать аномалии (задавая допустимые интервалы, в которых может изменяться значение показателя), а также заменить пустые значения показателей на конкретные значения. При этом создаются новые поля: коэффициенты, пропорции, процентные соотношения, дающие более полную картину проблемы.
Исследование данных. Данные визуализируются для просмотра в виде электронных таблиц, графиков и диаграмм различного вида. Фактически, этот этап представляет собой предварительный просмотр данных перед построением модели в 4Thought (выявление аномалий, работа с дубликатами и пропусками).Создание модели. 4Thought создает модель автоматически, но позволяет детальную интерактивную настройку параметров модели; пользователь контролирует ряд параметров, включая выбор факторов (например исключение несущественных факторов), отсеивание аномальных значений и т.д.Интерпретация. После загрузки данных в модель 4Thought создает ряд отчетов и дает возможность работы с разнообразными графиками. Таким образом модель просматривается, проверяется достоверность полученных результатов, выявляются взаимозависимости факторов.Применение. Реализованная модель используется для прогнозирования и определения наиболее существенных факторов, задающих изменения ключевых показателей.4Thought позволяет выполнить обучение модели на репрезентативной выборке значений входных и выходных параметров нейронной сети. Для обучения может быть использована вся выборка либо ее часть - в таком случае оставшаяся часть выборки применяется для контроля точности (качества) обучения: отклонения значений выходов обученной нейронной сети от реальных значений. Обучение сети на одном наборе данных выполняется несколько раз (перед каждым обучением начальные значения весовых коэффициентов устанавливаются автоматически случайным образом), чтобы выбрать наилучшую точность обученной сети.
Cognos 4Thought позволяет, варьируя параметры сценарных условий, автоматически получать различные прогнозы на заданный период, отвечая на вопрос: "А что будет, если?" Результаты прогнозирования по всем отраслям региональной экономики можно получать в виде текстов, графиков, диаграмм, а также отчетных документов установленного образца, которые можно хранить в электронном виде или передавать потребителям по электронной почте.
Такие возможности освобождают аналитиков от рутинной вычислительной и оформительской работы и позволяют сосредоточиться на вопросах стратегии и тактики регионального развития.
Cognos 4Thought отображает степень влияния факторов (входных переменных) на целевую переменную, что позволяет использовать его в качестве инструмента факторного анализа. То есть после настройки сети можно оценить, какие факторы вносят какой вклад в конечный результат.
4Thought может оперировать с временными рядами. Это позволяет обнаруживать и анализировать тренды в динамике экономических величин, а также строить прогноз значений показателей на несколько лет вперед. 4Thought поддерживает несколько способов нормирования входных и выходных параметров, что дает возможность оперировать с экономическими величинами, влияние которых нелинейно.
При комплексном использовании продуктов семейства Cognos (рис. 25.3) в единой информационно-аналитической системе возникают дополнительные преимущества (синергетический эффект). Задачи по сбору и обработке информации в системе решаются на этапе формирования витрин данных с помощью инструмента PowerPlay Transformation Server.
Вопросы безопасности в системе (защиты от несанкционированного доступа) решаются с помощью инструмента Access Manager, входящего в состав пакета PowerPlay Transformation Server.
Инструменты PowerPlay и Impromptu используются для решения задач, связанных с мониторингом показателей, многомерным анализом информации, формированием отчетов, а инструменты 4Thought и Scenario - для прогнозирования показателей социально-экономического развития, а также для факторного анализа данных. Организация передачи данных между инструментами полностью автоматизирована. Простота интерфейса продуктов Cognos и ориентированность на пользователей-непрограммистов позволяет эффективно выполнять сложные задачи анализа. Публикация информации в интранет/экстранет-среде может осуществляться с помощью инструмента Upfront, входящего в состав пакета Cognos PowerPlay Enterprise Server.
Программные продукты Cognos и система STATISTICA Data Miner
Программные продукты Cognos (разработчик - компания Cognos [107]) - это инструменты интеллектуального или делового анализа данных (от англ. Business Intelligence Tools), или BI-инструменты. Представление о комплексе программных средств компании Cognos дает следующий рис. 25.1 [108].

Рис. 25.1. Комплекс программных средств компании Cognos
Ниже перечислены основные программные продукты Cognos, которые относятся к проблемным областям, указанным на рисунке.
Работа с запросами и отчетами. Решения в области работы с отчетами ориентированы на различные типы пользователей. Продукты отличаются требованиями к уровню сложности отчетов и уровню навыков конечных пользователей: Decision Stream - средство для создания витрин данных (data marts), оптимизированных на формирование запросов и построение отчетов;Impromptu - средство для работы с запросами, а также со статическими и настраиваемыми отчетами;PowerPlay - как средство построения многомерных отчетов;Impromptu Web Reports - средства для работы со статическими отчетами через Web;Cognos Query - средство для создания запросов, навигации и исследования данных в т.ч. через Web;Visualizer - средство для работы с мощными визуальными отчетами. Анализ данных. Средства анализа данных предназначены для анализа критической информации и выявления значимых факторов. Этот процесс охватывает полный набор аналитических задач и задач по построению отчетов, включая работу с отчетами бизнес-уровня, возможность перехода к данным нижнего уровня, создание и просмотр представлений с целью выявления приоритетов. Интеграция средств позволяет удобно переходить от исследования и анализа данных при помощи отчетов бизнес-уровня к исследованию и анализу данных по отчетам нижнего уровня (функция drill through): PowerPlay - средство многомерного (OLAP) анализа и построения бизнес-отчетов;Impromptu - средство для просмотра отчетов с детальной информацией нижнего уровня (для Windows);Impromptu Web Reports - средство для просмотра отчетов с детальной информацией нижнего уровня (для Web);Visualizer - средство визуального представления данных. Визуализация и выявление приоритетов.К разделу визуализации информации и выявлению приоритетов можно отнести целый спектр продуктов. С их помощью пользователю становится доступна визуализированная информация, представленная в удобном виде для выявления критических факторов на больших массивах данных. В этих продуктах за основу принимается возможность анализа ключевых факторов, влияющих на рассматриваемую область знаний (бизнеса) при помощи широких возможностей по визуализации данных. Правильно выявленные приоритеты являются основой для принятия эффективных решений: Visualizer - средство для представления информации в форме визуальных представлений с использованием визуальных элементов для выявления приоритетов;PowerPlay как средство многомерного представления информации;Impromptu как средство для работы с настраиваемыми отчетами;Cognos Query - средство Web-пользователей для построения запросов. Разведка данных (data mining). Средства разведки и добывания данных предлагают целый ряд возможностей по автоматизированному просмотру данных, позволяя вскрывать скрытые тенденции, выявлять приоритетные решения и действия путем отображения тех факторов, которые более других влияют на исследуемые показатели: Scenario - средство сегментации и классификации;4Thought - средство прогнозирования;Visualazer как средство визуализации. Защита информации. Защита информации достигается за счет использования единого для всех приложений компонента, называемого Access Manager и позволяющего описывать классы пользователей и управлять ими для всех типов аналитических приложений Cognos. В дополнение к Access Manager, могут быть использованы также обычные возможности обеспечения безопасности на уровне базы данных и операционной системы. На практике возможно одновременное использование всех трех уровней защиты информации; Описание метаданных. В качестве средства описания метаданных может быть использован единый для всех Cognos BI продуктов компонент, называемый Cognos Architect. Достоинство использования единого для всех средств модуля заключается в возможности единообразного представления бизнес-информации.Единожды сформулированные метаданные становятся доступными в любом аналитическом приложении Cognos.
Система STATISTICA Data Miner
Назначение. Система STATISTICA Data Miner (разработчик - компания StatSoft [109]) спроектирована и реализована как универсальное и всестороннее средство анализа данных - от взаимодействия с различными базами данных до создания готовых отчетов, реализующее так называемый графически-ориентированный подход [110, 111].
Система STATISTICA предлагает:
Большой набор готовых решений;Удобный пользовательский интерфейс, полностью интегрированный с MS Office;Мощные средства разведочного анализа;Полностью оптимизированный пакет для работы с огромным объемом информации;Гибкий механизм управления;Многозадачность системы;Чрезвычайно быстрое и эффективное развертывание;Открытая COM-архитектура, неограниченные возможности автоматизации и поддержки пользовательских приложений (использование промышленного стандарта Visual Basic (является встроенным языком), Java, C/C++).Сердцем STATISTICA Data Miner является браузер процедур Data Mining (рис. 25.4), который содержит более 300 основных процедур, специально оптимизированных под задачи Data Mining, средства логической связи между ними и управления потоками данных, что позволит Вам конструировать собственные аналитические методы.
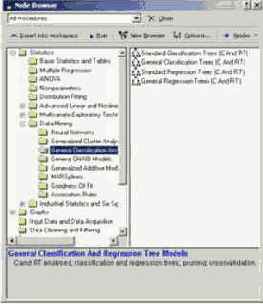
Рис. 25.4. Браузер процедур Data Mining
Рабочее пространство STATISTICA Data Miner состоит из четырех основных частей (рис. 25.5):

Рис. 25.5. Рабочее пространство STATISTICA Data MinerData Acquisition - сбор данных. В данной части пользователь идентифицирует источник данных для анализа, будь то файл данных или запрос из базы данных. Data Preparation, Cleaning, Transformation - подготовка, преобразования и очистка данных. Здесь данные преобразуются, фильтруются, группируются и т.д. Data Analysis, Modeling, Classification, Forecasting - анализ данных, моделирование, классификация, прогнозирование. Здесь пользователь может при помощи браузера или готовых моделей задать необходимые виды анализа данных, таких как прогнозирование, классификация, моделирование и т.д. Reports - результаты. В данной части пользователь может просмотреть, задать вид и настроить результаты анализа (например, рабочая книга, отчет или электронная таблица).
Средства анализа STATISTICA Data Miner
Средства анализа STATISTICA Data Miner можно разделить на пять основных классов:
General Slicer/Dicer and Drill-Down Explorer - разметка/разбиение и углубленный анализ. Набор процедур, позволяющий разбивать, группировать переменные, вычислять описательные статистики, строить исследовательские графики и т.д. General Classifier - классификация. STATISTICA Data Miner включает в себя полный пакет процедур классификации: обобщенные линейные модели, деревья классификации, регрессионные деревья, кластерный анализ и т.д.General Modeler/Multivariate Explorer - обобщенные линейные, нелинейные и регрессионные модели. Данный элемент содержит линейные, нелинейные, обобщенные регрессионные модели и элементы анализа деревьев классификации. General Forecaster - прогнозирование. Включает в себя модели АРПСС, сезонные модели АРПСС, экспоненциальное сглаживание, спектральный анализ Фурье, сезонная декомпозиция, прогнозирование при помощи нейронных сетей и т.д. General Neural Networks Explorer - нейросетевой анализ. В данной части содержится наиболее полный пакет процедур нейросетевого анализа.Приведенные выше элементы являются комбинацией модулей других продуктов StatSoft. Кроме них, STATISTICA Data Miner содержит набор специализированных процедур Data Mining, которые дополняют линейку инструментов Data Mining:
Feature Selection and Variable Filtering (for very large data sets) - специальная выборка и фильтрация данных (для больших объемов данных). Данный модуль автоматически выбирает подмножества переменных из заданного файла данных для последующего анализа. Например, модуль может обработать около миллиона входных переменных с целью определения предикторов для регрессии или классификации. Association Rules - правила ассоциации. Модуль является реализацией так называемого априорного алгоритма обнаружения правил ассоциации. Например, результат работы этого алгоритма мог бы быть следующим: клиент после покупки продукт "А", в 95 случаях из 100 в течение следующих двух недель после этого заказывает продукт "B" или "С". Interactive Drill-Down Explorer - интерактивный углубленный анализ. Представляет собой набор средств для гибкого исследования больших наборов данных. На первом шаге вы задаете набор переменных для углубленного анализа данных, на каждом последующем шаге выбираете необходимую подгруппу данных для последующего анализа.Generalized EM & k-Means Cluster Analysis - обобщенный метод максимума среднего и кластеризация методом К средних. Данный модуль - это расширение методов кластерного анализа. Он предназначен для обработки больших наборов данных и позволяет кластеризовывать как непрерывные, так и категориальные переменные, обеспечивает все необходимые функциональные возможности для распознавания образов.Generalized Additive Models (GAM) - обобщенные аддитивные модели (GAM). Набор методов, разработанных и популяризованных Hastie и Tibshirani.General Classification and Regression Trees (GTrees) - обобщенные классификационные и регрессионные деревья (GTrees). Модуль является полной реализацией методов, разработанных Breiman, Friedman, Olshen и Stone (1984). Кроме этого, модуль содержит разного рода доработки и дополнения, такие как оптимизации алгоритмов для больших объемов данных и т.д. Модуль является набором методов обобщенной классификации и регрессионных деревьев. General CHAID (Chi-square Automatic Interaction Detection) Models - обобщенные CHAID-модели (Хи-квадрат автоматическое обнаружение взаимодействия). Подобно предыдущему элементу, этот модуль является оптимизацией данной математической модели для больших объемов данных. Interactive Classification and Regression Trees - интерактивная классификация и регрессионные деревья. В дополнение к модулям автоматического построения разного рода деревьев, STATISTICA Data Miner также включает средства для формирования таких деревьев в интерактивном режиме. Boosted Trees - расширяемые простые деревья. Последние исследования аналитических алгоритмов показывают, что для некоторых задач построения "сложных" оценок, прогнозов и классификаций использование последовательно увеличиваемых простых деревьев дает более точные результаты, чем нейронные сети или сложные цельные деревья. Данный модуль реализует алгоритм построения простых увеличиваемых (расширяемых) деревьев. Multivariate Adaptive Regression Splines (Mar Splines) - многомерные адаптивные регрессионные сплайны (Mar Splines). Данный модуль основан на реализации методики предложенной Friedman (1991; Multivariate Adaptive Regression Splines, Annals of Statistics, 19, 1-141); в STATISTICA Data Miner расширены опции MARSPLINES для того, чтобы приспособить задачи регрессии и классификации к непрерывным и категориальным предикторам.Модуль МАР-сплайны предназначен для обработки как категориальных, так и непрерывных переменных вне зависимости от того, являются ли они предикторами или переменными отклика. В случае категориальных переменных отклика, модуль МАР-сплайны рассматривает текущую задачу как задачу классификации. Напротив, если зависимые переменные непрерывны, то задача расценивается как регрессионная. Модуль МАР-сплайны автоматически определяет тип задачи.
МАР-сплайны - непараметрическая процедура, в работе которой не используется никаких предполжений об общем виде функциональных связей между зависимыми и независимыми переменными. Процедура устанавливает зависимости по набору коэффициентов и базисных функций, которые полностью определяются из исходных данных. В некотором смысле, метод основан на принципе "разделяй и властвуй", в соответствии с которым пространство значений входных переменных разбивается на области со своими собственными уравнениями регрессии или классификации. Это делает использование МАР-сплайнов особенно эффективным для задач с пространствами значений входных переменных высокой размерности.
Метод МАР-сплайнов нашел особенно много применений в области добычи данных по причине того, что он не опирается на предположения о типе и не накладывает ограничений на класс зависимостей (например, линейных, логистических и т.п.) между предикторными и зависимыми (выходными) переменными. Таким образом, метод позволяет получить содержательные модели (т.е. модели, дающие весьма точные предсказания) даже в тех случаях, когда связи между предикторными и зависимыми переменными имеют немонотонный характер и сложны для приближения параметрическими моделями.
Goodness of Fit Computations - критерии согласия. Данный модуль производит вычисления различных статистических критериев согласия как для непрерывных переменных, так и для категориальных. Rapid Deployment of Predictive Models - быстрые прогнозирующие модели (для большого числа наблюдаемых значений). Модуль позволяет строить за короткое время классификационные и прогнозирующие модели для большого объема данных. Полученные результаты могут быть непосредственно сохранены во внешней базе данных.Несложно заметить, что система STATISTICA включает огромный набор различных аналитических процедур, и это делает его недоступным для обычных пользователей, которые слабо разбираются в методах анализа данных. Компанией StatSoft предложен вариант работы для обычных пользователей, обладающих небольшими опытом и знаниями в анализе данных и математической статистике.
Для этого, кроме общих методов анализа, были встроены готовые законченные (сконструированные) модули анализа данных, предназначенные для решения наиболее важных и популярных задач: прогнозирования, классификации, создания правил ассоциации и т.д.
Далее кратко описана схема работы в Data Miner.
Шаг 1. Работу в Data Miner начнем с подменю "Добыча данных" в меню "Анализ" (рис. 25.6). Выбрав пункт "Добытчик данных - Мои процедуры" или "Добытчик данных - Все процедуры", мы запустим рабочую среду STATISTICA Data Mining.

Рис. 25.6. Пункт "Добытчик данных"
Шаг 2. Для примера возьмем файл Boston2.sta из папки примеров STATISTICA. В следующем примере анализируются данные о жилищном строительстве в Бостоне. Цена участка под застройку классифицируется как Низкая - Low, Средняя - Medium или Высокая - High в зависимости от значения зависимой переменной Price. Имеется один категориальный предиктор - Cat1 и 12 порядковых предикторов - Ord1-Ord12. Весь набор данных, состоящий из 1012 наблюдений, содержится в файле примеров Boston2.sta. Выбор таблицы показан на рис. 25.7.
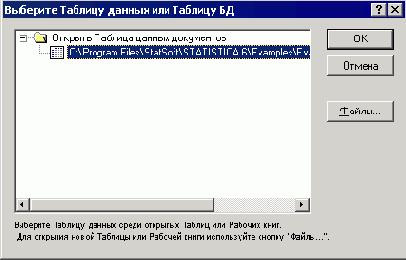
Рис. 25.7. Выбор таблицы для анализа
Шаг 3. После выбора файла появится окно диалога "Выберите зависимые переменные и предикторы", показанное на рис. 25.8.
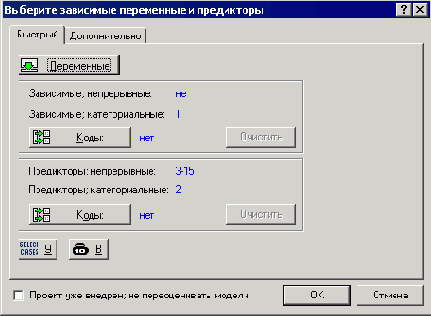
Рис. 25.8. Выбор зависимых переменных и предикторов
Выбираем зависимые переменные (непрерывные и категориальные) и предикторы (непрерывные и категориальные), исходя из знаний о структуре данных, описанной выше. Нажимаем OK.
Шаг 4. Запускаем "Диспетчер узлов" (нажимаем на кнопку

в окне Data Miner). В данном диалоге, показанном на рис. 25.9, мы можем выбрать вид анализа или задать операцию преобразования данных.
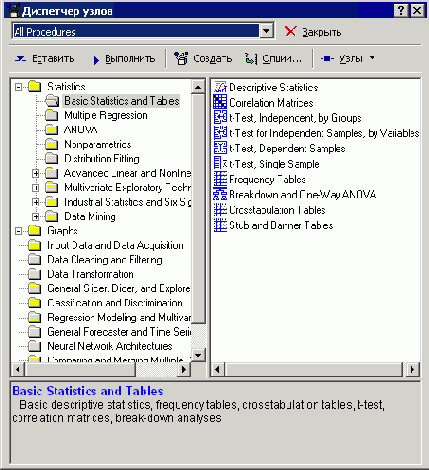
Рис. 25.9. "Диспетчер узлов"
Диспетчер узлов включает в себя все доступные процедуры для добычи данных. Всего доступно около 260 методов фильтрации и очистки данных, методов анализа. По умолчанию, процедуры помещены в папки и отсортированы в соответствии с типом анализа, который они выполняют. Однако пользователь имеет возможность создать собственную конфигурацию сортировки методов.
Для того чтобы выбрать необходимый анализ, необходимо выделить его на правой панели и нажать кнопку "вставить". В нижней части диалога дается описание выбираемых методов.
Выберем, для примера, Descriptive Statistics и Standard Classification Trees with Deployment (C And RT) . Окно Data Miner выглядит следующим образом.
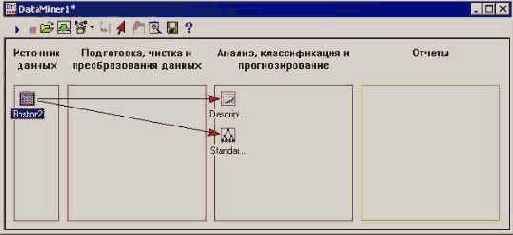
Рис. 25.10. Окно Data Miner с узлами выбранных анализов
Источник данных в рабочей области Data Miner автоматически будет соединен с узлами выбранных анализов. Операции создания/удаления связей можно производить и вручную.
Шаг 5. Теперь выполним проект. Все узлы, соединенные с источниками данных активными стрелками, будут проведены.
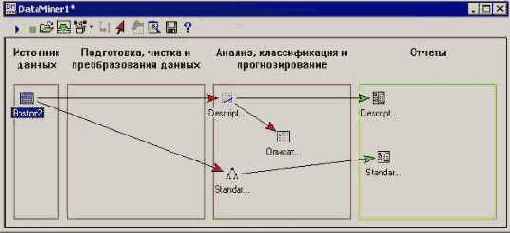
Рис. 25.11. Окно Data Miner после выполнения проекта
Далее можно просмотреть результаты (в столбце отчетов). Подробные отчеты создаются по умолчанию для каждого вида анализа. Для рабочих книг результатов доступна полная функциональность системы STATISTICA.
Шаг 6. На следующем шаге просматриваем результаты, редактируем параметры анализа.
Кроме того, в диспетчере узлов STATISTICA Data Miner содержатся разнообразные процедуры для классификации и Дискриминантного анализа, Регрессионных моделей и Многомерного анализа, а также Обобщенные временные ряды и прогнозирование. Все эти инструменты можно использовать для проведения сложного анализа в автоматическом режиме, а также для оценивания качества модели.
